Mysql高可用
?
目录
准备4台服务器,一台为主服务,两台为从服务器,还有一台为mha? manager服务器
所有服务器上都安装 MHA 依赖的环境,首先安装 epel 源:
一.msyql的高可用
mha:m是master,是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。出现就是解决MySQL 单点的问题。
MHA 的组成:
MHA Node(数据节点):MHA Node 运行在每台 MySQL 服务器上。
MHA Manager(管理节点):MHA Manager 可以单独部署在一台独立的机器上,管理多个 master-slave 集群;也可以部署在一台 slave 节点上。
manager的工作过程:
MHA Node 运行在每台 MySOL 服务器上,MHA Manager 会定时探测集群中的master 节点,当master 出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave 重新指向新的master。整个故障转移过程对客户端应用程序完全透明。
mmm高可用:
提供了自动和手动两种方式移除一组服务器中复制延迟较高的服务器的虚拟ip,同时它还可以备份数据,实现两节点之间的数据同步等。由于MMM无法完全保证数据的一致性,所以MMM适用于对数据的一致性要求不是很高,但是又想最大程度地保证业务可用性的场景。
二.部署mha高可用
准备4台服务器,一台为主服务,两台为从服务器,还有一台为mha? manager服务器
主:192.168.233.10
从:192.168.233.20:192.168.233.30
mha? manager:192.168.233.40
修改主从服务器他们的主机名:



修改主从服务器的域名解析文件:



修改主从服务器的mysql配置文件,添加二进制文件,中继日志:



重启服务:



在主从服务器创建软连接:



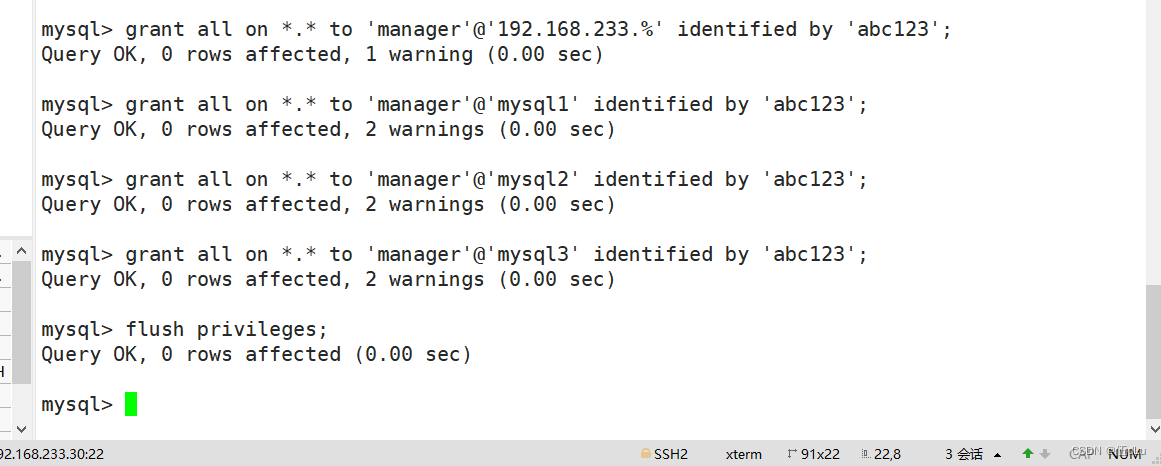
给主从数据库授权:
主服务器:

从服务器:


防止从库通过主机名连接不上主库,进行主机名授权:
主服务器:

从服务器:

进行配置主从复制:
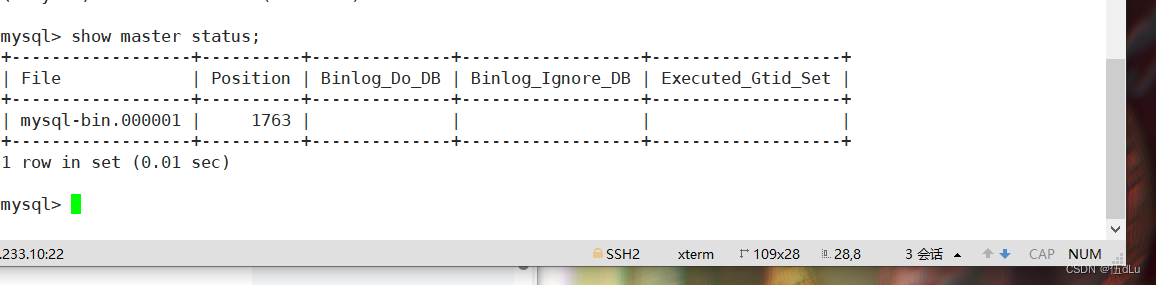
查看主服务器的信息状态:
在从服务器上添加授权:
192.168.233.20:

