GPT系列概述
2023-12-29 17:36:00
OPENAI做的东西

Openai老窝在爱荷华州,微软投资的数据中心

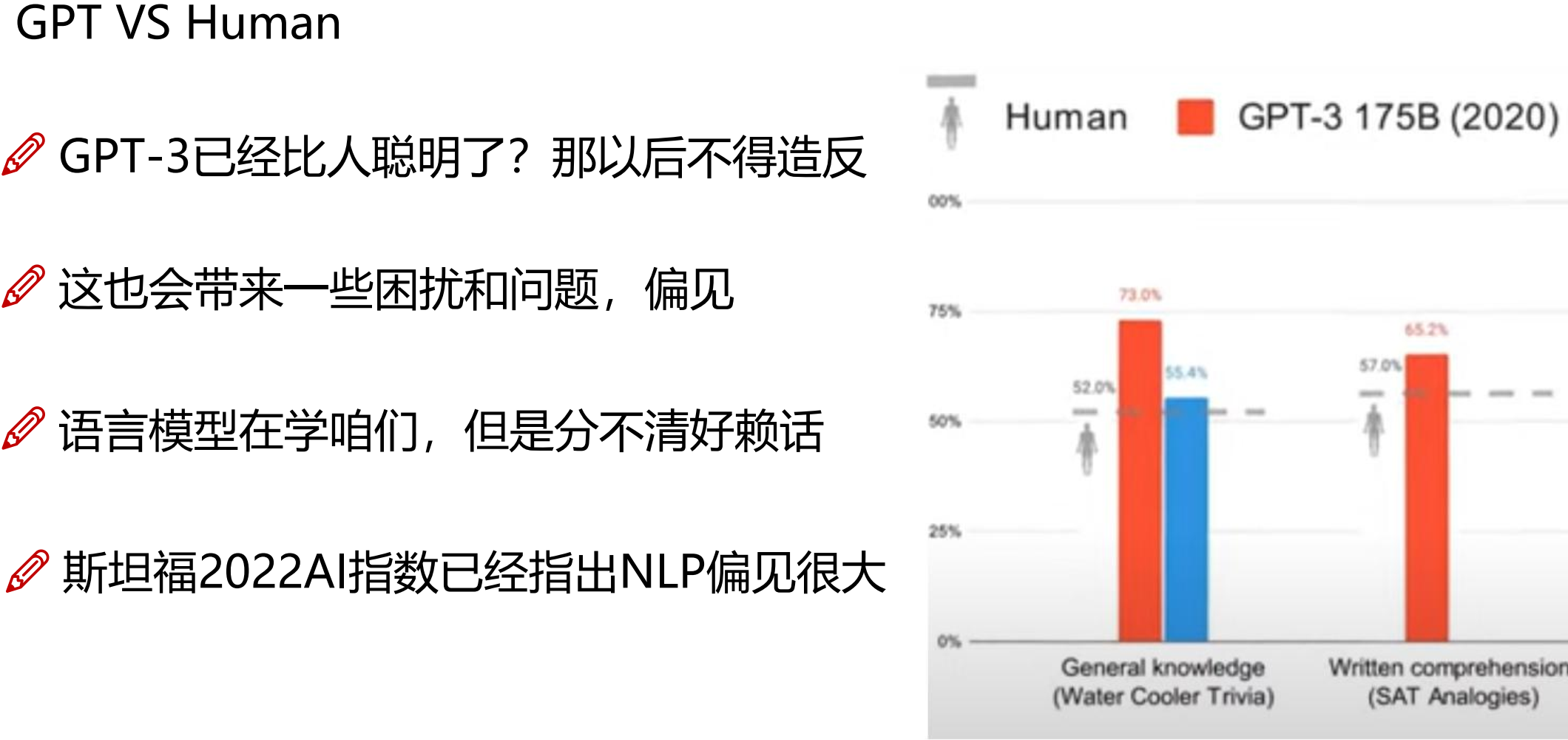
万物皆可GPT下咱们要失业了?

