MySQL篇—自带物理克隆数据工具Clone插件介绍(第一篇,总共三篇)
? ? 各位小伙伴,今天我为大家介绍一下MySQL Clone Plugin这个插件,简单来说,就是MySQL 8.0.17版本之后的一个物理克隆数据工具,它能够帮助我们快速、高效地克隆或复制数据库,极大地简化了数据库迁移、备份和恢复的过程,让我们在处理大量数据时更加得心应手。
? ? 为了确保大家能够充分利用这个强大的工具,我们将分为三篇内容来详细介绍MySQL Clone Plugin。今天我们将从基础入手,首先深入探讨Clone的用途、使用的前提条件、存在的限制,以及它的备份原理。第二篇介绍Clone的本地克隆数据,第三篇介绍Clone的远程克隆数据,通过三篇的介绍我们将会深入了解这个插件是如何工作的,以及为什么它可以成为数据库管理员的得力助手。
? ? 希望大家通过今天的分享,能够更好地理解和掌握MySQL Clone Plugin。在接下来的内容中,我们将一起探索这个工具的奥秘,为我们的数据库管理之旅增添更多便利和效率。现在,让我们开始第一篇的旅程吧!
点赞和关注,是我写文案的动力源泉!

官方文档对Clone Plugin的详细介绍:
MySQL :: MySQL 8.0 Reference Manual :: 5.6.7 The Clone Plugin
clone插件介绍:
? ? MySQL8.0.17中引入的克隆插件允许在本地或从远程MySQL服务器实例中克隆数据(传输数据)。存储的数据的物理快照。InnoDB它包括架构、表、表空间和数据字典元数据。所述克隆数据包括一个功能齐全的数据目录,该目录允许使用用于MySQL服务器配置的克隆插件。
? ? Clone Plugin是MySQL 8.0.17引入的一个重大特性,主要还是为Group Replication服务。在Group Replication中,添加一个新的节点,差异数据的补齐是通过分布式恢复(Distributed Recovery)来实现的。
? ? 在MySQL 8.0.17之前,只支持一种恢复方式-Binlog。但如果新节点需要的Binlog已经被Purge了,这个时候,只能先借助于备份工具(XtraBackup,mydumper,mysqldump)做个全量数据的同步,然后再通过分布式恢复同步增量数据。实现添加节点的目的。
? ? 其竞争对手PXC,默认集成了XtraBackup进行State Snapshot Transfer(类似于全量同步),而MongoDB则更进一步,原生就实现了Initial Sync同步全量数据。从易用性来看,单就集群添加节点这一项而言,MySQL确实不如其竞争对手。客户体验上,还有很大的提升空间。
? ? 好在MySQL官方也正视到这个差距,终于在MySQL 8.0.17实现了Clone Plugin。当然,对于官方来说,实现这个特性并不算难,毕竟有现成的物理备份工具(MySQL Enterprise Backup)可供借鉴。
clone的用途:
1、SQL命令进行备份。
2、Slave节点快速搭建。
3、MGR节点快速扩充
clone Plugin与XtraBackup的对比:
ps:xtrabackup由Percona提供,开源工具,支持对InnoDB做热备,物理备份工具。余后将独论xtrabackup之妙,需者敬请关注,共赴知识之宴。
1、在实现上,两者都有FILE COPY和REDO COPY阶段,但Clone Plugin比XtraBackup多了一个PAGE COPY,由此带来的好处是,Clone Plugin的恢复速度比XtraBackup更快。
2、XtraBackup没有Redo Archiving特性,有可能出现未拷贝的Redo日志被覆盖的情况。
3、GTID下建立复制,无需额外执行set global gtid_purged操作。
使用clone(克隆数据)插件的前提条件:
1、使用clone(克隆数据)插件的donor(源库)和recipient(目标库)MySQL版本(包括小版本)必须一致并且都要在8.0.17版本以上,且都要安装Clone Plugin。不然会报错:
ERROR 3864 (HY000): Clone Donor MySQL version: 8.0.20 is different from Recipient MySQL version 8.0.19.