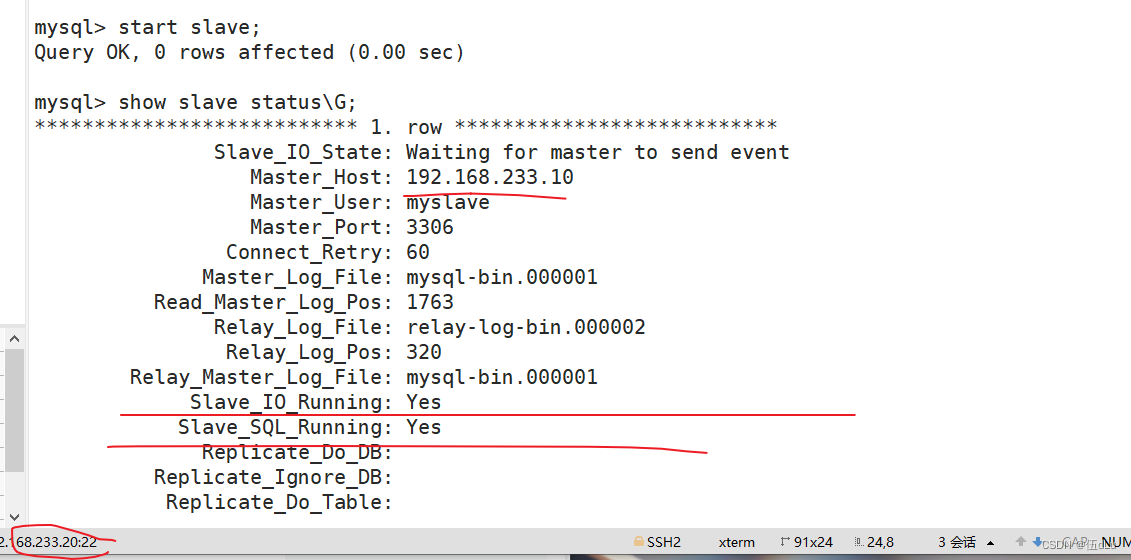
192.168.233.30:

设置两个从库必须设置为只读模式:


检测一下,在主服务器添加库:
 从服务器看下:
从服务器看下:


主从复制完成。
所有服务器上都安装 MHA 依赖的环境,首先安装 epel 源:




拖入mha node安装包进行解压:

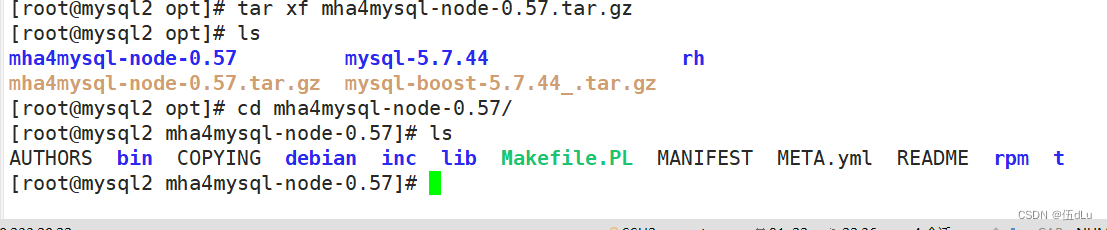


每台服务器都是这么操作:


每台服务器进行编译安装:
对每台编译安装node:

在mha manager服务器上解压manager包:
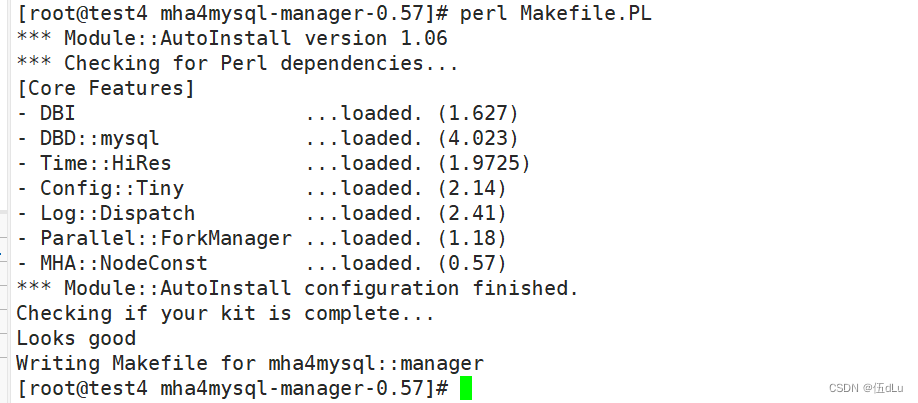
对manager进行编译安装:

安装完成后会有几个脚本工具:

masterha_check_ssh 检查 MHA 的 SSH 配置状况
masterha_check_repl 检查 MySQL 复制状况
masterha_manger 启动 manager的脚本
masterha_check_status 检测当前 MHA 运行状态
masterha_master_monitor 检测 master 是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的 server 信息
masterha_stop ?关闭manager
save_binary_logs 保存和复制 master 的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的 slave
filter_mysqlbinlog 去除不必要的 ROLLBACK 事件(MHA 已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞 SQL 线程)
在所有服务器上配置无密码认证:
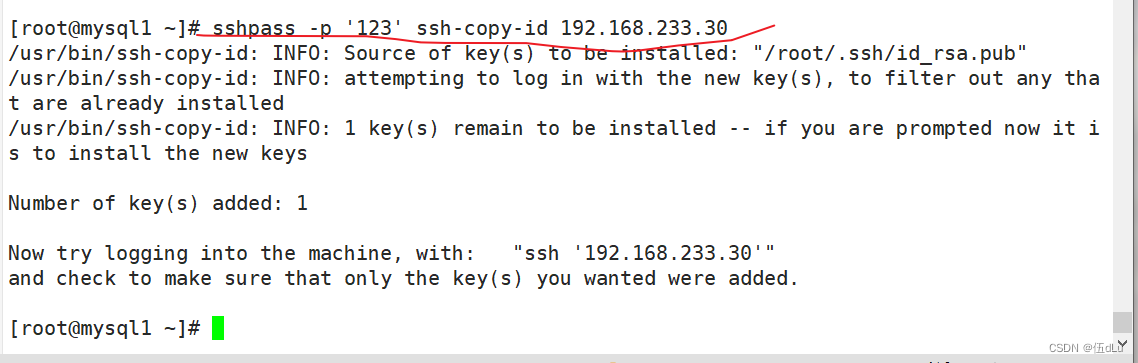
所有服务器下载sshpass:

每台都要设置免密:

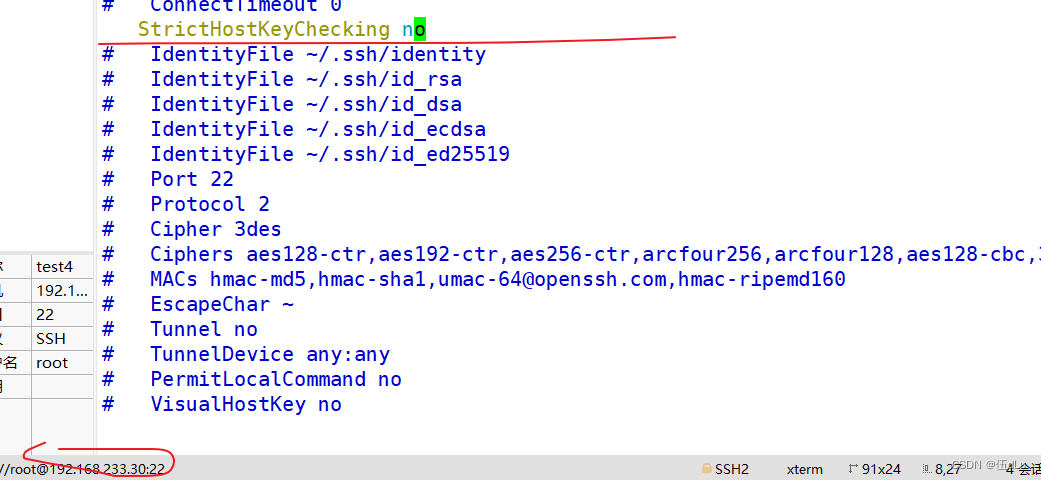
修改主服务器ssh配置文件:
![]()