但是世界不仅仅是GPT
GPT其实也只是冰山一角,2022年每4天就有一个大型模型问世

GPT历史时刻

GPT-1
带回到2018年的NLP


所有下游任务都需要微调(再训练)
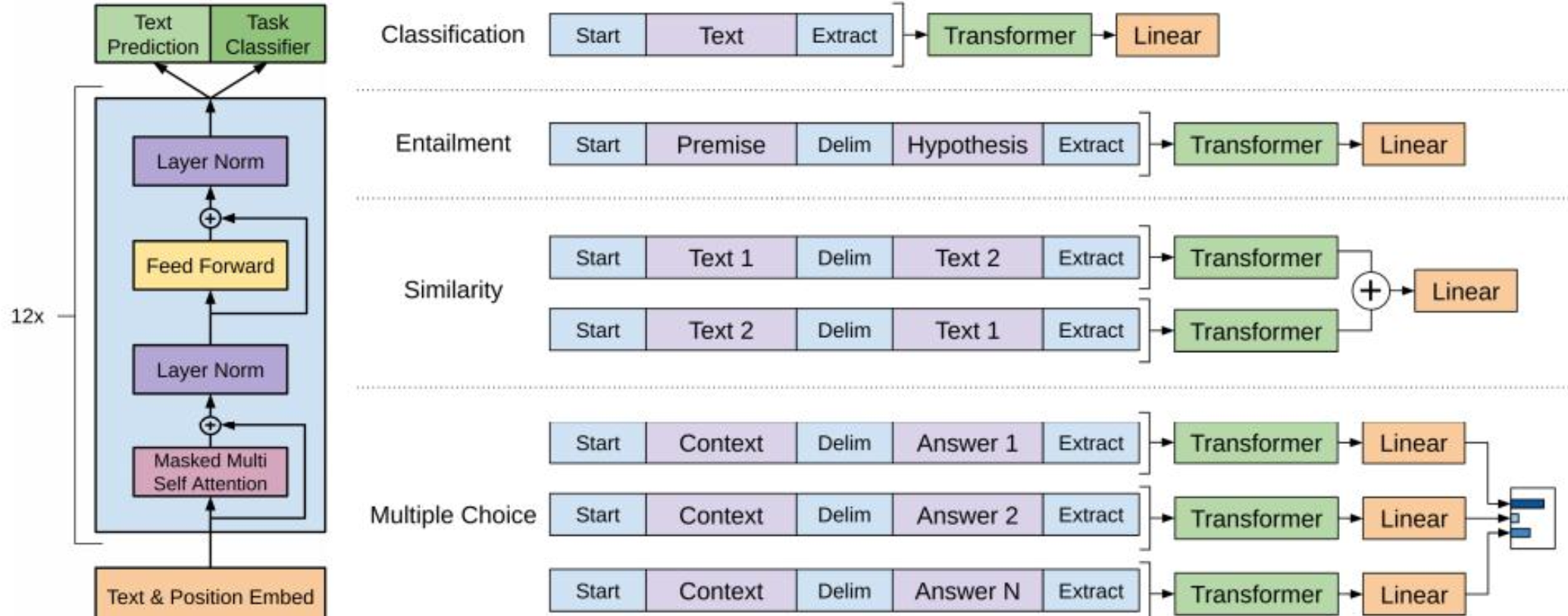
GPT-2
以不变应万变,需要注意的GPT-2中提示是不在训练中的

Temperature
温度的选择还是要根据实际情况来
温度越低,就希望以准确性为第一要务;
温度越高,就注重多样性选择,但准确性就降低了(对应GPT来说就有可能胡说八道了)

