朴素贝叶斯 朴素贝叶斯原理
朴素贝叶斯 朴素贝叶斯原理
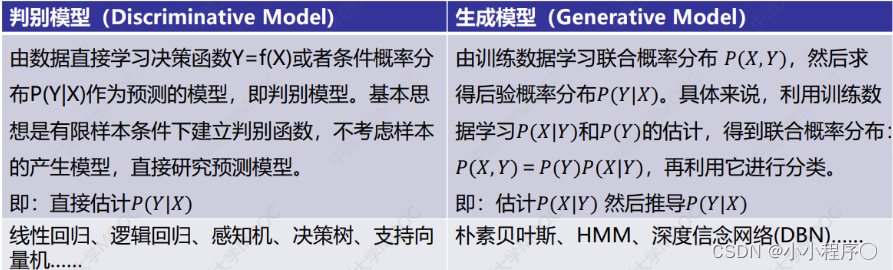
判别模型和生成模型
- 监督学习方法又分生成方法 (Generative approach) 和判别方法 (Discriminative approach)所学到的模型分别称为生成模型 (Generative Model) 和判别模型 (Discriminative Model)。
朴素贝叶斯原理
-
朴素贝叶斯法是典型的生成学习方法。生成方法由训练数据学习联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),然后求得后验概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)。具体来说,利用训练数据学习 P ( X ∣ Y ) P(X|Y) P(X∣Y)和 P ( Y ) P(Y) P(Y)的估计,得到联合概率分布:
P ( X , Y ) = P ( Y ) P ( X ∣ Y ) P(X,Y)=P(Y)P(X|Y) P(X,Y)=P(Y)P(X∣Y)
概率估计方法可以是极大似然估计或贝叶斯估计。
-
朴素贝叶斯法的基本假设是条件独立性
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , ? ? , X ( n ) = x ( n ) ∣ Y = c k ) = ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) \begin{aligned} P(X&=x | Y=c_{k} )=P\left(X^{(1)}=x^{(1)}, \cdots, X^{(n)}=x^{(n)} | Y=c_{k}\right) \\ &=\prod_{j=1}^{n} P\left(X^{(j)}=x^{(j)} | Y=c_{k}\right) \end{aligned} P(X?=x∣Y=ck?)=P(X(1)=x(1),?,X(n)=x(n)∣Y=ck?)=j=1∏n?P(X(j)=x(j)∣Y=ck?)?
由于这一假设,朴素贝叶斯法的学习与预测大为简化。因而朴素贝叶斯法高效,且易于实现。其缺点是分类的性能不一定很高。
-
朴素贝叶斯法利用贝叶斯定理与学到的联合概率模型进行分类预测。
P ( Y ∣ X ) = P ( X , Y ) P ( X ) = P ( Y ) P ( X ∣ Y ) ∑ Y P ( Y ) P ( X ∣ Y ) P(Y | X)=\frac{P(X, Y)}{P(X)}=\frac{P(Y) P(X | Y)}{\sum_{Y} P(Y) P(X | Y)} P(Y∣X)=P(X)P(X,Y)?=∑Y?P(Y)P(X∣Y)P(Y)P(X∣Y)? 将上述第2点的公式带入,由于各个概率的分母都是 ∑ Y P ( Y ) P ( X ∣ Y ) {\sum_{Y} P(Y)P(X | Y)} Y∑?P(Y)P(X∣Y)
所以后验概率最大的类 y y y为:
y = arg ? max ? c k P ( Y = c k ) ∏ j = 1 n P ( X j = x ( j ) Y = c k ) y=\arg \max _{c_{k}} P\left(Y=c_{k}\right) \prod_{j=1}^{n} P\left(X_{j}=x^{(j)} Y=c_{k}\right) y=argck?max?P(Y=ck?)j=1∏n?P(Xj?=x(j)Y=ck?)后验概率最大等价于0-1损失函数时的期望风险最小化。
GaussianNB 高斯朴素贝叶斯
特征的可能性被假设为高斯
概率密度函数:
P
(
x
i
∣
y
k
)
=
1
2
π
σ
y
k
2
e
x
p
(
?
(
x
i
?
μ
y
k
)
2
2
σ
y
k
2
)
P(x_i | y_k)=\frac{1}{\sqrt{2\pi\sigma^2_{yk}}}exp(-\frac{(x_i-\mu_{yk})^2}{2\sigma^2_{yk}})
P(xi?∣yk?)=2πσyk2??1?exp(?2σyk2?(xi??μyk?)2?)
数学期望(mean): μ \mu μ
方差: σ 2 = ∑ ( X ? μ ) 2 N \sigma^2=\frac{\sum(X-\mu)^2}{N} σ2=N∑(X?μ)2?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!