pytorch中.to(device) 和.cuda()的区别
在PyTorch中,使用GPU加速可以显著提高模型的训练速度。在将数据传递给GPU之前,需要将其转换为GPU可用的格式。
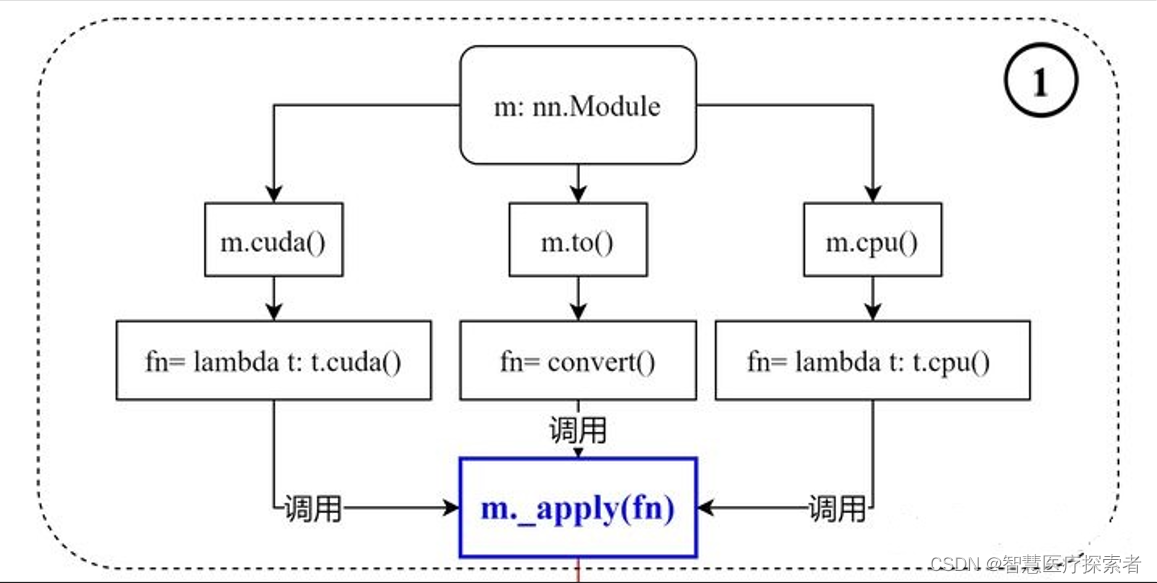
函数原型如下:
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
return self._apply(lambda t: t.cuda(device))
def cpu(self: T) -> T:
return self._apply(lambda t: t.cpu())
def to(self, *args, **kwargs):
...
def convert(t):
if convert_to_format is not None and t.dim() == 4:
return t.to(device, dtype if t.is_floating_point() else None, non_blocking, memory_format=convert_to_format)
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
return self._apply(convert)1 .to(device)
.to(device)是PyTorch中的一个方法,可以将张量、模型转换为指定设备(如CPU或GPU)可用的格式。示例代码如下:
import torch
# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)
# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.to(device)
print(x)?运行结果如下:
tensor([[1., 2., 3.],
[4., 5., 6.]])
tensor([[1., 2., 3.],
[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.to(device)将其转换为GPU可用的格式。其中,device是一个torch.device对象,可以使用torch.cuda.is_available()函数来判断是否支持GPU加速。
import torch
from torch import nn
from torch import optim
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net()
# 将模型参数和优化器转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
print(net)
optimizer = optim.SGD(net.parameters(), lr=0.01)运行结果显示如下:
Net(
(fc1): Linear(in_features=3, out_features=2, bias=True)
(fc2): Linear(in_features=2, out_features=1, bias=True)
)在上述代码中,首先创建了一个模型net,然后使用net.to(device)将其模型参数转换为GPU可用的格式。
2 .cuda()
.cuda()是PyTorch中的一个方法,可以将张量、模型转换为GPU可用的格式,示例代码如下:
import torch
# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)
# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.cuda()
print(x)运行结果显示如下:
tensor([[1., 2., 3.],
[4., 5., 6.]])
tensor([[1., 2., 3.],
[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.cuda()将其转换为GPU可用的格式。?
import torch
from torch import nn
from torch import optim
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net()
# 将模型参数和优化器转换为GPU可用的格式
net = net.cuda()
optimizer = optim.SGD(net.parameters(), lr=0.01)在上述代码中,首先创建了一个模型net,然后使用net.cuda()将模型转换为GPU可用的格式。
3 总结
推荐使用to(device)的方式,主要原因在于这样的编程方式更加易于扩展,而cuda()必须要求机器有GPU,否则需要修改所有代码;to(device)的方式则不受此限制,device既可以是CPU也可以是GPU;
4 pytoch介绍
PyTorch是一个开源的机器学习库,由Facebook的人工智能研究团队开发。自推出以来,它迅速成为科研和工业界最受欢迎的深度学习工具之一。PyTorch以其简洁的界面、灵活性和强大的计算能力在学术和工业界广受好评。
PyTorch凭借其用户友好的界面、强大的功能和灵活的架构,在机器学习领域赢得了广泛的认可。它不仅适合科研,也适合工业级应用的开发,是深度学习研究和应用的重要工具之一。
4.1 核心特性
-
动态计算图: PyTorch使用动态计算图(也称为即时执行),这意味着图是按照我们的代码方式运行时创建的,使得模型更加灵活,易于调试。
-
Python友好: 完全集成到Python中,易于学习,支持大量的Python库,如NumPy。
-
模块化和可重用性: 提供了丰富的预构建模块和层,使得构建和训练深度学习模型更加简单。
-
GPU加速: 支持CUDA,可以利用NVIDIA GPU来加速神经网络的训练。
-
扩展性: 容易进行扩展和修改,可以通过自定义操作来增加新功能。
-
丰富的API: 提供了丰富的API用于数据加载、模型构建、优化和训练。
4.2 应用领域
-
计算机视觉: 用于图像分类、物体检测、图像分割等任务。
-
自然语言处理: 广泛应用于机器翻译、文本分类、情感分析等领域。
-
强化学习: 在游戏玩法、机器人控制等方面有应用。
-
生成模型: 用于训练生成对抗网络(GANs)和变分自编码器(VAEs)。
4.3 社区和生态系统
-
开源文化: PyTorch拥有一个活跃的开源社区,提供了大量的教程、工具和预训练模型。
-
广泛的支持: 许多顶尖的科研机构和科技公司都在使用PyTorch进行研究和开发。
-
集成项目: 与其他项目如TensorBoard、ONNX(开放神经网络交换格式)集成,以增强其功能。
4.4 性能和优化
-
自动微分: 提供了一个名为Autograd的强大自动微分系统,简化了模型的构建和训练过程。
-
分布式训练: 支持分布式训练,使得处理大规模数据集和模型训练更加高效。
-
高性能: 优化的底层代码确保了高效的计算性能。
4.5 使用体验
-
易于上手: 直观的API设计使得新手容易上手。
-
灵活性和动态性: 动态计算图极大地提高了模型设计和实验的灵活性。
-
调试友好: Python的原生调试工具可以直接用于PyTorch代码的调试。
4.6 未来发展
-
更广泛的应用: 随着AI技术的发展,PyTorch将在更多的行业和领域中找到应用。
-
持续的创新: 在深度学习和人工智能领域不断创新,引入新的功能和优化。
-
社区驱动的增长: 依托其庞大的社区,PyTorch将继续快速发展,推出新的特性和改进。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!