第三十四周:文献阅读+LSTM学习
目录
文献阅读:综合EMD-LSTM模型在城市排水管网水质预测中的应用
摘要
在本周阅读的文献中,提出了以EMD为中心的数据预处理模块和LSTM预测模块相结合的城市排水管网水质HCI综合预测模型。在EMD-LSTM模型中,EMD允许保留异常值并利用非对齐时刻的数据,这有助于捕获数据模式,而LSTM神经网络强大的非线性映射和学习能力可以对水质进行时间序列预测,综合预测模型实现对城市排水网络水质的准确预测。LSTM是一种特殊的RNN,比普通的RNN多了三个“门”,可以让信息有选择性的通过。LSTM能够在更长的序列中有更好的表现,解决了RNN训练时的梯度无效问题。
Abstract
The literature read this week proposes a comprehensive prediction model for urban drainage network water quality HCI, which combines an EMD centered data preprocessing module and an LSTM prediction module. In the EMD-LSTM model, EMD allows for retaining outliers and utilizing data from non aligned moments, which helps capture data patterns. The powerful nonlinear mapping and learning capabilities of LSTM neural networks enable time series prediction of water quality, and the comprehensive prediction model achieves accurate prediction of water quality in urban drainage networks. LSTM is a special type of RNN that has three more gates than regular RNN, allowing information to selectively pass through. LSTM can perform better in longer sequences, solving the problem of ineffective gradients during RNN training.
文献阅读:综合EMD-LSTM模型在城市排水管网水质预测中的应用
链接:Accurate prediction of water quality in urban drainage network with integrated EMD-LSTM model
现有问题
快速准确地掌握排水管网中的水质,对于城市水环境的管理和预警至关重要。而基于建模的检测方法能够基于廉价的多源数据进行快速且无需试剂的水质检测,这比传统的基于化学反应的检测方法更清洁、更可持续。这些方法只需要很少的参数,并且可以进行更清洁和可持续的水质检测。但其准确性不尽如人意,因此这也限制了在实际上的应用。这一问题可归因于其处理非线性、非平稳水质时间序列的能力较差。
提出方法
在深度学习算法中,LSTM神经网络又因其独特的门结构而特别擅长处理时间序列,使其能够捕获时间序列中的长期依赖关系。使用LSTM神经网络作为建模算法是提高基于建模的水质检测精度的有效途径。