ASP.NET Core面试题之Redis高频问题
🎈🎈在.NET后端开发岗位中,如今也少不了、微服务、分布式、高并发高可用相关的面试题🎈🎈
👍👍本文分享一些整理的Redis高频面试题🎉
👍👍机会都是给有准备的人的,祝你一面而就🎉
1. 为什么项目选择使用Redis?优缺点是什么?
Redis 是一个基于内存的高性能key-value数据库。Redis优势:
-
性能极高 – Redis以内存作为数据存储介质,读的速度是110000次/s,写的速度是81000次/s 。Redis高性能是因为:1. 纯内存操作 2.单线程操作,避免了频繁的上下文切换 3.采用了非阻塞 I/O 多路复用机制
-
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
-
原子操作 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行(事务)。
-
丰富的特性 – Redis还支持发布/订阅(publish/subscribe)、通知、键值(Key)过期等等特性。
Redis的缺点也必须了解:
- Redis缓存和数据库,数据一致性的问题
- 使用Redis会产生击穿、穿透、雪崩的问题,在程序中解决这些问题。
2.Redis宕机后重启数据不丢失怎么做到的?
Redis跟普通的内存缓存不同的是,它有持久化机制,可以根据持久化策略把内存中的数据备份到磁盘中。宕机重启后,Redis服务器程序会把磁盘中的数据再重新写到内存中从而恢复数据。
3. Redis持久化的流程是什么?
- 第1步:客户端向服务端发送写操作(数据在客户端的内存中)
- 第2步:数据库服务端接收到写请求的数据(数据在服务端的内存中)。
- 第3步:服务端调用write方法,将数据往磁盘上写(数据在系统内存的缓冲区中)。
-
第4步:操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
- 第5步:磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
4. Redis的持久化策略有哪些?
有两种策略:RDB和AOF,可以在redis.conf的配置文件中设置。
AOF持久化:工作机制很简单,Redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是“日志记录”。AOF记录服务器的所有写操作,在服务器重新启动的时候,会把所有的写操作重新执行一遍,从而实现数据备份。

AOF存在的问题及解决方案:AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩AOF的持久化文件,Redis提供了bg rewrite aof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。(以上文件重写机制要着重了解一下)
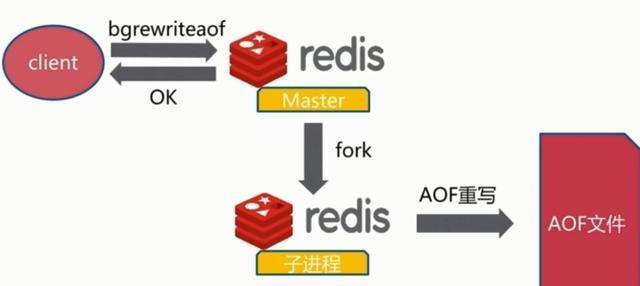
RDB持久化:RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,是一种全量备份方式。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。服务器启动的时候,可以从 RDB 文件中恢复数据集。
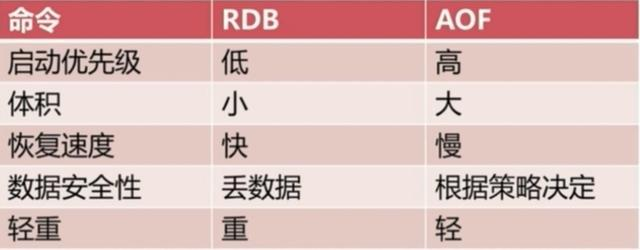
5. AOF和RDB有什么区别?该用哪一个?
两种持久化方式怎么选?需求不同选择不同,但是通常都是结合使用。两者的对比看下图:
6. Redis和本地缓存之间的区别?
-
相同点:Redis和本地缓存(MemoryCache)都是将数据存放在内存中,都是内存数据库。
-
数据类型:Redis不仅支持简单的k/v类型的数据(string类型),同时还提供list,set,hash等数据结构的存储;本地缓存没有那么丰富的数据类型,通常仅支持简单k/v类型数据。
-
持久化功能:Redis有数据持久化功能,而本地缓存没有持久化功能;
-
应用场景不一样:Redis除了作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;本地缓存适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
