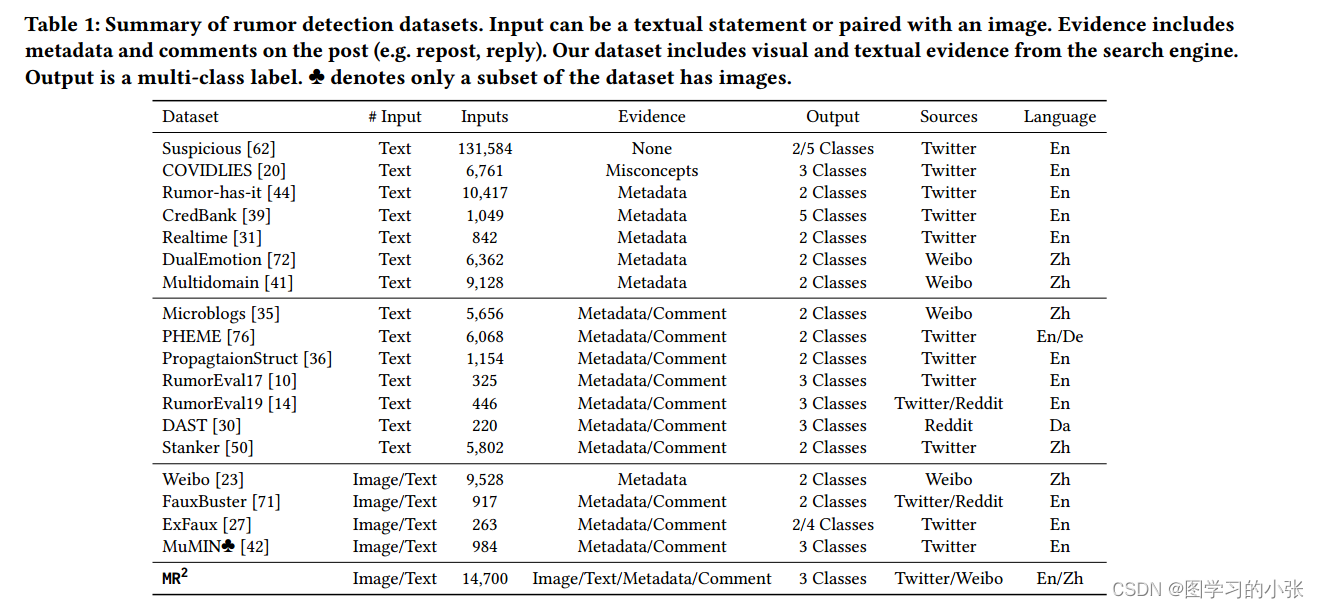
谣言检测常用数据集汇总
Pheme-R
获取地址:https://figshare.com/articles/dataset/PHEME_rumour_scheme_dataset_journalism_use_case/2068650
PHEME社交媒体谣言数据集:这些谣言与9条不同的突发新闻有关。它是为分析社交媒体谣言而创建的,并包含由谣言推文发起的推特对话;这些对话包括对那些谣言推文的回应。这些推文都经过注释,以获得支持、确定性和证据性。
数据集结构:
该数据集包含330个会话线程(297个英语线程,33个德语线程),每个线程都有一个文件夹,结构如下:
*source-tweets:这个文件夹包含一个json文件(源tweets)。
*reactions:这个文件夹包含所有tweets的json文件,通过回复参与对话。
*url-content:此文件夹包含从tweet指向的网页的内容。
*structure.json:该文件提供了对话的结构,从而更容易确定每个tweet的子tweet是什么,并通过将源tweet和回复放在一起来重建对话。
*retweets.json:该文件包含转发源tweet的tweet。
*who-following-whom.dat:该文件包含线程中正在关注其他人的用户。每行包含两个ID,表示具有第一个ID的用户跟随具有第二个ID的用户。注意,following不是对等的,因此,如果两个用户相互关注,那么它将被表示为两行,A B和B A。
*注释。该文件包含线程级别的手动注释,这对谣言特别有用,并包含以下字段:
** is_rumor:是谣言还是非谣言。
** category:描述谣言故事的标题,可用于与同一故事中的其他谣言分组。
** misinformation:0或1。它确定这个故事后来是否被证明是假的,在这种情况下设置为1,否则设置为0。
** true: 0或1。它确定该故事后来是否被证实为真的,在这种情况下设置为1,否则设置为0。
** is_turnaround: 0或1。如果一个帖子代表了谣言故事的转变,那么它就被标记为一个转折,要么在真实故事的情况下被证实,要么在虚假故事的情况下被揭穿。
** links:如果有,这包含了一个覆盖谣言故事的链接列表,其中包括链接的URL,媒体类型(社交媒体,新闻媒体或博客),以及它是反对,支持还是观察谣言。
在这330个对话中的4,842条推文的推文级别执行的注释可以在两个文件中找到:
*annotations/en-scheme-annotations.json (for the English threads)
*annotations/de-scheme-annotations.json (for the German threads)
每行包含一条tweet,带有事件、线程和tweet标识符,以及支持、确定性和证据性的注释。
Pheme
获取地址:https://figshare.com/articles/PHEME_dataset_for_Rumour_Detection_and_Veracity_Classification/6392078
