【MySQL】存储过程/参数验证/函数
2023-12-13 11:37:25
存储过程是什么?
- 不会在应用代码里写SQL语句,原因如下:
- 会让应用代码混乱且难以维护,比如不会把SQL和java代码混在一起写
- java需要编译,如果把SQL和java写在一起的话,要修改SQL代码时必须重新编译才行。
- 把SQL代码储存在应属的数据库中,即存储过程
- 存储过程:是一个包含一堆SQL代码的数据库对象。在应用代码里,通过调用这些过程来获取或保存数据。使用存储过程来存储和管理SQL代码。
- 存储过程的优势:
- 可以对存储过程里的代码做一些优化,所以存储过程里的SQL代码有时候可以执行得更快
- 能加强数据安全性。比如:可以取消对所有表的直接访问权限,并让插入、更新或删除数据的操作由存储过程来完成,指定能执行特定存储过程的某人,这样会限制用户对数据的操作范围,比如可以防止一些用户删除数据。
创建存储过程:creat procedure…begin…end
- begin和end关键字之间的内容是存储过程的主体
修改默认分隔符:dilimiter
- 注意:主体中的代码需要用分号分隔,即使只有一句查询,也需要有分号。那此时就要更改默认分隔符了。
- 更改默认分隔符:delimiter,国际惯例通常用 $ $ 。在end后再用上$ $ ,表示两次$$之间的内容是一个整体。最后再用dilimiter把分隔符换成原来的分号。
delimiter $$
create procedure get_clients()
begin
select * from clients;
end$$
delimiter ;
运行结果:此时生成了一个对应名字的存储过程。
调用存储过程:call
call get_clients()
运行结果:调用了存储过程中的sql语句