2、主机的操作系统和位数(32位,64位)必须一致。两者可根据version_compile_os,version_compile_machine参数获取。
3、字符集(character_set_server),校验集(collation_server),character_set_filesystem必须一致。
4、innodb_page_size(页大小)必须一致。会检查innodb_data_file_path中ibdata的数量和大小。
5、目前Clone Plugin(8.0.20)的实现,无论是Donor,还是Recipient,同一时间,只能执行一个克隆操作。后续会支持多个克隆操作并发执行。不然会报错:
ERROR 3634 (HY000): Too many concurrent clone operations. Maximum allowed - 1.
6、Recipient需要重启,所以其必须通过mysqld_safe或systemd等进行管理。如果是通过mysqld进行启动,实例关闭后,需要手动启动。不然会报错:
ERROR 3707 (HY000): Restart server failed (mysqld is not managed by supervisor process).
clone(克隆数据)插件的限制:
1、8.0.17到8.0.26版本在克隆期间,允许DML不会影响正在执行的事务,DDL会被克隆的backup lock阻塞。不过可以通过设置clone_ddl_timeout参数在克隆期间允许DDL不过会导致克隆失败,在8.0.27版本新增clone_block_ddl参数在克隆期间允许DDL同时不会导致克隆失败。
2、Clone Plugin不会拷贝Donor(源库)的配置参数。
3Clone Plugin不会拷贝Donor(源库)的二进制日志文件。
4、Clone Plugin只会拷贝InnoDB表的数据,对于其它存储引擎的表只会拷贝表结构(mysql8.0废除了MyISAM、MEMORY存储引擎)
5、Donor(源库)实例中如果有表通过DATA DIRECTORY指定了绝对路径,在进行本地克隆时,会提示文件已存在。在进行远程克隆时,绝对路径必须存在且有可写权限。
6、不允许通过MySQL Router连接到Donor(源库)实例。
7、执行CLONE INSTANCE操作时,指定的Donor端口不能为X Protocol端口。
clone插件克隆数据的两种方式:
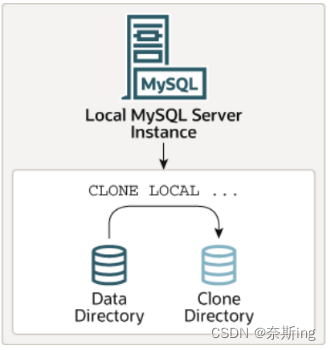
(1)本地克隆数据
? ? 本地克隆操作从MySQL服务器实例中克隆数据,其中克隆操作启动到MySQL服务器实例运行的同一服务器或节点上的目录。
语法:
CLONE?LOCAL DATA DIRECTORY [=] 'clone_dir';????---用户需要有BACKUP_ADMIN权限
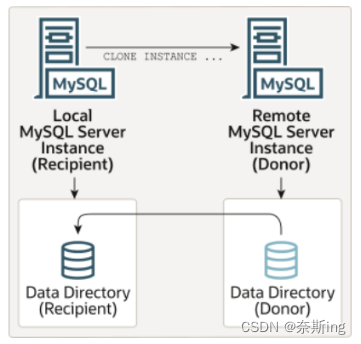
(2)远程克隆数据
? ? 远程克隆操作涉及本地MySQL服务器实例(“recipient”)启动克隆操作的服务器,以及远程MySQL服务器实例(“donor”)源数据所在的位置。当对接收方启动远程克隆操作时,克隆的数据将通过网络从donor传输到recipient。默认情况下,远程克隆操作将删除recipient数据目录中的数据,并将其替换为已克隆的数据。还可以选择将数据复制到recipient上的其他目录,以避免删除现有数据。
语法:
CLONE?INSTANCE FROM 'user'@'host':port
IDENTIFIED BY 'password'
[DATA DIRECTORY [=] 'clone_dir']
[REQUIRE [NO] SSL];?????---用户需要有BACKUP_ADMIN权限
DATA DIRECTORY:是一个可选子句,用于在接收端指定要克隆的数据的目录。如果不想删除recipient原数据目录中的现有数据,可以使用此选项修改数据copy的目录,必须有绝对路径,且目录必须不存在。不指定的话,则默认克隆到Recipient的数据目录下。
[REQUIRE [NO] SSL]:显式指定在通过网络传输克隆数据时是否使用加密连接。如果不能满足显式规范,则返回错误。如果未指定SSL子句,克隆将在默认情况下尝试建立加密连接,如果安全连接尝试失败,则返回到不安全连接。无论是否指定此子句,克隆加密数据时都需要安全连接。
Clone plugin备份原理:
MYSQL> select * from performance_schema.clone_progress;?