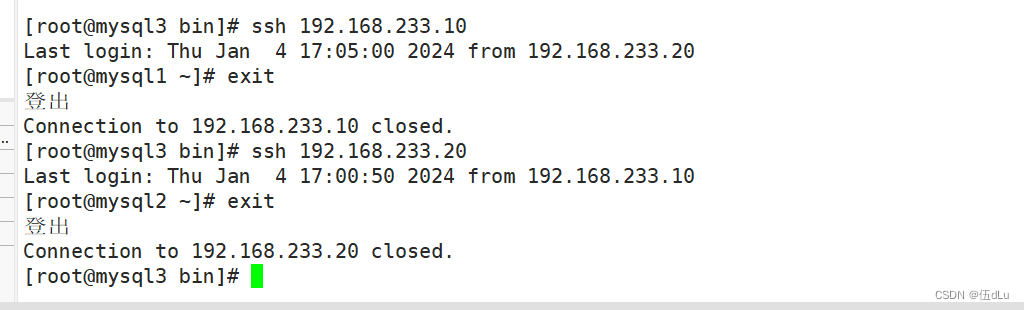
测试:

测试:

给从服务器修改ssh配置文件:
192.168.233.20:
![]()
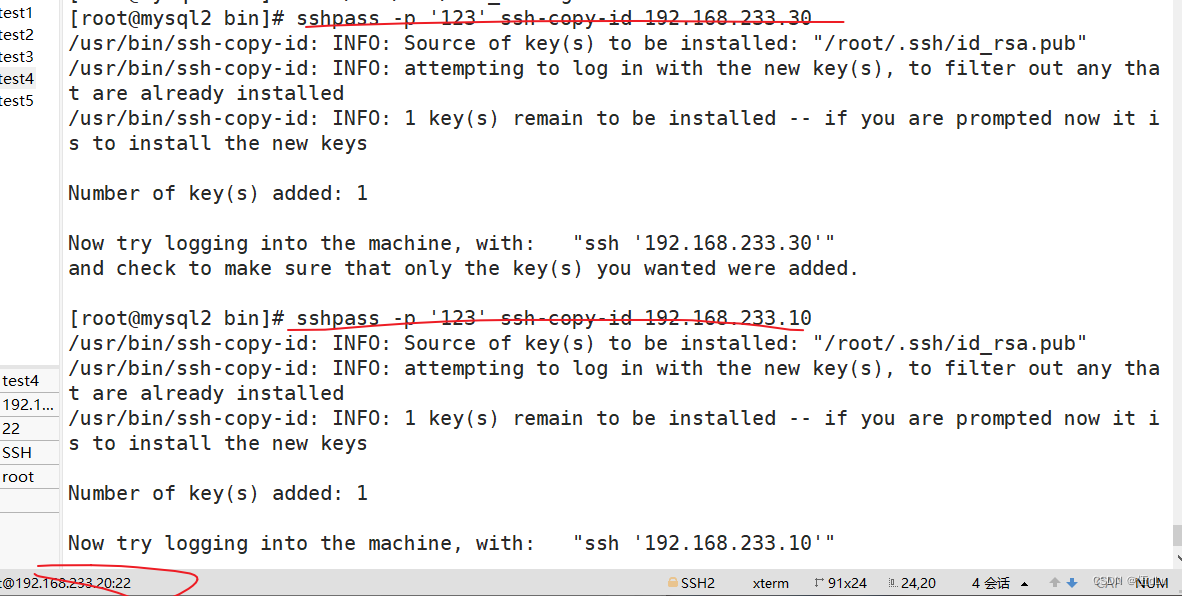
测试:


192.168.233.30:


测试:
在manager服务器上修改ssh配置文件:


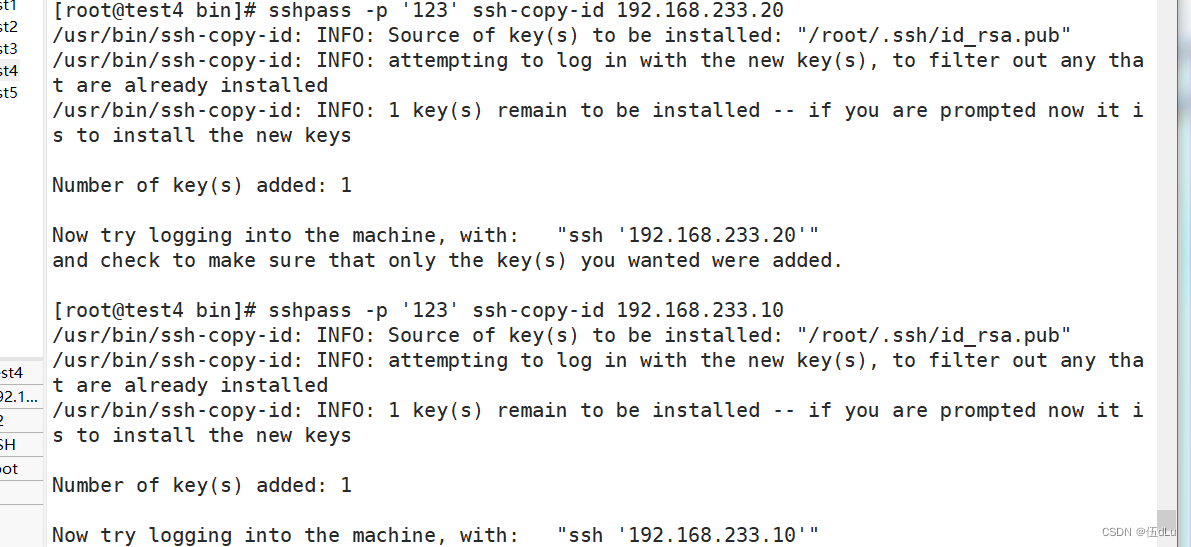
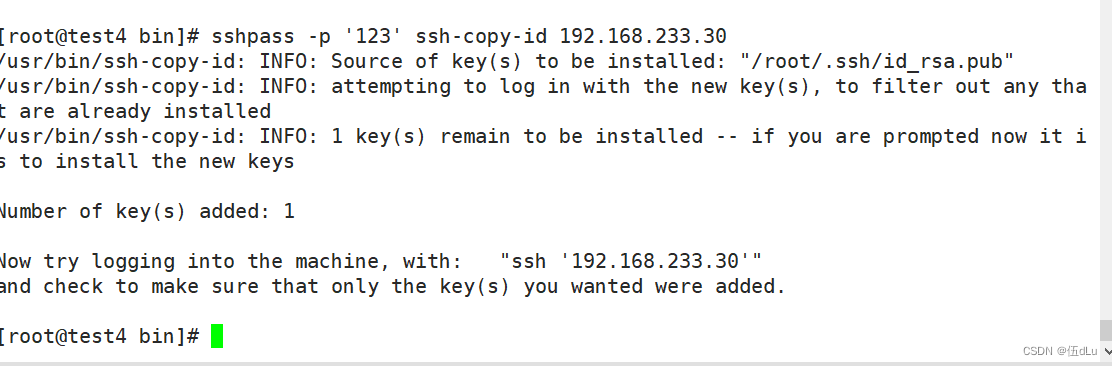
测试:
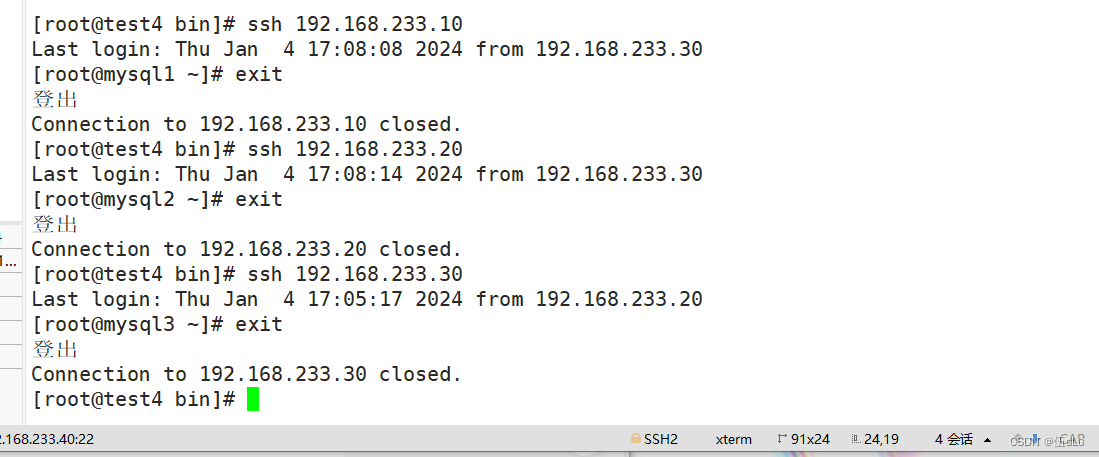
在manager服务器上配置:
将相关脚本到/usr/local/bin 目录:

master_ip_failover ??? ??? ?自动切换时 VIP 管理的脚本
master_ip_online_change ?? ?在线切换时 VIP 的管理
power_manager ?? ??? ??? ??? ?故障发生后关闭主机的脚本
send_report ?? ??? ??? ??? ?因故障切换后发送报警的脚本