该文提出一种融合EMD-LSTM模型,该模型将以经验模态分解(EMD)为中心的数据预处理模块与长短期记忆(LSTM)神经网络预测模块相结合,以提高基于建模的检测方法的精度。由于时间序列相邻值之间的密切关系,非对齐数据是优化对齐时刻数据(即对齐数据)的良好基础。设计一个预处理程序,有效地利用准确的异常值和非对齐数据是必要的。时频变换技术可以将时间序列转换成不同频率的分量。过滤掉代表噪声或对原始数据贡献不大的成分可以减少噪声。这意味着时频变换算法允许保留异常值并通过非对齐数据优化对齐数据。值得一提的是,一些时频变换技术,如短时傅立叶变换(STFT)和小波变换(WT),不适合分析非平稳时间序列。原因是它们的基函数在变换过程中不能改变,而经验模态分解(EMD)有效地克服了这一困难。
EMD-LSTM综合模型

通过多源混频数据集作为测试数据,根据获取数据所需的时间和经济成本,将15个指标分为两部分,LCIs(L1,L2,…,L10)作为模型输入,HCIs(H1,H2,…,H5)作为模型输出。对所有指标进行基本预处理,包括清洗、填充和归一化。但这仅清理了由于仪器故障导致的连续缺失值和异常值。用插值法填充单个缺失值。Min-max归一化方法将所有指标归一化,消除数值差异,如式(1)所示,对每个LCI进行EMD。对于在此分解中获得的分量,代表噪声或具有低贡献的部分被去除。将剩余成分相加,形成优化后的LCIs(L1',L2',…,L10')。在预处理程序结束时,高频指标根据低频指标的频率进行对齐。在移除高频指标之前,将频率对准放置在EMD之后,以确保高频指标中频率不匹配的部分有助于EMD。
 (1)
(1)
表示时间序列中时间t所对应的值,
表示
归一化后的值,
表示时间序列中的最大值,
表示时间序列中的最小值。
将优化后频率一致的LCI作为“多对一”结构LSTM神经网络的输入。在检验EMD-LSTM模型的性能时,构建了5个结构相同的EMD-LSTM模型,分别预测5个HCI。