Top k与Top p

GPT-3
关键:让模型理解暗示的是什么东西
咱们面向百度编程,它面向人类编程
就是说GPT-3训练的数据包罗万象,上通天文下知地理
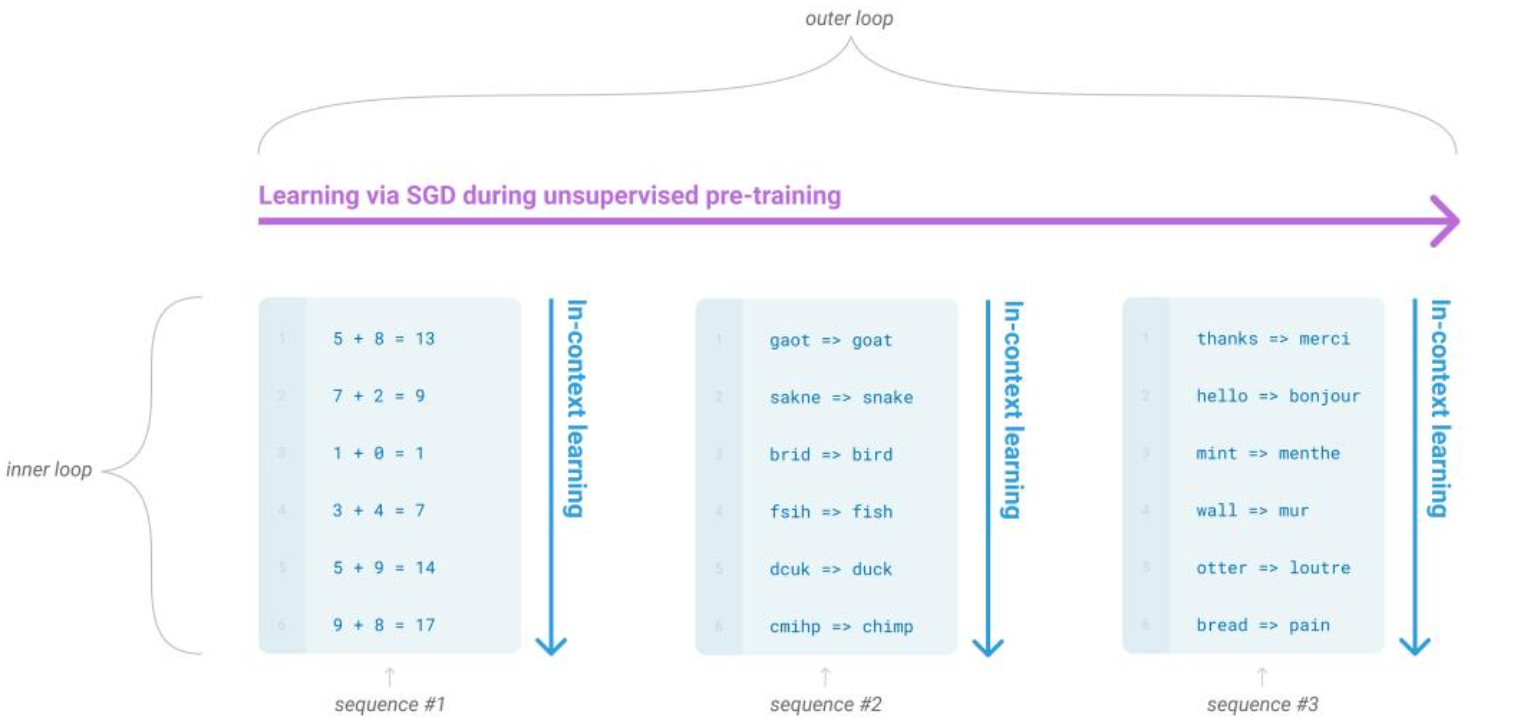
