Linux NAPI ------------- epoll边缘触发模式
Linux处理网络数据包的一般流程
分组到达内核的时间是不可预测的。所有现代的设备驱动程序都使用中断来通知内核有分组到达。
网络驱动程序对特定于设备的中断设置了一个处理例程,因此每当该中断被引发时(即分组到达),内核都调用该处理程序,将数据从网卡传输到物理内存,或通知内核在一定时间后进行处理。
几乎所有的网卡都支持DMA模式,能够自行将数据传输到物理内存。
支持高速网络设备
每次一个以太网帧到达时,都使用一个IRQ来通知内核。 对低速设备来说,在下一个分组到达之前,IRQ的处理通常已经结束。
由于下一个分组也通过IRQ通知,如果前一个分组的IRQ尚未处理完成,则会导致问题,高速设备通常就是这样。
现代以太网卡的运作高达10 000 Mbit/s,如果使用旧式方法来驱动此类设备,将造成所谓的“中断风暴”。
NAPI原理 (类比epoll边缘触发模式)
为解决该问题,NAPI使用了IRQ和轮询的组合
假定某个网络适配器此前没有分组到达,但从现在开始,分组将以高频率频繁到达。这就是NAPI
设备的情况,如下所述。
- 第一个分组将导致网络适配器发出IRQ。为防止进一步的分组导致发出更多的IRQ,驱动程序 会关闭该适配器的Rx
IRQ。并将该适配器放置到一个轮询表上。 - 只要适配器上还有分组需要处理,内核就一直对轮询表上的设备进行轮询。
- 重新启用Rx中断。
如果在新的分组到达时,旧的分组仍然处于处理过程中,工作不会因额外的中断而减速。虽然对
设备驱动程序(和一般意义上的内核代码)来说轮询通常是一个很差的方法,但在这里该方法没有什
么不利之处:在没有分组还需要处理时,将停止轮询,设备将回复到通常的IRQ驱动的运行方式。在
没有中断支持的情况下,轮询空的接收队列将不必要地浪费时间,但NAPI并非如此。
NAPI的另一个优点是可以高效地丢弃分组。如果内核确信因为有很多其他工作需要处理,而导
致无法处理任何新的分组,那么网络适配器可以直接丢弃分组,无须复制到内核。
只有设备满足如下两个条件时,才能实现NAPI方法。
(1) 设备必须能够保留多个接收的分组,例如保存到DMA环形缓冲区中。下文将该缓冲区称为Rx
缓冲区。
(2) 该设备必须能够禁用用于分组接收的IRQ。而且,发送分组或其他可能通过IRQ进行的操作,
都仍然必须是启用的
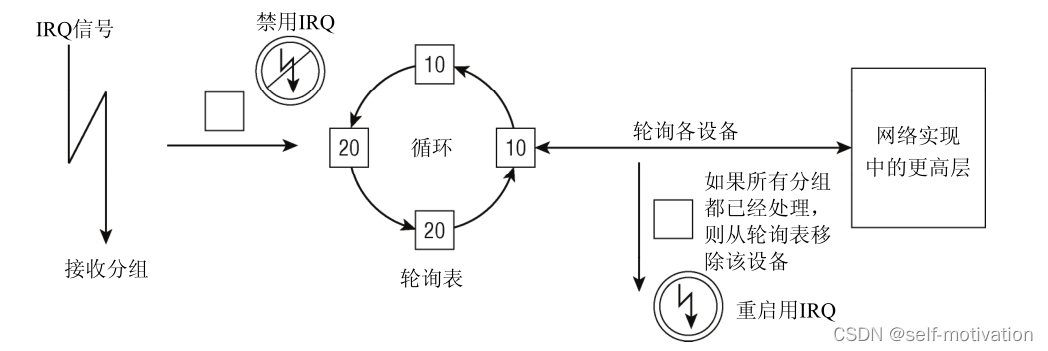
循环处理所有设备
内核以循环方式处理链表上的所有设备:内核依次轮询各个设备,如果已经花费了一定的时间来
处理某个设备,则选择下一个设备进行处理。
此外,某个设备都带有一个相对权重,表示与轮询表中其他设备相比,该设备的相对重要性。较快的设备权重较大,较慢的设备权重较小。由于权重指定了在一个轮询的循环中处理多少分组,这确保了内核将更多地注意速度较快的设备。
NAPI细节
现在我们已经弄清楚了NAPI的基本原理,接下来将讨论其实现细节。
与旧的API相比,关键性的变化在于,支持NAPI的设备必须提供一个 poll 函数。
该方法是特定于设备的,在用 netif_napi_add注册网卡时指定。调用该函数注册,表明设备可以且必须用新方法处理。
<netdevice.h>
static inline void netif_napi_add(struct net_device *dev,
struct napi_struct *napi,
int (*poll)(struct napi_struct *, int),
int weight);
- dev 指向所述设备的 net_device 实例
- poll 指定了在IRQ禁用时用来轮询设备的函数
- weight指定了设备接口的相对权重。实际上可以对 weight 指定任意整数值。通常10/100 Mbit网卡的驱动程序
指定为16,而1 000/10 000 Mbit网卡的驱动程序指定为64。无论如何,权重都不能超过该设备可以在
Rx缓冲区中存储的分组的数目。 - netif_napi_add 还需要另一个参数,是一个指向 struct napi_struct 实例的指针。该结构用于
管理轮询表上的设备。其定义如下:
<netdevice.h>
struct napi_struct {
struct list_head poll_list;
unsigned long state;
int weight;
int (*poll)(struct napi_struct *, int);
};
轮询表通过一个标准的内核双链表实现, poll_list 用作链表元素。
weight 和 poll 的语义同上文所述。
state 可以是 NAPI_STATE_SCHED 或 NAPI_STATE_DISABLE ,前者表示设备将在内核的下一次循
环时被轮询,后者表示轮询已经结束且没有更多的分组等待处理,但设备尚未从轮询表移除。
请注意,struct napi_struct 经常嵌入到一个更大的结构中,后者包含了与网卡有关的、特定
于驱动程序的数据。这样在内核使用 poll 函数轮询网卡时,可用 container_of 机制获得相关信息。