EMD原理
EMD自适应地将非线性非平稳时间序列分解为几个固有模态函数(IMF)和一个趋势项(即分量)。IMF的数量取决于时间序列本身。该方法的优点是基于时间序列本身的尺度特征实现分解,不需要设置任何基函数。IMF和趋势项是在一个连续的迭代过程中产生的。具体流程可归纳为如下六个步骤:
- 找到时间序列
中所有的局部最大值和局部最小值。
- 基于三次样条插值理论(cubic spline interpolation theory),将所有的局部最大值和最小值分别连接起来,形成上下包络线(
和
)。
- 通过公式
产生平均包络线
。
- 通过公式
产生差异
。
- 检查
- 如果不满足IMF的条件,
),然后根据公式
产生第一个残差
来替换掉时间序列
连续迭代,直到满足标准差小于0.25,则
是趋势项。如公
所示,时间序列
最后通过EMD分解为n个IMF和一个趋势项的和。
研究框架
将数据集分为训练集(2019-10-26 ~ 2019-11-20,25 d)和测试集(2019-11-21 ~ 2019-11-26,6 d),分割比例为4:1。结合传统的预处理模块和预测模块构建了其他集成模型,与EMD-LSTM集成模型进行对比。设计了一系列的对照实验来测试所提出的EMD-LSTM的性能并分析其产生的原因,主要分为五个部分:
- 比较不同数据预处理程序对预测精度的影响
- 比较不同预测算法对预测精度的影响
- 分析不同数据预处理程序对数据集的优化效果
- 验证保留异常值对预测精度的影响
- 验证利用非对齐数据对预测精度的影响
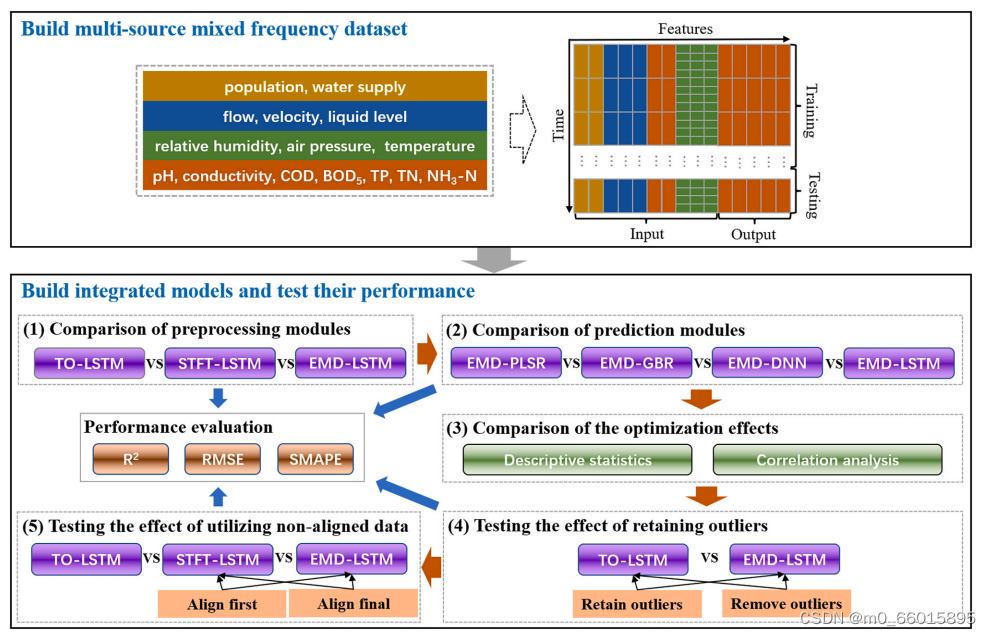
集成模型的性能评价
1、预处理模块比较