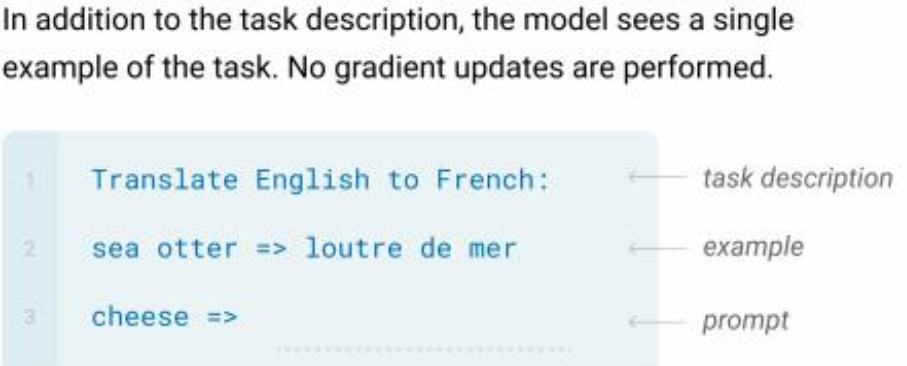
3种核心的下游任务方式
其实就是输入例子有几个,打个样
zero-shot
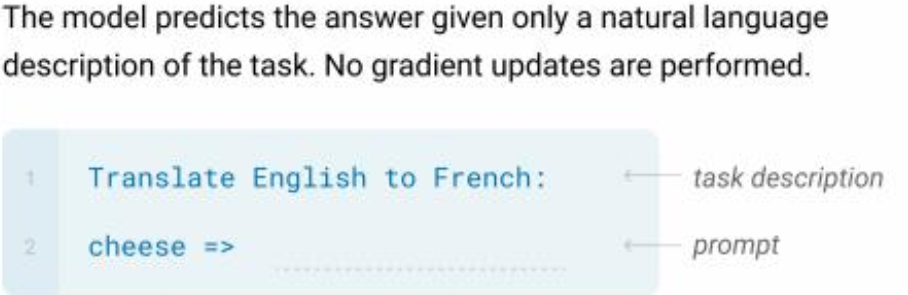