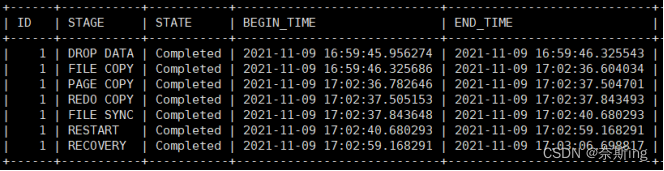
克隆操作可细分为以下5个阶段:
[INIT] ---> [FILE COPY] ---> [PAGE COPY] ---> [REDO COPY] -> [Done]
第一阶段:INIT
初始化一个克隆对象。需要持有backup lock, 阻止ddl进
第二阶段:FILE COPY(DROP DATA、FILE COPY)
按照文件进行拷贝,同时开启page tracking功能,记录在拷贝过程中修改的page, 此时会设置buf_pool->track_page_lsn为当前lsn,track_page_lsn在flush page阶段用到:
buf_flush_page: if (!fsp_is_system_temporary(bpage->id.space()) && buf_pool->track_page_lsn != LSN_MAX) { page_t *frame; lsn_t frame_lsn; frame = bpage->zip.data; if (!frame) { frame = ((buf_block_t *)bpage)->frame; } frame_lsn = mach_read_from_8(frame + FIL_PAGE_LSN); //对于在track_page_lsn之后的page, 如果frame_Lsn大于track_page_lsn, 表示已经记录下page id了,无需重复记录 arch_page_sys->track_page(bpage, buf_pool->track_page_lsn, frame_lsn, false); // 将page id记录下来,表示在track_page_lsn后修改过的page } 会创建一个后套线程page_archiver_thread(),将内存记录的page id flush到disk上
第三阶段:PAGE COPY(PAGE COPY)
这里有两个动作:
? ? (1)开启redo archiving功能,从当前点开始存储新增的redo log,这样从当前点开始所有增量修改都不会丢失.
? ? (2)同时上一步在page track的page被发送到目标端。确保当前点之前所做的变更一定发送到目标端
关于redo archiving,实际上这是官方早就存在的功能,主要用于官方的企业级备份工具,但这里clone利用了该特性来维持增量修改产生的redo。在开始前会做一次check point,开启一个后台线程log_archiver_thread()来做日志归档。当有新的写入时(notify_about_advanced_write_lsn)也会通知他去archive当arch_log_sys处于活跃状态时,他会控制日志写入以避免未归档的日志被覆盖(log_writer_wait_on_archiver), 注意如果log_writer等待时间过长的话,archive任务会被中断掉。
第四阶段:REDO COPY(REDO COPY)
停止Redo Archiving", 所有归档的日志被发送到目标端,这些日志包含了从page copy阶段开始到现在的所有日志,另外可能还需要记下当前的复制点,例如最后一个事务提交时的binlog位点或者gtid信息,在系统页中可以找到
第五阶段:Done(FILE SYNC、RESTART、RECOVERY)
目标端重启实例,通过crash recovery将redo log应用上去。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!