构建EMD-LSTM、to - lstm、STFT-LSTM,比较不同预处理模块对预测精度的影响。采用SMAPE、判定R2、RMSE评价EMD-LSTM模型的预测性能。SMAPE该统计度量可以反映预测结果与实测值之间的相对偏差程度。RMSE表示实测值与预测结果的绝对差值,R2可以反映实测值的波动可以被模型预测值解释的程度。结果表明,STFT和EMD在时间序列预处理过程中确实可以提高预测结果的精度。
?2、预测模块比较
测试了EMD预处理模块与传统数据驱动预测模块相结合的效果。在综合EMDLSTM模型中,使用PLSR、GBR、DNN作为预测模块替代LSTM,4种预测模块的性能表现为LSTM > DNN > GBR > PLSR。即RNN架构和门结构带来的记忆能力使LSTM更适合处理时间序列问题
结论
与传统数据预处理程序(即TO、STFT)和数据驱动预测算法(即PLSR、GBR、DNN)形成的集成模型相比,EMD-LSTM集成模型在预测hci方面表现最佳。在数据预处理过程中应用时频变换算法提高了预测精度,EMD算法的预测效果优于STFT算法。保留的异常值有助于保持原始时间序列的完整性,这使得LSTM神经网络能够更好地捕获数据模式(R2高0.87-1.73%)。在高频指标中,非对齐数据正有助于优化对齐数据,提高后续LSTM神经网络的准确率(R2提高0.27 ~ 0.54%)。良好的精度(R2≥0.94)使得集成EMD-LSTM模型适合实际应用中的水质检测。
Long Short-term Memory(长短期记忆)
1.?LSTM的结构
LSTM是一种特殊的RNN,比普通的RNN多了三个“门”,可以让信息有选择性的通过。当一条序列很长的时候,RNN很难将从一开始的信息传送到后面的时间点,而LSTM能够学习长期依赖的信息,记住早时间点的信息,更好的联系上下文。
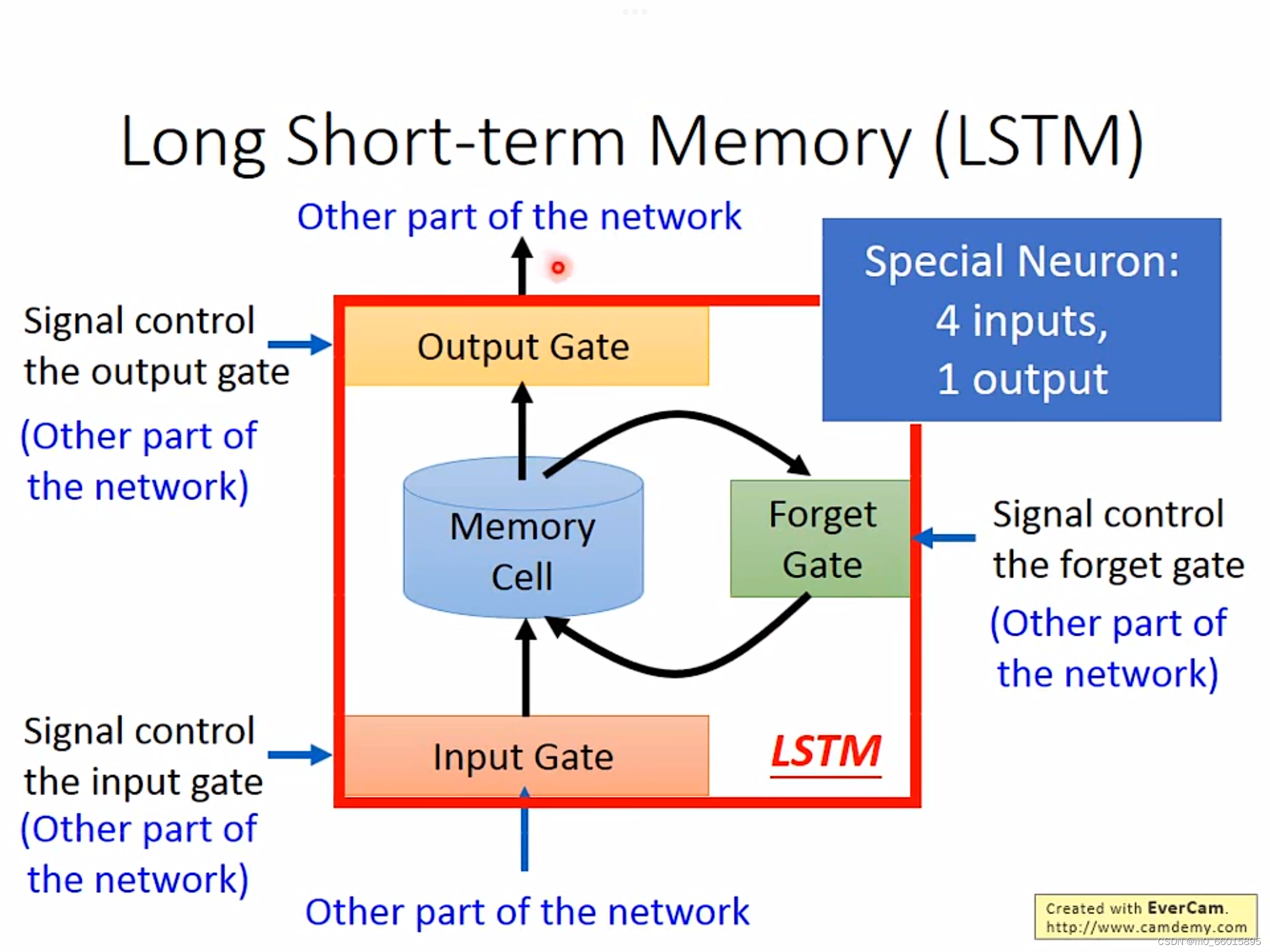