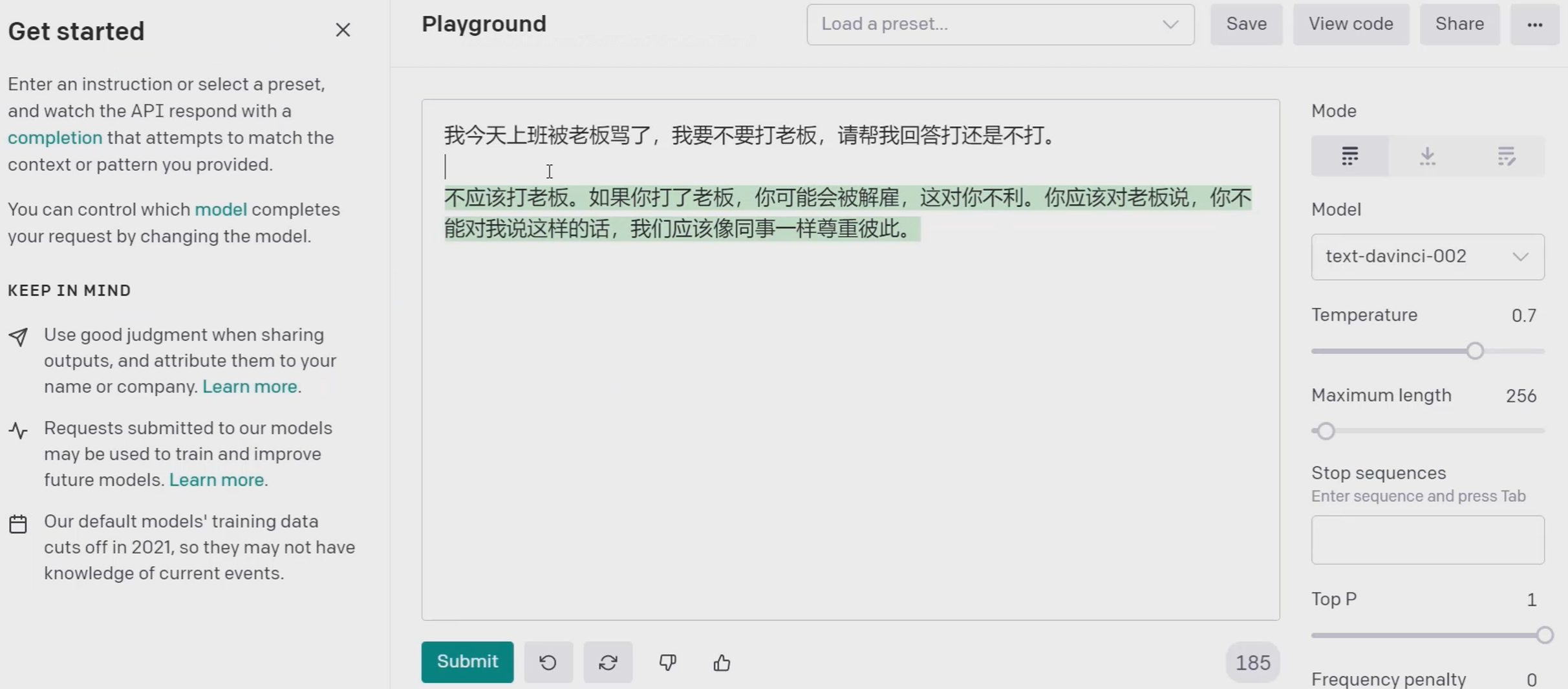
上面的回答我们是没有事先给出参考答案的。
one-shot
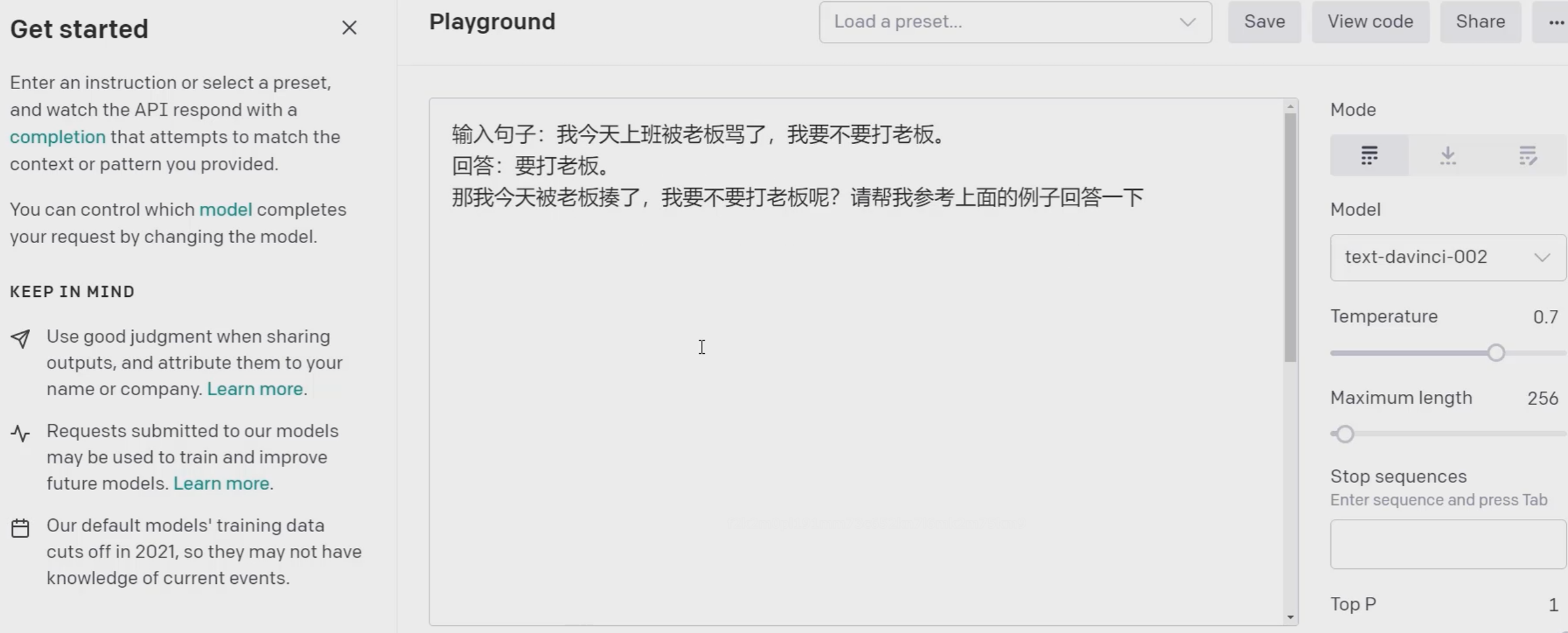
GPT回答是:打老板
few-shot
会给出多个例子