该数据集是2016年发布的Pheme谣言和非谣言数据集(https://figshare.com/articles/PHEME_dataset_of_rumours_and_non-rumours/4010619)的延伸,它包含了与9个事件相关的谣言,每个谣言都被标注了其真实性值,即真、假或未验证。
Weibo、Twitter
获取地址:http://alt.qcri.org/~wgao/data/rumdect.zip
-
推特数据
Twitter.txt:该语料库总共包含992个标记事件。每行包含一个事件,其中包含相关推文的 ID:event_id、标签tweet_ids。对于标签,如果事件是谣言,则值为 1,否则为 0。请注意,由于 Twitter 数据的使用条款,我们无法发布推文的具体内容。用户可以通过 Twitter API 自行下载内容。
Twitter_event_claims.txt:此文件提供每个事件的主要声明的内容。每行包含一个事件,其声明由event_id和声明内容组成。 -
微博数据(Weibo.txt):该语料库共包含4664个标记事件。每行包含一个事件,其中包含相关帖子的 ID,格式为:event_id、标签post_ids。对于标签,如果事件是谣言,则值为 1,否则为 0。我们还以json格式发布所有帖子的内容,这些内容保存在./Weibo目录下,其中每个文件都命名为event_id.json,对应单个事件。
FakeNewsNet
获取地址:https://github.com/KaiDMML/FakeNewsNet
FakeNewsNet 包含 2 个数据集,这些数据集使用来自 Politifact 和 Gossipcop 的事件。
Twitter15、Twitter16
获取地址:https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
数据集结构:
主目录包含两个 Twitter 数据集的目录:twitter15 和 twitter16。在每个目录中,都有:
-‘tree’ 子目录:此文件夹包含所有树文件,每个文件都对应给定源推文的树结构,其文件名由源推文 ID 指示。在树文件中,每行表示一条边,格式如下:
** 父节点 ->子节点
** 每个节点都以元组形式给出:[‘uid’, ‘tweet ID’, ‘post time delay (in minutes)’]
-label.txt 文件:此文件以如下格式提供树的真值标签:
** ‘label:源推文 ID’
-source_tweets.txt文件:此文件以如下格式提供树的源帖子内容:
** ‘源推文 ID t 源推文内容’
MR^2
SIGIR2023提出的新数据集,用于谣言检测的多模态多语言检索增强数据集。现有的数据集大多集中在单一的模态,为了将检索到的文本和图像作为更好的错误信息检测的证据。首先使用文章中的图像,通过反向图像搜索找到其他出现的图像。然后检索文本证据(即描述)并将其与帖子中的文本进行比较。同样地,使用文本来寻找其他图像作为视觉证据。包含从twitter和weibo上的中英文帖子。
获取地址:https://github.com/THU-BPM/MR2
数据集信息汇总
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!