Input Gate:控制input数据输入
Forget Gate:控制是否保存中间结果
Output Gate:控制output数据输出
乘上一个matrix变成向量
,
再分别乘以一个transform得到
、
、
,它们的维数跟LSTM的数量一样,
的每一维的数值分别代表每个LSTM的input,
、
、
的每一维操纵一个LSTM的Input?Gate、Output Gate、Forget Gate。
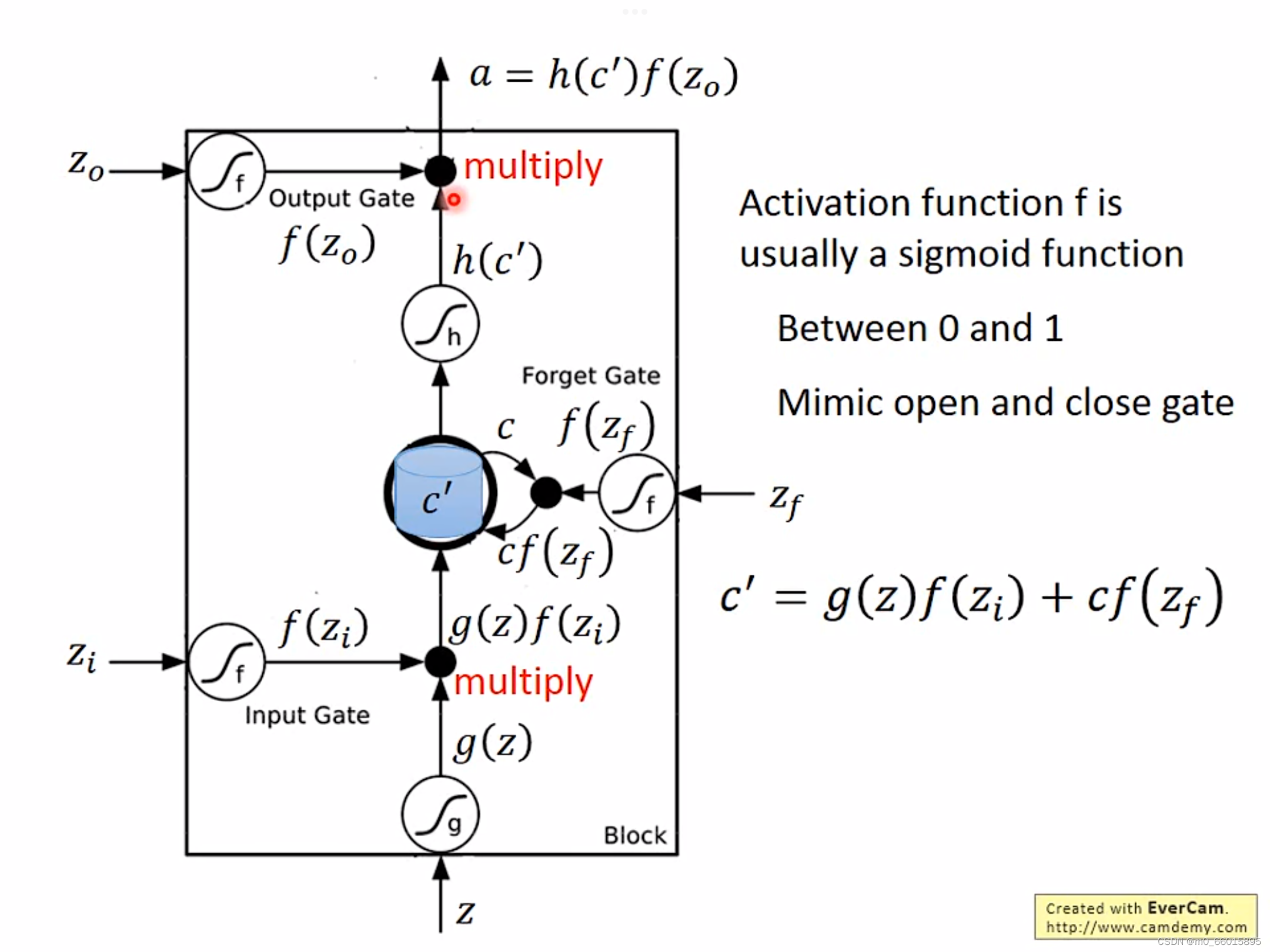
输入:
输出门控制信号:
输入门控制信号:
遗忘门控制信号:
激活函数基本都是sigmoid函数,值域在0和1之间,函数值决定所控制门的开关程度,值越大,门打开程度越大。如果
为0,这说明存在memory中的数值不能被读取出来。Input Gate与Output Gate的开与关是由network进行学习后自行决定的,对memory里的哪些值进行forget也是由network自行学习的。
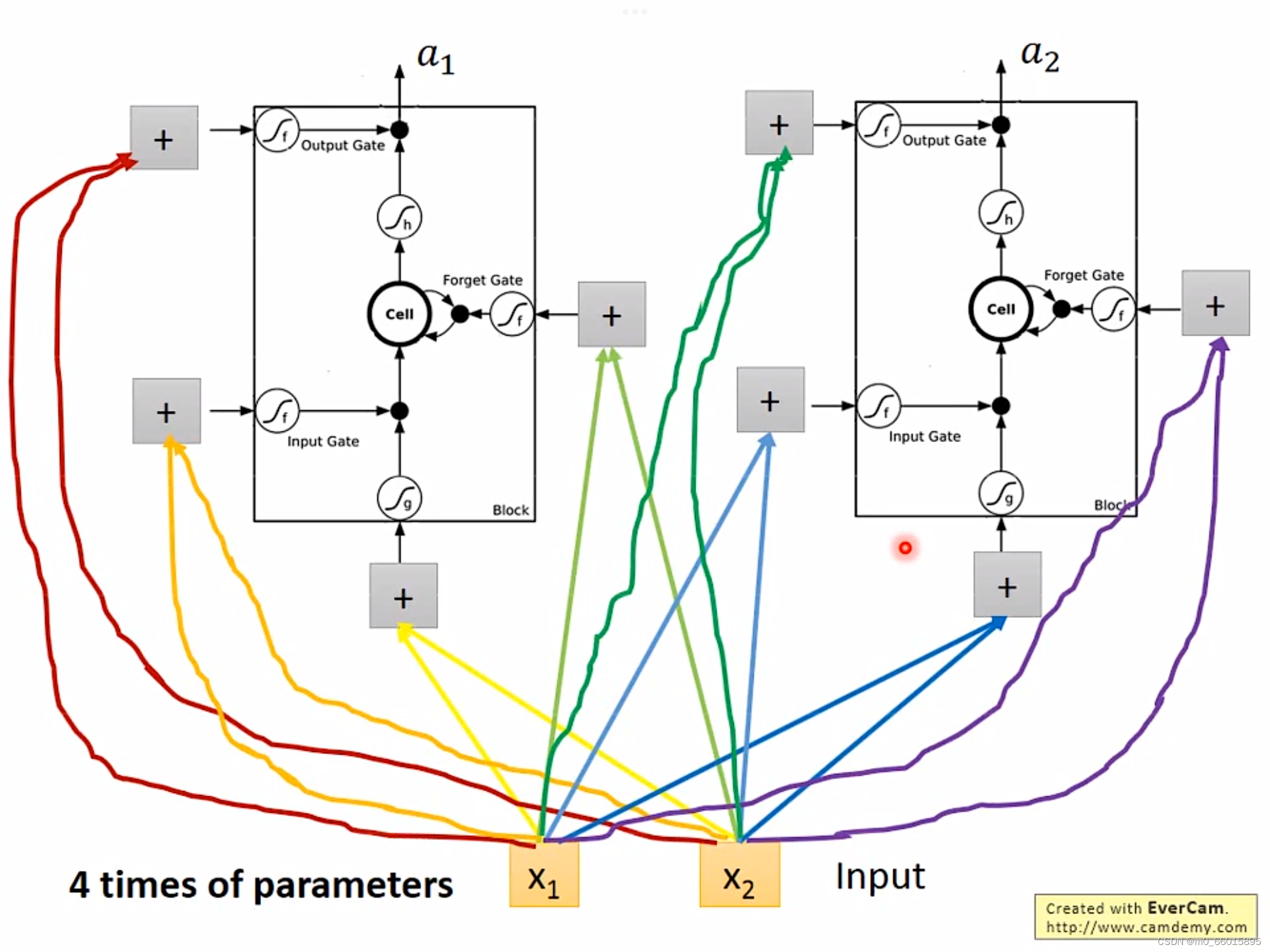
?将LSTM当做一个特殊的神经元,但是从图中可以看出LSTM比普通的神经元多了三个门,每个门都需要相应的参数,因此LSTM需要的参数量相当于普通神经元的4倍。
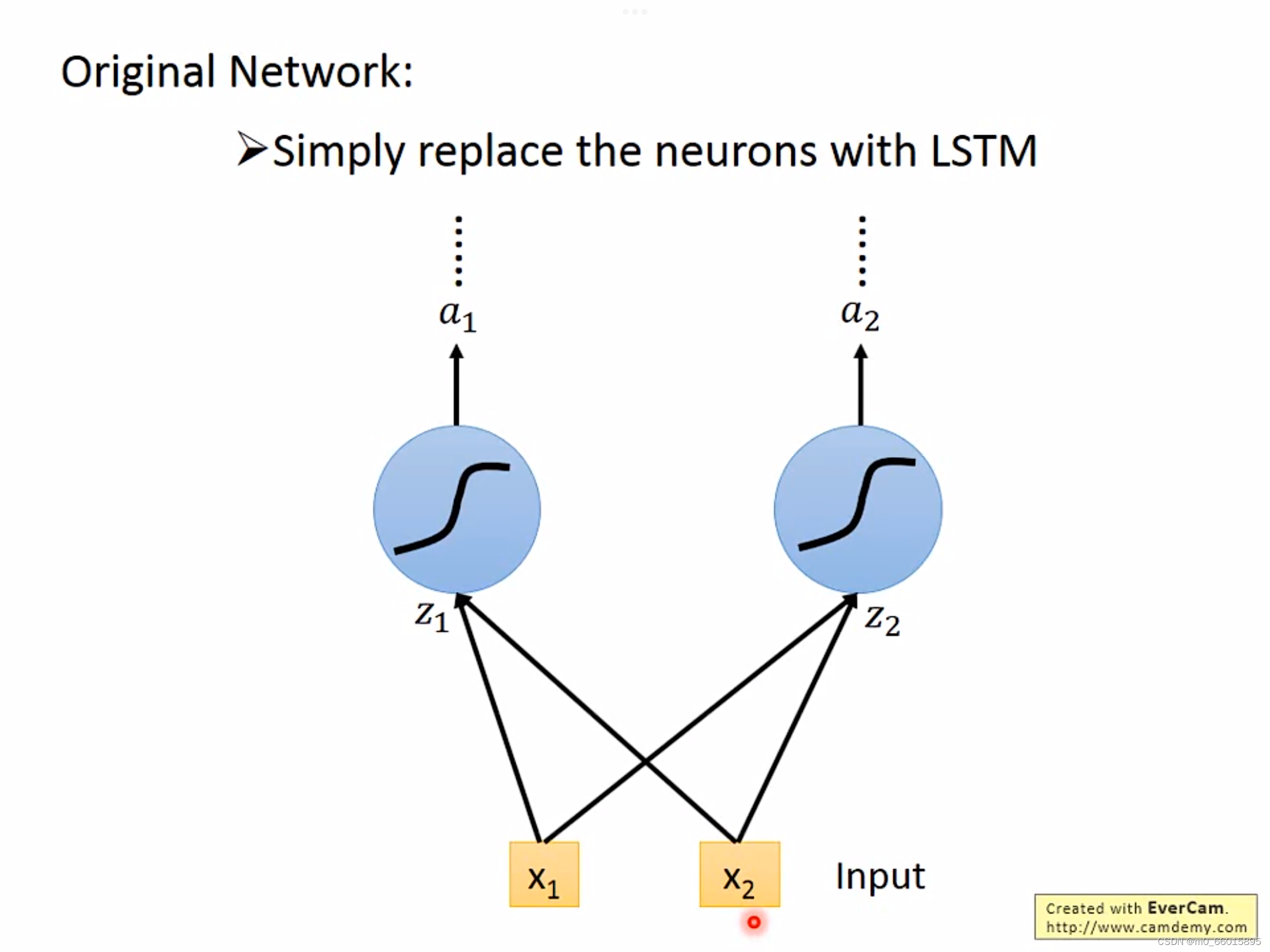
其实就是原来简单的neuron换成LSTM。
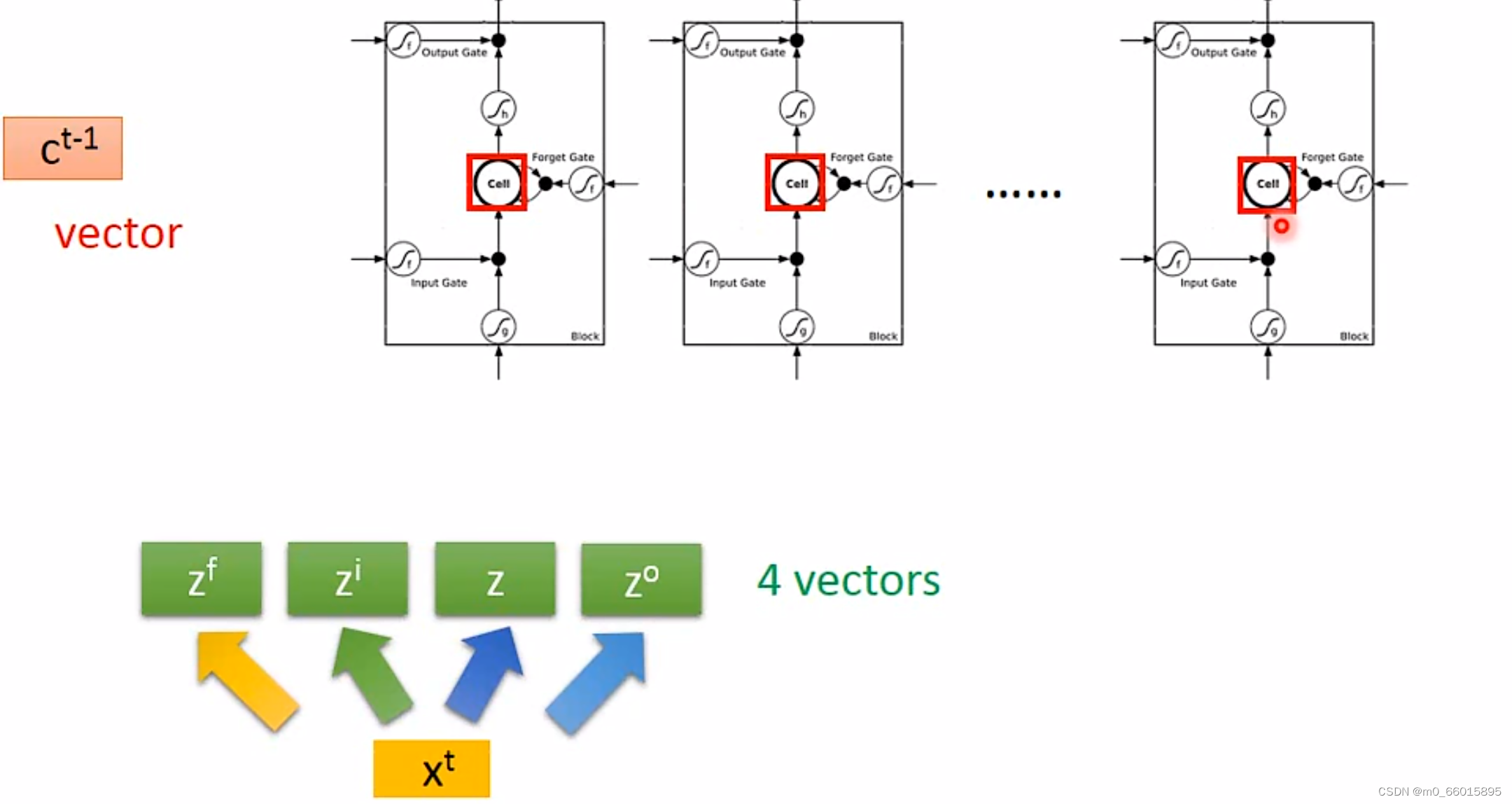
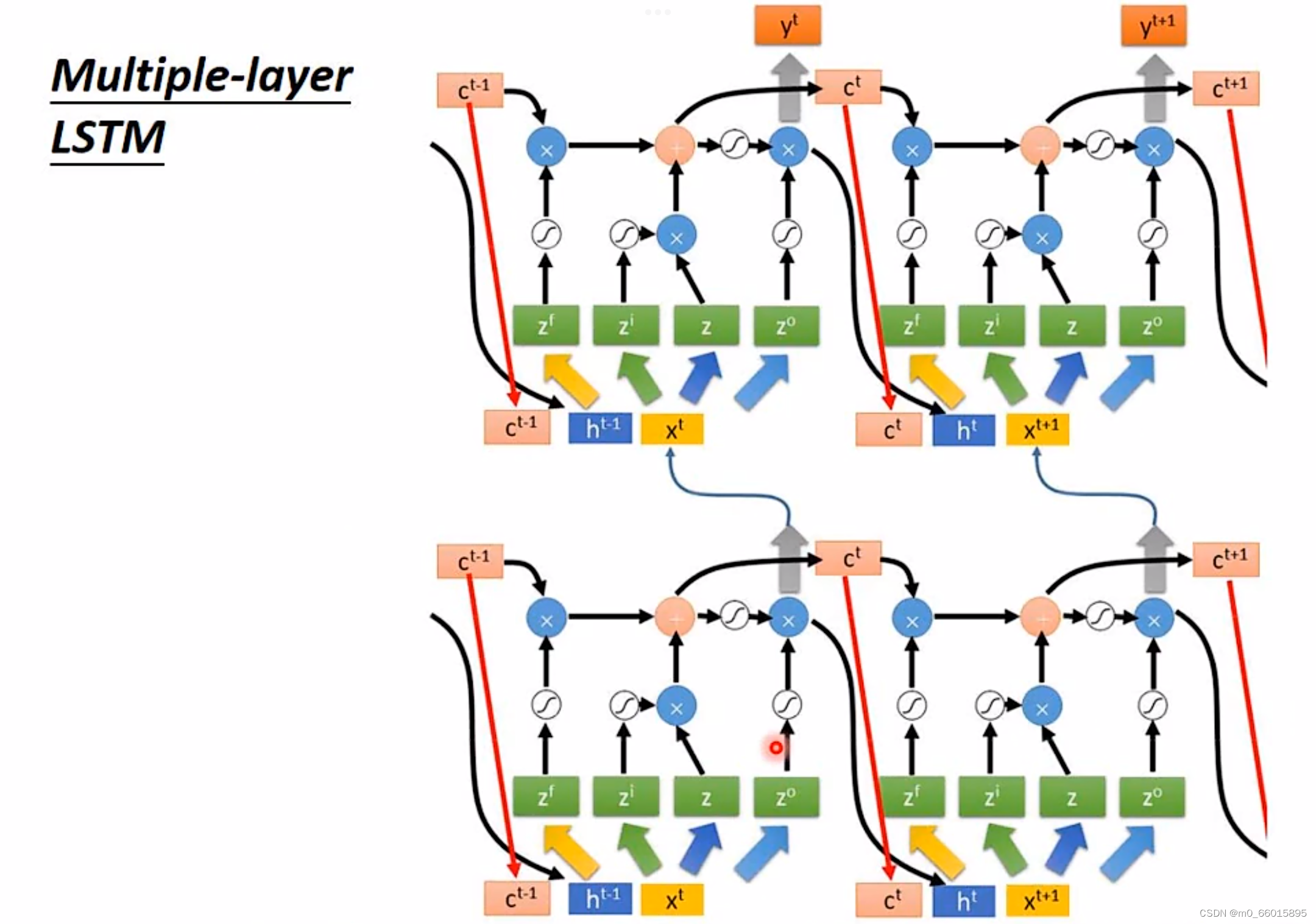
2. Multiple-layer LSTM
真正的 LSTM在输入的时候还会把 hidden layer 的输出 接上,还会加上上一个时间点 memory cell 的值?