删除存储过程:drop procesure if exists
-
将已有的存储过程删除后,继续执行删除操作的话会报错。
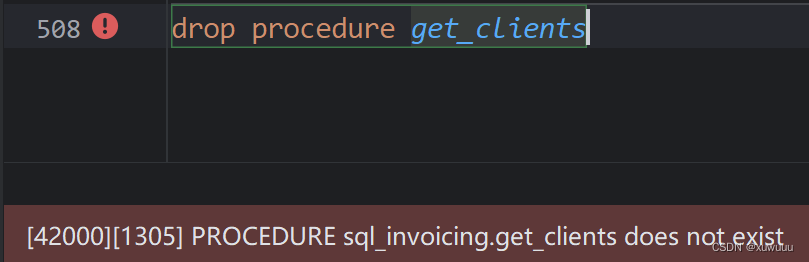
-
因此可把删除存储过程的语句改成:drop procedure if exists,这样删除一个不存在的存储过程时不会报错,更安全。
练习
- 创建存储过程,获取发票结余大于0的数据
- 可以使用视图
delimiter $$
create procedure get_invoices_with_balance()
begin
select *
from invoices_with_balance
where balance > 0;
end$$
delimiter ;
运行结果:
- 调用刚创建的存储过程
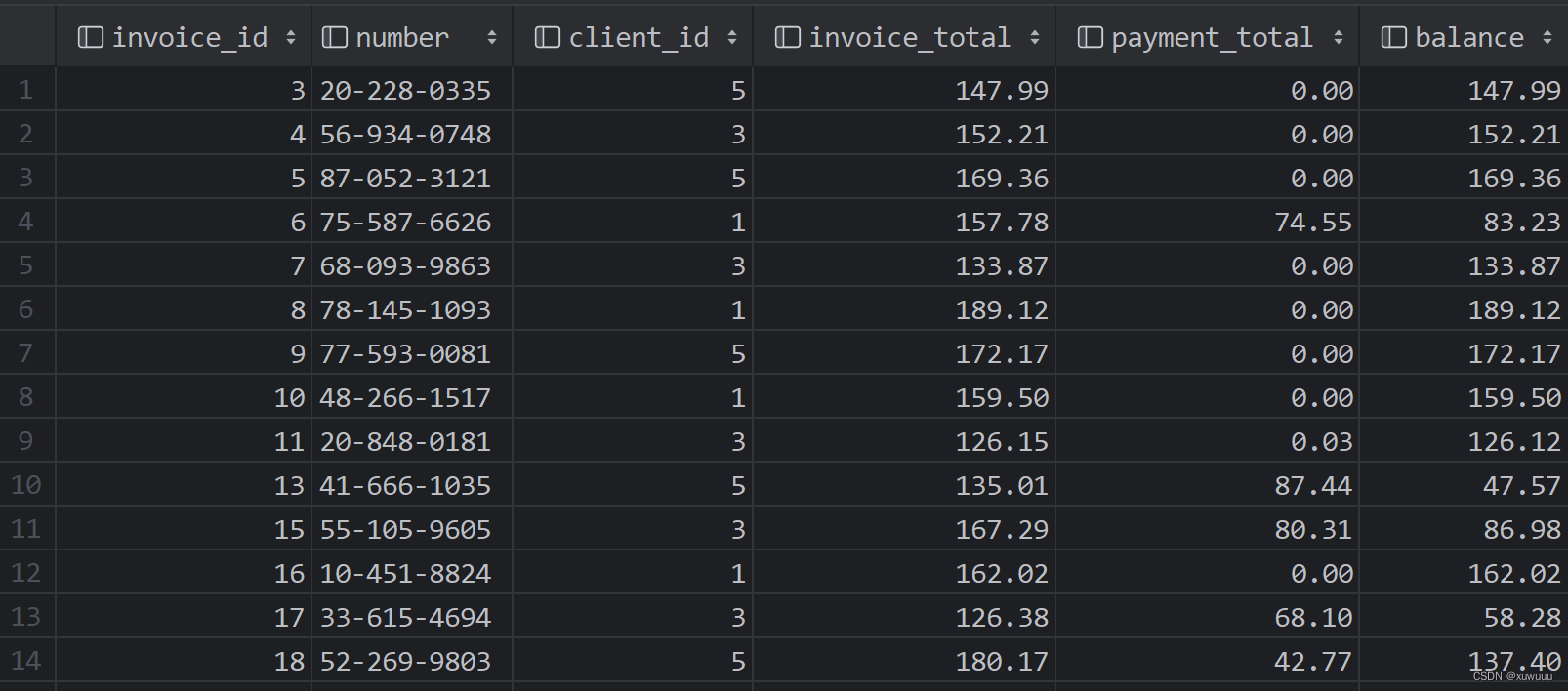
call get_invoices_with_balance()
运行结果:
存储过程中添加参数:(形参 数据类型)
- 使用参数为存储过程传递值
示例
- 使用参数为存储过程传递值
- 通过存储过程获取位于某个州的客户
- 存储过程中传入参数,(列名 数据类型)
- 字符数据类型通常用varchar,还有int,char等
- 调用存储过程时,需要传入参数调用。如果不传参数会报错。
drop procedure if exists get_clients_by_state;
delimiter $$
create procedure get_clients_by_state
(
state char(2)
-- char(2)代表有2个字符的字符串,例如CA, NY
-- varchar代表可变长度的字符串,在存储姓名、电话、信息时很有用
-- 多数时候用varchar,除非能确定字符串有固定长度
)
begin
select * from clients c
where c.state = state;
end $$
delimiter ;
-- 调用时要传参数
call get_clients_by_state('CA')

- 如果不传参数,会报错

练习
- 编写存储过程,返回给定客户的发票
drop procedure if exists get_invoices_by_client;
delimiter $$
create procedure get_invoices_by_client
(
client_id int
)
begin
select * from invoices i
where i.client_id = client_id;
end $$
delimiter ;
call get_invoices_by_client(3)
运行结果

设置参数的默认值
参数为空时,给参数设置一个值
- 在存储过程主体中设置参数的默认值
begin
if 参数 is null then
-- 如果参数为空,就给参数设置一个返回值
set 参数 = 默认值;
-- 或者,参数为空时,直接查询何种结果。
select * from clients;
end if;
……
end
- 示例:如果州为空,就返回州为CA的数据
drop procedure if exists get_clients_by_state;
delimiter $$
create procedure get_clients_by_state
(
state char(2)
)
begin
if state is null then
set state = 'CA';
end if;
select * from clients c
where c.state = state;
end $$
delimiter ;
call get_clients_by_state(null)
返回结果:

参数为空时,如何查询数据;不为空时,又如何查询数据
if…else…写法
- 如果不说是哪个州,即州为null,就返回所有数据;如果指定了州,就返回指定的数据
drop procedure if exists get_clients_by_state;
delimiter $$
create procedure get_clients_by_state
(
state char(2)
)
begin
if state is null then
select * from clients;
else
select * from clients c
where c.state = state;
end if;
end $$
delimiter ;
call get_clients_by_state(null)
运行结果
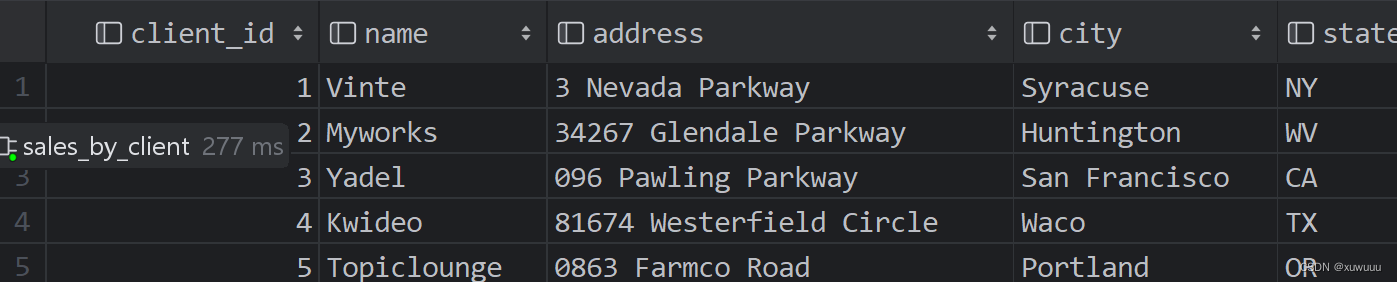
ifnull()写法
- 简化上一段代码:
- 用ifnull简化代码
drop procedure if exists get_clients_by_state;
delimiter $$
create procedure get_clients_by_state
(
state char(2)
)
begin
select * from clients c
-- ifnull:如果为state为空,就返回c.state.
where c.state = ifnull(state, c.state);
end $$
delimiter ;
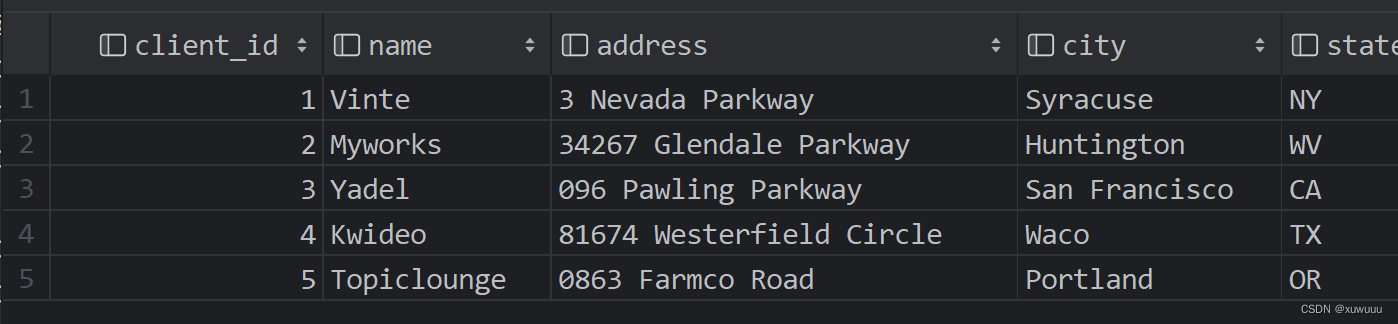
call get_clients_by_state(NULL)
返回结果:因为传入的参数是null,所以ifnull函数就将c.state传过去,这样就相当于c.state = c.state,会返回所有数据
练习
- 写一个存储过程:获取付款。带两个参数:客户id和付款方式id,这两个参数都不是必填的,如果这两个参数都传递空值,应该返回数据库里所有的付款记录。如果只提供客户id,就只返回这个客户的付款;如果两个参数都赋值,就返回指定客户使用指定付款方式支付的所有付款;
drop procedure if exists get_payments;
delimiter $$
create procedure get_payments
(
client_id int,
payment_method_id tinyint
)
begin
select *
from payments p
where
p.client_id = ifnull(client_id, p.client_id) and
p.payment_method = ifnull(payment_method_id, p.payment_method);
end $$
delimiter ;
- 测试存储过程
call get_payments(null,null);
call get_payments(1,null);
call get_payments(null,2);
call get_payments(5,1);
运行结果1:
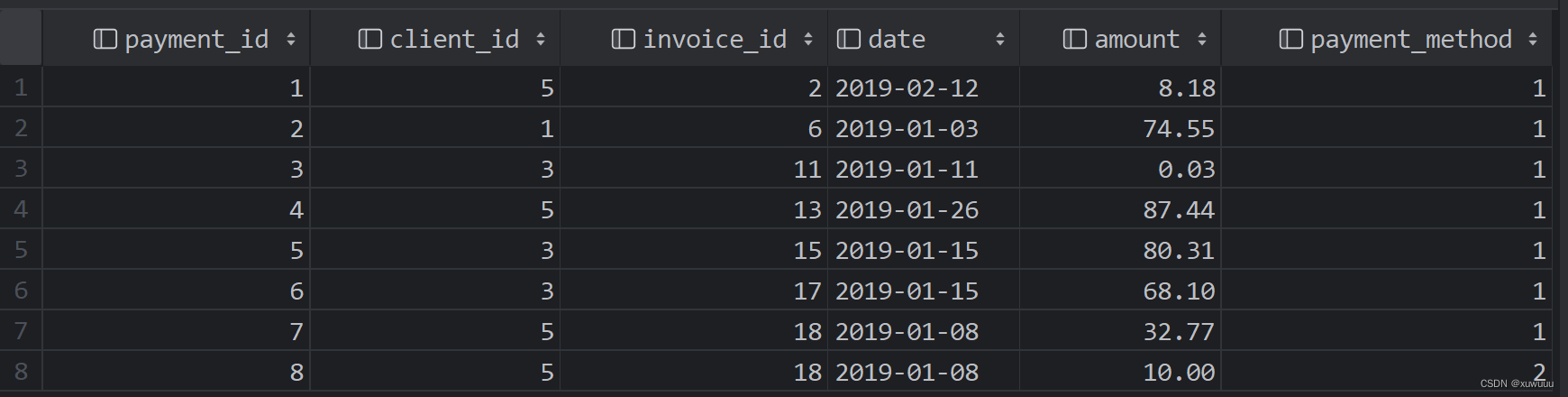
运行结果2:

运行结果3:

运行结果4:

参数验证
- 过程可以用来插入、更新和删除数据
- 通过参数验证确保过程不会意外地往数据库存储错误数据
没有参数验证会出现的问题
drop procedure if exists make_payments;
delimiter $$
create procedure make_payments
(
invoice_id int,
payment_amount decimal(9,2), -- 9代表位数,2代表小数点后的位数
payment_date date
)
begin
update invoices i
set -- 只更新两列
i.payment_total = payment_amount,
i.payment_date = payment_date
where i.invoice_id = invoice_id;
end $$
delimiter ;
call make_payments(2,100,'2019-01-01')
结果:invoices表被更新了,id为2的数据被更新了。

- 但如果把金额写为-100,也会进行更新。但这个数据是不合理的数据,因此要对传递的参数进行验证。
call make_payments(2,-100,'2019-01-01')
结果:

带参数验证的写法
- 尽量少用参数验证逻辑,只保留最关键的。
drop procedure if exists make_payments;
delimiter $$
create procedure make_payments
(
invoice_id int,
payment_amount decimal(9,2), -- 9代表位数,2代表小数点后的位数
payment_date date
)
begin
-- 增加参数验证
if payment_amount <= 0 then
signal sqlstate '22003'
set message_text = 'Invalid payment_amount';
end if;
-- 更新数据
update invoices i
set -- 只更新两列
i.payment_total = payment_amount,
i.payment_date = payment_date
where i.invoice_id = invoice_id;
end $$
delimiter ;
call make_payments(2,-100,'2019-01-01')
结果:此时会出现错误提示

if 后接验证条件
- if后接验证条件,如果满足,就执行then之后的语句
signal sqlstate 设置错误代码
- 用signal语句来标志或引发错误(类似抛出异常)
- 不同的异常有不同的错误代码,错误代码查询链接
set meesage_text 设置错误信息
- 可以选择发送错误信息,以帮助过程调用者识别原因。
输出参数(尽量避免使用)
- 通过select语句返回参数。
drop procedure if exists get_unpaid_invoices_for_client;
delimiter $$
create procedure get_unpaid_invoices_for_client
(
client_id int
)
begin
select count(*), sum(invoice_total)
from invoices i
where i.client_id = client_id and payment_total = 0;
end $$
delimiter ;
call get_unpaid_invoices_for_client(3)