实现 poll 函数
poll 函数需要两个参数:一个指向 napi_struct 实例的指针和一个指定了“预算”的整数,预算
表示内核允许驱动程序处理的分组数目。我们并不打算处理真实网卡的可能的奇异之处,因此讨论一
个伪函数,该函数用于一个需要NAPI的超高速适配器:
static int hyper_card_poll(struct napi_struct *napi, int budget)
{
struct nic *nic = container_of(napi, struct nic, napi);
struct net_device *netdev = nic->netdev;
int work_done;
work_done = hyper_do_poll(nic, budget);
if (work_done < budget) {
netif_rx_complete(netdev, napi);
hcard_reenable_irq(nic);
}
return work_done;
}
在从 napi_struct 的容器获得特定于设备的信息之后,调用一个特定于硬件的方法(这里是
hyper_do_poll )来执行所需要的底层操作从网络适配器获取分组,并使用像此前那样使用
netif_receive_skb 将分组传递到网络实现中更高的层。
hyper_do_poll 最多允许处理 budget 个分组。
该函数返回实际上处理的分组的数目。必须区分以下两种情况。
- 如果处理分组的数目小于预算,那么没有更多的分组,Rx缓冲区为空,否则,肯定还需要处
理剩余的分组(亦即,返回值不可能小于预算)。因此, netif_rx_complete 将该情况通知内
核,内核将从轮询表移除该设备。接下来,驱动程序必须通过特定于硬件的适当方法来重新 启用IRQ。 - 已经完全用掉了预算,但仍然有更多的分组需要处理。设备仍然留在轮询表上,不启用中断。
实现IRQ处理程序
NAPI也需要对网络设备的IRQ处理程序做一些改动。这里仍然不求助于任何具体的硬件,而介绍
针对虚构设备的代码:
static irqreturn_t e100_intr(int irq, void *dev_id)
{
struct net_device *netdev = dev_id;
struct nic *nic = netdev_priv(netdev);
if(likely(netif_rx_schedule_prep(netdev, &nic->napi))) {
hcard_disable_irq(nic);
__netif_rx_schedule(netdev, &nic->napi);
}
return IRQ_HANDLED;
}
假定特定于接口的数据保存在 net_device->private 中,这是大多数网卡驱动程序使用的方法。
使用辅助函数 netdev_priv 访问该字段。
现在需要通知内核有新的分组可用。这需要如下二阶段的方法。
- netif_rx_schedule_prep 准备将设备放置到轮询表上。本质上,这会安置 napi_struct-> flags
中的 NAPI_STATE_SCHED 标志。 - 如果设置该标志成功(仅当NAPI已经处于活跃状态时,才会失败),驱动程序必须用特定于设 备的适当方法来禁用相应的IRQ。调用
__netif_rx_schedule 将设备的 napi_struct 添加到轮询表, 并引发软中断 NET_RX_SOFTIRQ 。这通知内核在 net_rx_action 中开始轮询
处理Rx软中断
在讨论了为支持NAPI驱动程序需要做哪些改动之后,我们来考察一下内核需要承担的职责。
net_rx_action 依旧是软中断 NET_RX_SOFTIRQ 的处理程序。
下图给出了其代码流程图:
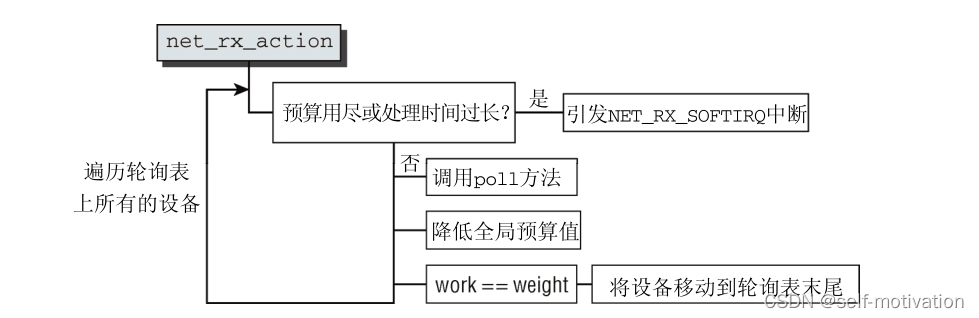
本质上,内核通过依次调用各个设备特定的 poll 方法,处理轮询表上当前的所有设备。设备的权
重用作该设备本身的预算,即轮询的一步中可能处理的分组数目。
必须确保在这个软中断的处理程序中,不会花费过多时间。如果如下两个条件成立,则放弃处理。
- 处理程序已经花费了超出一个 jiffie 的时间。
- 所处理分组的总数,已经超过了 netdev_budget 指定的预算总值。通常,总值设置为300,但 可以通过
/proc/sys/net/core/netdev_budget 修改。
这个预算不能与各个网络设备本身的预算混淆!在每个轮询步之后,都从全局预算中减去处理的
分组数目,如果该预算值下降到0,则退出软中断处理程序。
在轮询了一个设备之后,内核会检查所处理的分组数目,与该设备的预算是否相等。如果相等,
那么尚未获得该设备上所有等待的分组,即代码流程图中 work == weight 所表示的情况。内核接下
来将该设备移动到轮询表末尾,在链表中所有其他设备都处理过之后,继续轮询该设备。显然,这实
现了网络设备之间的循环调度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!