?,再在经过不同的 transform 得到四个不同的 z vector 去控制 LSTM,LSTM 也不止一层,可以叠多层。
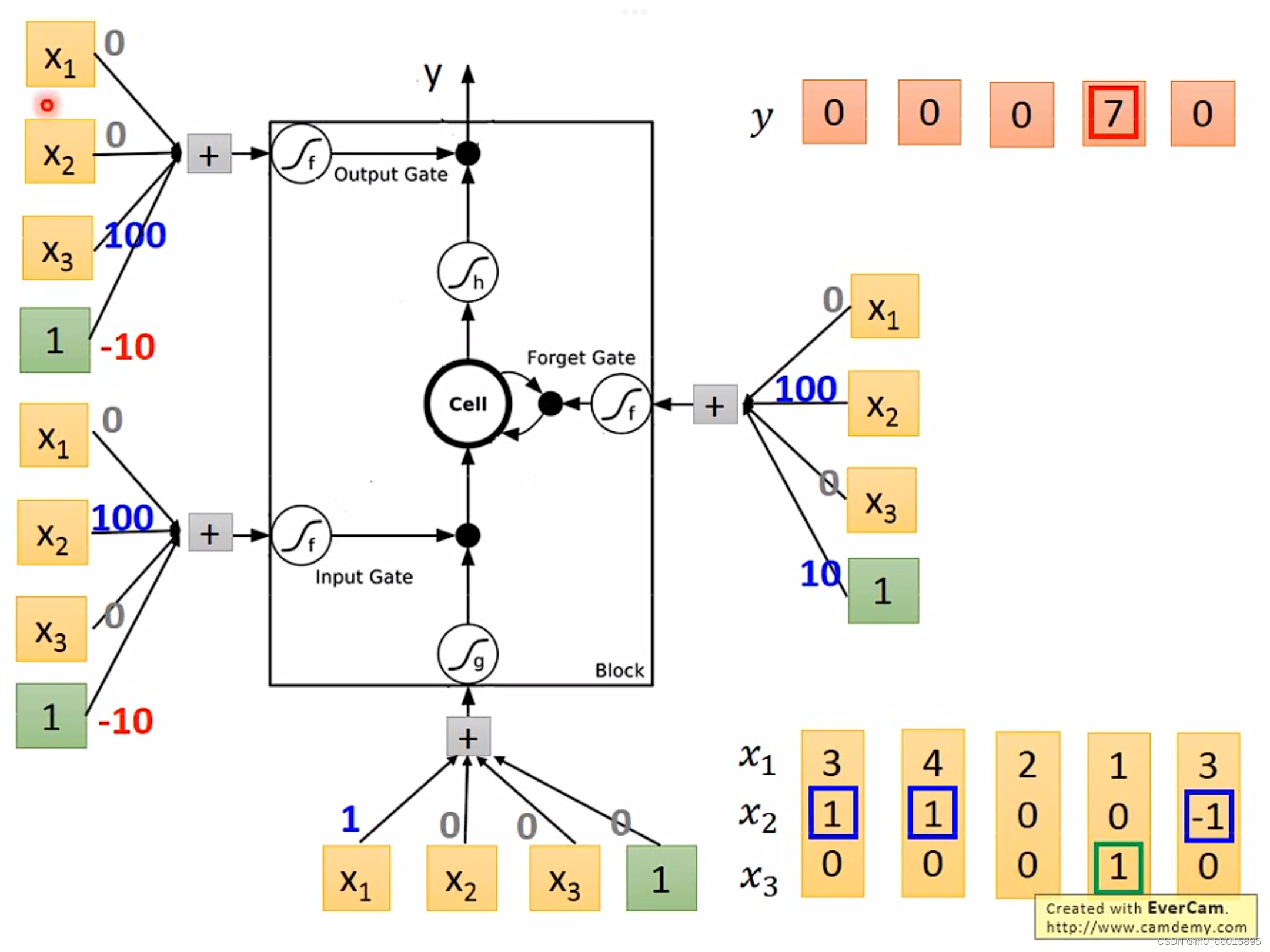
3.3 LSTM Example
当??的时候,将
的的值添加到memory;
当的时候,将memory中的值移除;
当的时候,输出memory里的值。

?以第一个序列为例,设置输入门的权重为100,偏差值为1权重为-10,也就是当
的值小于0.1即小于0,那么通过sigmoid函数之后输入门的值就接近0,代表门被关闭,否则可以将
的值存入memory,同理可知输出门和遗忘门的权重设置,但遗忘门的偏差为10,通常是被打开的,只有当
的值为一个很大的负数的时候才会被关闭。序列1输入,memory存的值不变,并且输出门值为0不输出,序列2输入将
的值3保存到memory,但输出门为0,memory的值不输出,序列3输入,将将
的值4保存到memory,此时memory的值为3+4=7,输出门不为0,输出memory中的值7。
3. GRU
LSTM是RNN的升级版,加了门控装置,解决了长时记忆依赖的问题。但由于参数量复杂,带来了计算量增加,所以引进了简化版的LSTM,即GRU。
GRU在LSTM的基础上减少了一个门,即用更新门代替了遗忘门和输出门,其参数更少,训练相对简单一点。而从效果上说,二者并没有优劣之分,取决于具体的任务和数据集而定。实际上来讲,二者的表现差距往往不大,远远没有调参效果明显。
LSTM实现PM2.5预测
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# # 打印出Seaborn库中内置的所有数据集列表
# datasets_name = sns.get_dataset_names()
# print("ALL DATASET:", datasets_name)
#
# # 加载航班数据集
# flight_data = sns.load_dataset("flights")
# flight_data.head()
data = pd.read_excel('../DataSet/PRSA_data_2010.1.1-2014.12.31(Updated_data).xlsx')
# print(data, type(data))
# 将 PM2.5 列的数据改为浮点型存入 all_data 中
all_data = data['PM2.5'].values.astype(float)
# 将列 TIME-HOUR 转换为日期格式
data['TIME-HOUR'] = pd.to_datetime(data['TIME-HOUR'])
# data 的列类型是对象
# print(data.head(), data.shape, data.columns)
# data 是一个 numpy 二维数组
# print(data)
# 划分33824个训练集和10000测试集
test_data_size = 10000
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
# print(len(train_data))
# print(len(test_data))
# 归一化,注意 fit_transform 方法的输入必须是一个二维的数组
# 训练集和测试集不要一起归一化,就是说不要先归一化再划分数据集,先将数据集划分后再分别进行归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler.fit_transform(test_data.reshape(-1, 1))
# 印出归一化训练数据的前5条和后5条记录
# print(train_data_normalized[:5])
# print(train_data_normalized[-5:])
# 将数据集转换为张量
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
test_data_normalized = torch.FloatTensor(test_data_normalized).view(-1)
# print(train_data_normalized)
# 将训练数据转换为序列和相应的标签
# 可以使用任何序列长度,取决于领域知识,比如说数据是按月份收集的就将序列长度设为12(一年12个月),如果数据是按天数收集的就将序列长度设为365(一年365天)
# 本数据集是按小时收集的,所以设定序列长度为 30 * 24 (按月来设定窗口)
train_window = 30 * 24
# 定义一个名为create_inout_sequences的函数
# 该函数将接受原始输入数据,并返回一个元组列表
# 在每个元组中,第一个元素将包含 30 * 24 个项目的列表,对应于前1个月内每个小时的 PM2.5 的排放量,第二个元素将包含一个项目的列表即第2个月的第一个小时的 PM2.5 的排放量
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq, train_label))
return inout_seq
# 创建训练序列
train_input_seq = create_inout_sequences(train_data_normalized, train_window)
# print(train_inout_seq[:5])
class LSTM(nn.Module):
# input_size:对应于输入中特征的数量,数据集中只有 PM2.5 这一个特征
# hidden_layer_size:指定隐藏层的数量以及每层神经元的数量
# output_size:输出中项目的数量,本项目中只预测未来一个小时内的 PM2.5 的量,因此输出大小将为1
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