将脚本复制到/usr/local/bin下:



修改脚本内容:
在后面操作的主服务器上添加vip需要:

所有服务器上创建 MHA 软件目录并拷贝配置文件:




在manager服务器创建mha目录:


编写配置文件:
![]()


在主服务器配置vip:

在 manager 节点上测试 ssh 无密码认证:
正常最后会输出 successfully:
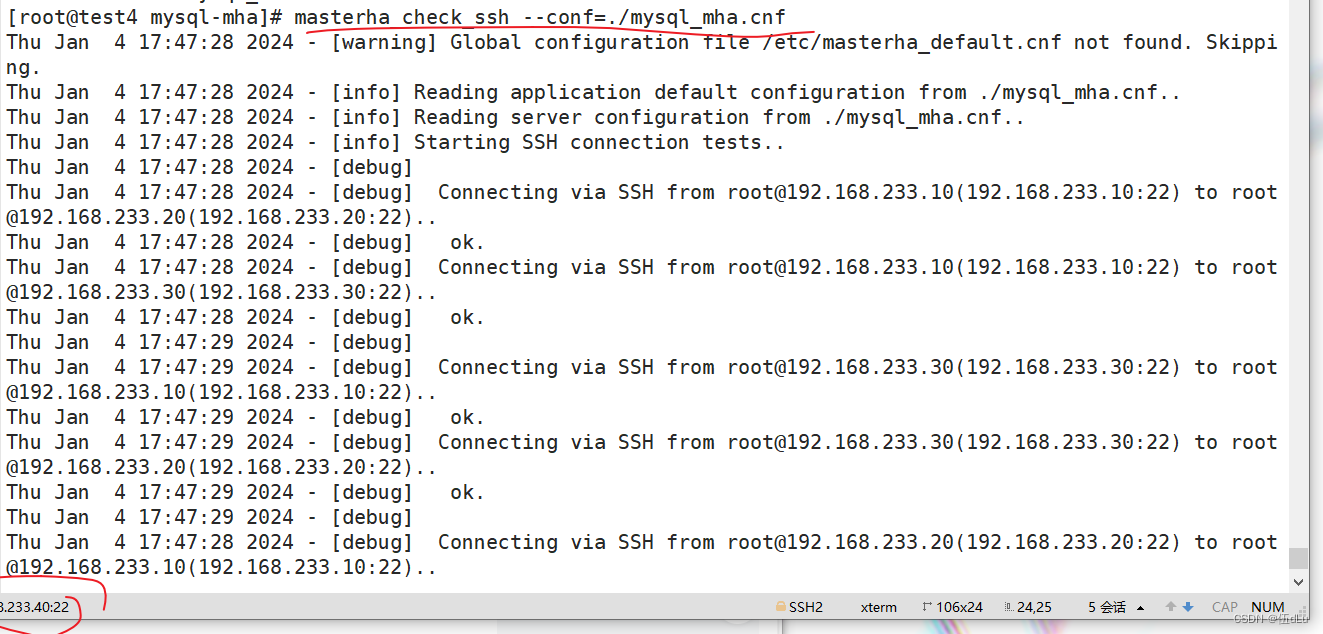

测试 mysql 主从连接情况:
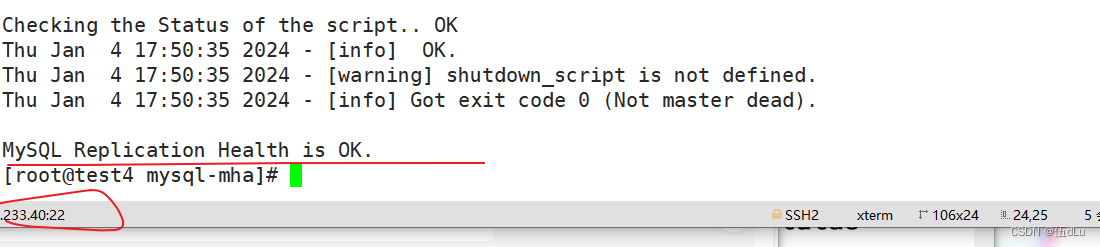
最后出现 MySQL Replication Health is OK为正常:

在 manager 服务器上后台启动 MHA:

--remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的 ip 将会从配置文件中移除。
--ignore_last_failover:在缺省情况下,如果 MHA 检测到连续发生宕机,且两次宕机间隔不足 8 小时的话,则不会进行 Failover, 之所以这样限制是为了避免 ping-pong 效应。
--ignore_last_failover:该参数代表忽略上次 MHA 触发切换产生的文件,默认情况下,MHA 发生切换后会在 app1.failover.complete 日志文件中记录,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换, 除非在第一次切换后删除该文件。

查看 MHA 状态:


查看 mysql1 的 VIP 地址 192.168.233.200 是否存在:
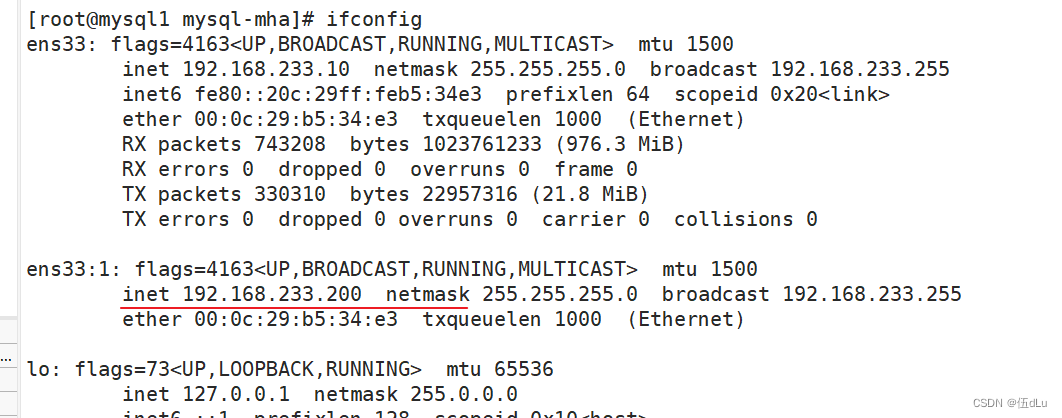
关闭 manager 服务:


故障模拟:
在 manager 节点上监控观察日志记录:

在 Master 节点 mysql1 上停止mysql服务:

正常自动切换一次后,MHA 进程会退出。HMA 会自动修改 app1.cnf 文件内容,将宕机的 mysql1 节点删除。查看 mysql2 是否接管 VIP:
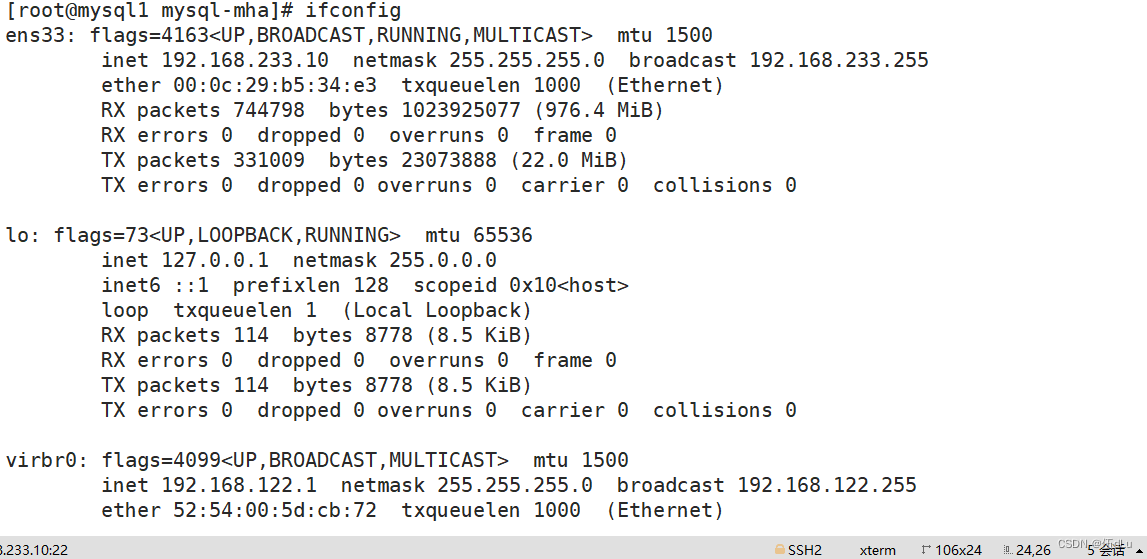
vip漂移到从服务器了:
查看日志:

查看manager配置文件:

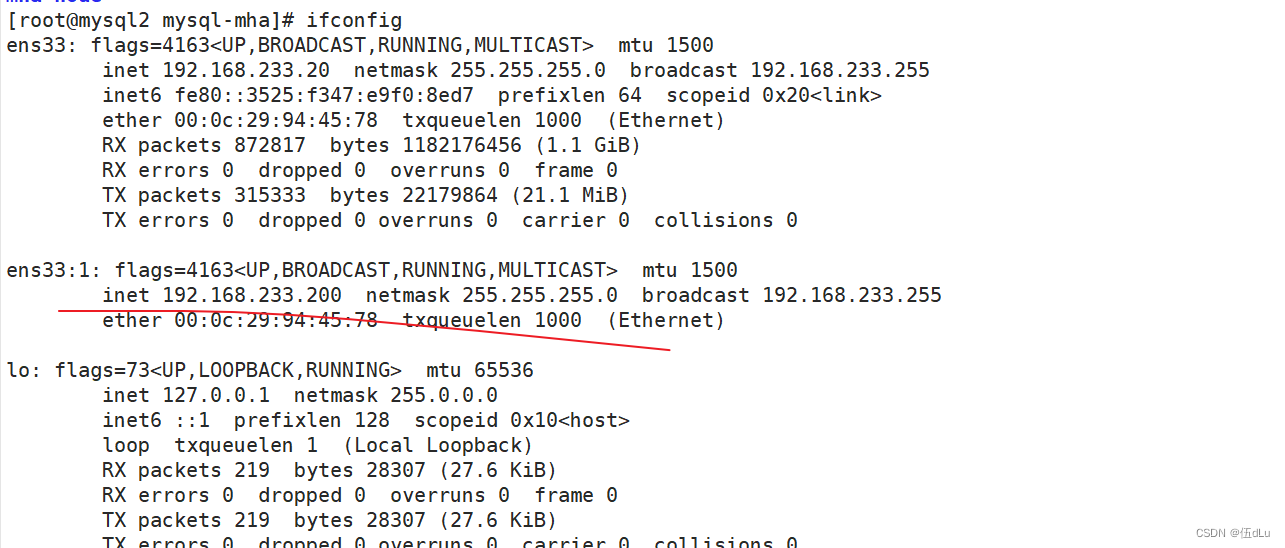
查看下192.168.233.30的从服务器的主服务器指向:

故障修复步骤:
开启192.168.233.10的mysql:

在现主库服务器 mysql2 查看二进制文件和同步点:
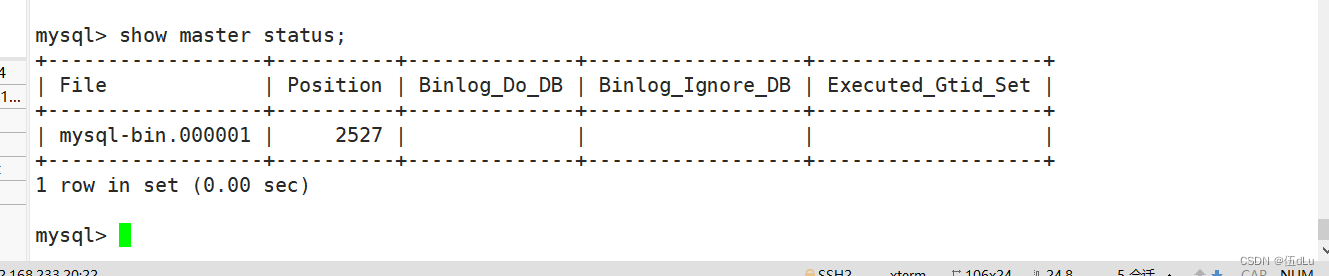
在原主库服务器 mysql1 执行授权:


在manager 节点上修改配置文件添加mysql1服务:



查看状态:

关闭192.168.233.20的主服务器:

看下192.168.233.10:

看下日志:

恢复成功。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!