7. Redis的常用的数据类型及应用场景?
- 字符串(String): 最基本的数据类型,可以存储字符串、整数或浮点数。场景:缓存Session会话,计数器,流水号等。
- 哈希/散列/字典(Hash):键值对的集合,可以在一个哈希数据结构中存储多个字段和值。场景:存电商的购物车信息
- 列表(List):按照插入顺序存储一组有序的值,可以在列表的两端执行插入、删除和访问操作。场景:用作简单的消息队列。
- 集合(Set):无序的唯一值集合。场景:实现抽奖,文章的点赞、评论。
- 有序集合(Sorted?Set):可以根据分数对成员进行排序,同时保持唯一性。场景:实现体育赛事排行榜,游戏积分榜,热销商品排行榜。
8.Redis集群模式有哪些?
三种集群模式:主从模式、哨兵模式、Cluster集群模式。
?
9. Redis和其它数据库(MySql\Sql Server等)的区别
MySql是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
Sql Server是关系型数据库,读取速度较慢、只能运行在windows平台,难处理高并发等性能问题。
Redis是NoSQL即非关系型数据库,也是缓存数据库,即将数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率,但是保存时间有限。
10.? Redis的缓存穿透问题及解决方案
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到对应key的value,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库。
解决方案:
- 缓存空值:如果一个查询返回的数据为空(不管是数据不存在,还是系统故障)我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过5分钟。
-
采用布隆过滤器(Bloom Filter):在缓存之前在加一层BloomFilter,在查询的时候先去BloomFilter去查询key是否存在,如果不存在就直接返回,存在再去查询缓存,缓存中没有再去查询数据库。
11.? Redis的缓存雪崩问题及解决方案
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。由于原有缓存失效,新缓存未到期间,所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。
解决方案:
- 加锁排队
- 数据预热
- 双层缓存策略
- 定时更新缓存策略
- 设置不同的过期时间,让缓存失效的时间点尽量均匀
12.? Redis的缓存击穿问题及解决方案
在高并发系统中,大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
解决方案:
- 可以在第一个查询数据的请求上使用一个互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
- 还可以限流:控制同一时间的请求访问量。
13.? Redis怎么做缓存预热?
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户直接查询事先被预热的缓存数据。
缓存预热的不同策略:
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
14. 如何保持MySql数据库和Redis缓存中数据的一致性?
1)直接删除redis缓存
2)基于消息队列(MQ)形式实现同步
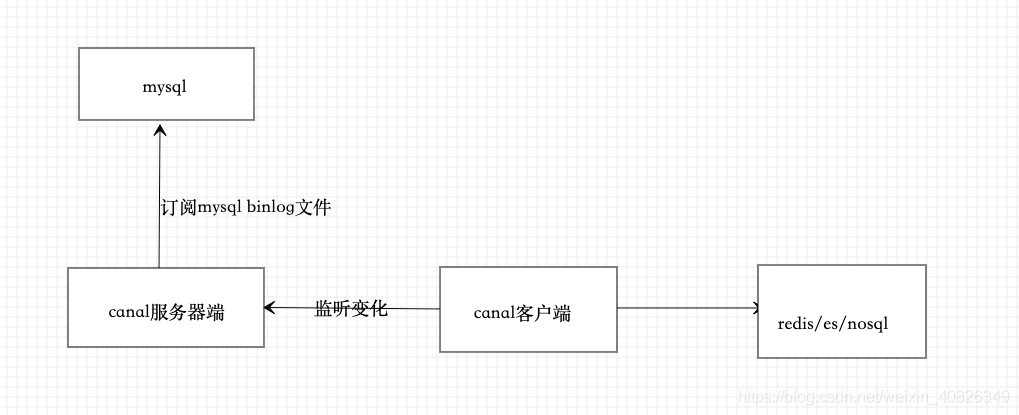
3)基于canal订阅MySql的binlog二进制文件,通过mq实现异步同步
未完待续...
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!