# self.hidden_cell:这是 LSTM 层的隐藏状态
# LSTM 层是一种循环神经网络(RNN),它在处理序列数据时会维护一个隐藏状态,用于捕获序列中的时间相关性
# input_seq:这是输入到 LSTM 层的数据序列
# 在这里,input_seq 被视为一个三维张量,其形状为 (sequence_length, batch_size, input_size)
# 其中 sequence_length 表示序列的长度,batch_size 表示批次大小,input_size 表示输入特征的数量
# view(len(input_seq), 1, -1):这是一个 PyTorch 的操作,用于重新排列输入张量的维度
# 具体来说,它将输入张量的维度从 (sequence_length, input_size) 重新排列为 (sequence_length, 1, input_size)
# 这是因为 LSTM 层期望输入数据具有这种形状,其中第二个维度通常用于批次大小,这里 1 表示批次大小为 1
# lstm_out 的形状为 (sequence_length, batch_size, hidden_size)
# 预测出来的 PM2.5 的量存储在 predictions 列表中最后一个项目中,并返回给调用函数
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
# print(lstm_out.shape)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
# 创建 LSTM() 类对象、定义损失函数和优化器
# 损失函数:交叉熵损失
# 优化器:Adam
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# print(model)
# 模型训练
epochs = 1
for i in range(epochs):
for seq, labels in train_input_seq:
optimizer.zero_grad()
# 初始化LSTM模型的隐藏状态和细胞状态
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
# {i:3} 是一个占位符,它表示要在这个位置插入一个整数 i,并且将其格式化为占据3个字符的宽度
# 这意味着无论 i 是多少,都会占据3个字符的位置,不足的部分用空格填充
# {single_loss.item():10.8f} 是另一个占位符,它表示要在这个位置插入一个浮点数 single_loss.item(),并将其格式化为占据10个字符的宽度
# 其中包括小数点和8位小数,这会以固定的宽度显示损失值
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
# 模型泛化
test_input_seq = create_inout_sequences(test_data_normalized, train_window)
predictions = []
for seq, labels in test_input_seq:
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
prediction = model(seq)
predictions.append(scaler.inverse_transform(np.array(prediction).reshape(-1, 1)))
print(len(predictions), type(predictions))
print(len(test_data[train_window:]), type(test_data[train_window:]))
print("------------------------------------------------------")
# 创建x轴的值(可以是范围或自定义值)
x_values = np.arange(len(predictions))
# 匹配 prediction 与 test_data[train_window:] 的维度
predictions = np.array(predictions)
print(predictions.shape)
print(test_data[train_window:].shape)
print("------------------------------------------------------")
print(predictions.reshape(-1))
print(test_data[train_window:])
# 绘制预测值的图形
plt.plot(x_values, predictions.reshape(-1), label='Forecast values', linestyle='-', color='red', marker='')
# 绘制真实值的图形
plt.plot(x_values, test_data[train_window:], label='True Values', linestyle='-', color='blue', marker='')
# 添加图例
plt.legend()
# 设置图形标题和轴标签
plt.title('True vs. predicted values')
plt.xlabel('Time')
plt.ylabel('PM2.5')
# 显示图形
plt.show()原始数据图像:
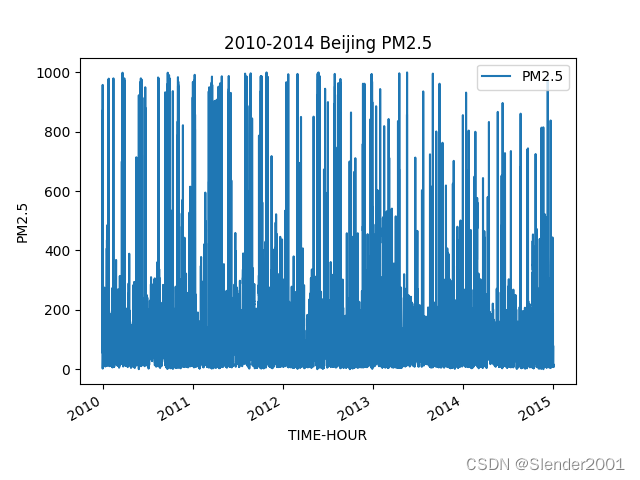 ?
?
测试集预测数据图像:(受限于设备性能,epoch次数很少,导致测试结果很差)
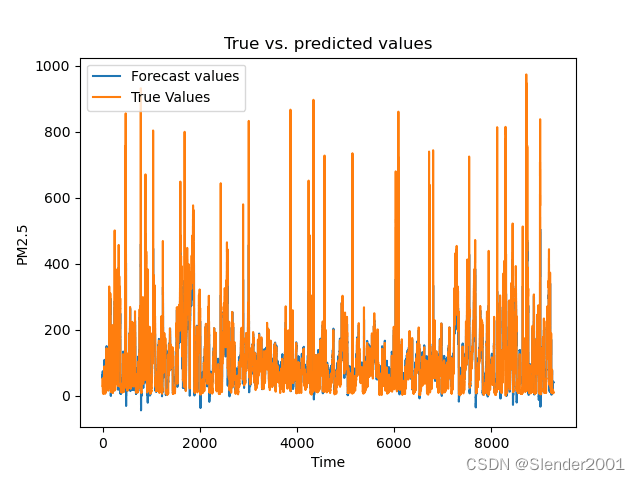
总结
这周学习了RNN以及LSTM,不同于以往CNN等结构,RNN在全连接网络上加上了记忆功能,基础的神经网络只是在层与层之间建立了权值连接,而RNN在层之间的神经元之间也建立了权值连接,它能够处理序列变化的数据。而LSTM又在RNN的基础上加上了记忆定义的概念,在RNN中只会针对比较短的序列进行操作,而比较长的序列一般使用LSTM,LSTM适合处理序列中间间隔和延迟相对较长的问题,解决在长序列训练过程中梯度消失的问题,例如聊天机器人、语音识别等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!