- 输出参数,尽量避免使用
- 用out标记输出参数;
- 选择语句中,选择相应的值into到输出参数中。
- 使用输出参数时,读取数据比较麻烦
- set:定义变量,@符号前缀。在调用有输出参数的存储过程时使用这些变量;通过传递变量,获取输出参数值。
drop procedure if exists get_unpaid_invoices_for_client;
delimiter $$
create procedure get_unpaid_invoices_for_client
(
client_id int,
-- out会把参数标记为输出参数
out invoices_count int,
out invoices_total decimal(9,2)
)
begin
select count(*), sum(invoice_total)
into invoices_count, invoices_total
from invoices i
where i.client_id = client_id and payment_total = 0;
end $$
delimiter ;
-- 用set语句定义用户变量
set @invoices_count = 0;
set @invoices_total = 0;
call get_unpaid_invoices_for_client(3, @invoices_count, @invoices_total);
select @invoices_count, @invoices_total;

变量
用户或会话变量
- set语句 + @前缀
- 在调用有输出参数的存储过程时使用这些变量;通过传递变量,获取输出参数值。
- 用户或会话变量在整个过程中被保存,当客户从mysql断线时,这些变量被清空。
-- 用set语句定义用户变量
set @invoices_count = 0;
set @invoices_total = 0;
call get_unpaid_invoices_for_client(3, @invoices_count, @invoices_total);
select @invoices_count, @invoices_total;
本地变量
- 在存储过程或函数内定义的变量
- 通常使用本地变量在存储过程中执行计算任务,当存储过程执行完任务,这些本地变量就被清除了
declare 声明变量 / default 默认值
- 其中的risk_factor, invoices_total, invoices_count 都是本地变量,存储过程执行完以后就被清除了。
drop procedure if exists get_risk_factor;
delimiter $$
create procedure get_risk_factor()
begin
declare risk_factor decimal(9,2) default 0;
declare invoices_total decimal(9,2);
declare invoices_count int;
select count(*), sum(invoice_total)
into invoices_count, invoices_total
from invoices i;
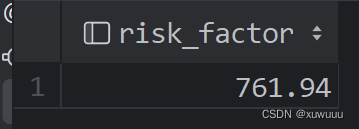
set risk_factor = invoices_total / invoices_count * 5;
select risk_factor;
end $$
delimiter ;
运行结果
函数
- 函数和存储过程的主要区别
- 函数只能返回单一值
- 存储过程可以返回拥有多行和多列的结果集
- 因此,如果想返回单一值,就可以创建函数
创建函数
drop function if exists get_risk_factor_for_client;
create function get_risk_factor_for_client
(
client_id int
)
-- 明确返回值的类型
returns integer
-- 设置函数属性
reads sql data
begin
-- 声明变量
declare risk_factor decimal(9,2) default 0;
declare invoices_total decimal(9,2);
declare invoices_count int;
-- 给变量赋值
select count(*), sum(invoice_total)
into invoices_count, invoices_total
from invoices i
where i.client_id = client_id;
-- 定义变量
set risk_factor = invoices_total / invoices_count * 5;
-- 函数的返回值,如果为空就返回0
return ifnull(risk_factor, 0);
end
-- 调用函数
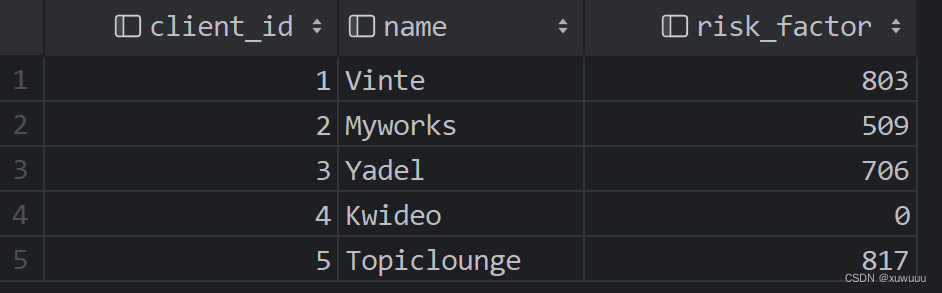
select client_id,
name,
get_risk_factor_for_client(client_id) as risk_factor
from clients
运行结果:
设置返回值的类型
- returns 类型
设置函数属性:每个函数至少有一个属性,可以有多个属性
- deterministic:确定性。如果给函数同样的一组值,函数永远会返回一样的值
- reads sql data:读取sql数据。函数中会配置选择语句,用于读取一些数据
- modifies sql data:修改sql数据。函数中有插入、更新、删除函数
删除或更新函数:drop function if exists
文章来源:https://blog.csdn.net/xuwuuu/article/details/134731862
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!