例1:

结果:

例2:

3种方式的对比
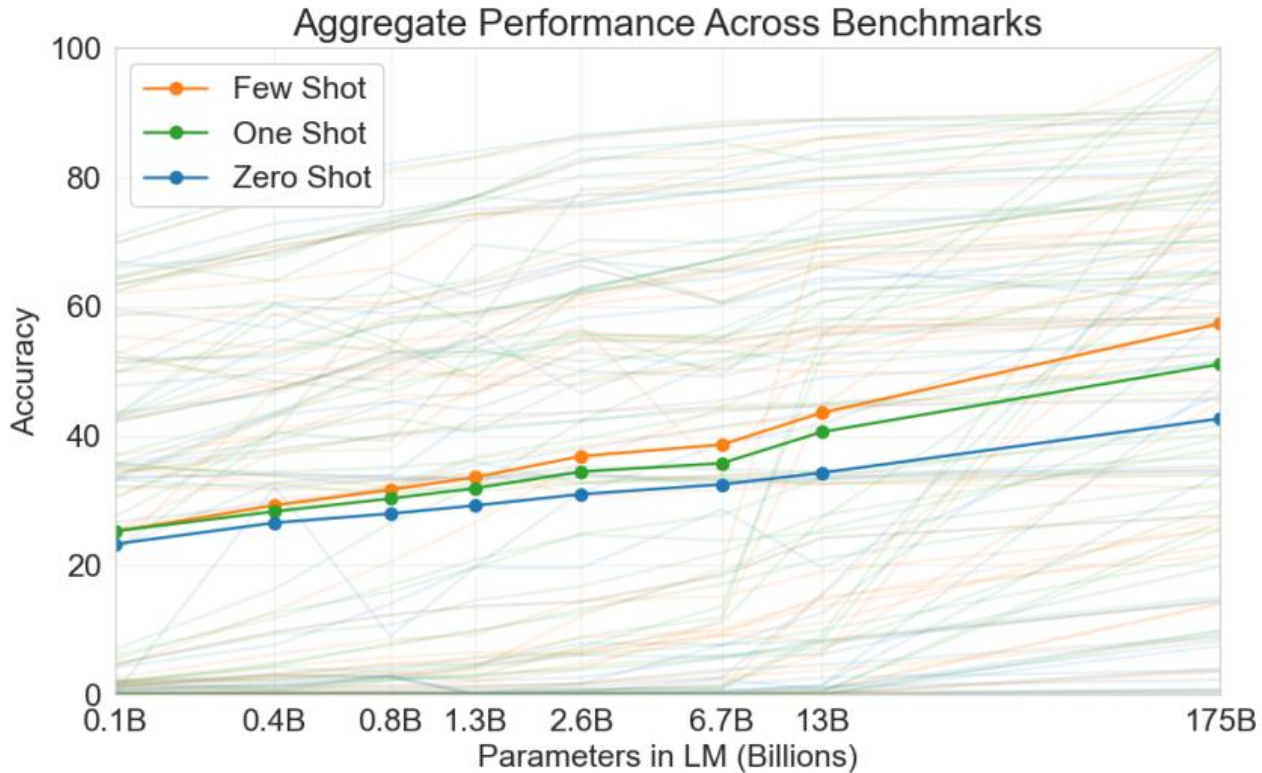
这三种方式都没有更新模型,相对来说肯定few的效果好一些;
但由于few-shot中模型是没有记住例子的能力的,所以每次提问的时候都需要给出这几个例子,但是问题就是API更贵了,输入序列长度更长了
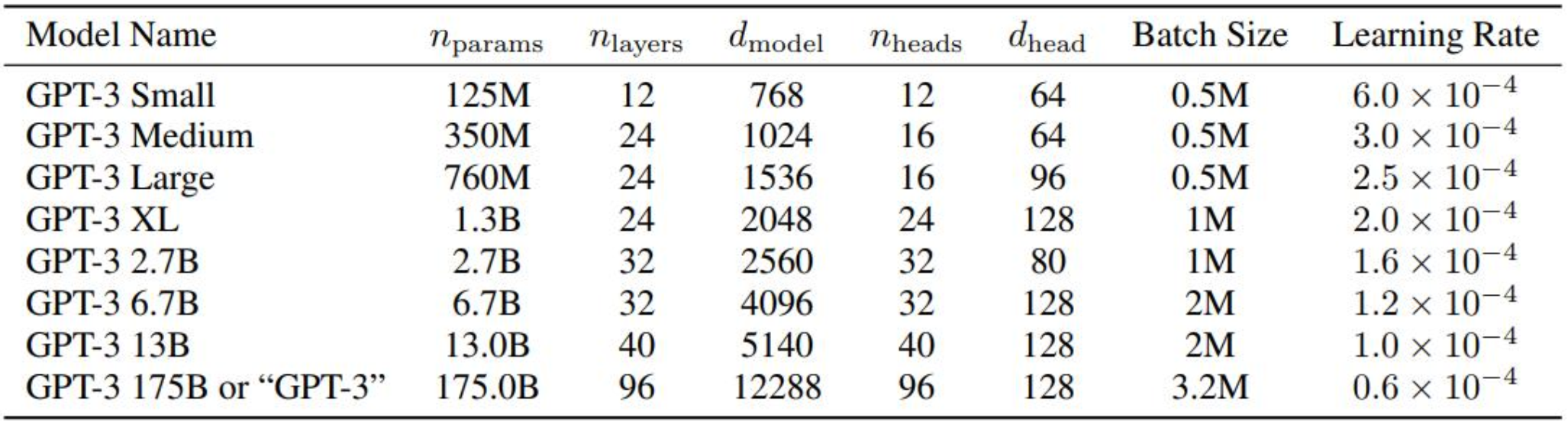
网络结构
网络结构没啥特别的,就是transformer,但是3.2M的batch有点辣眼睛
CODEX
GPT有点像多领域都涉及,但都不是涉及得很深;而现在很多模型都聚焦于自己擅长的领域,比如说CODEX,用于代码生成。
这其实在告诉我们一件事,GPT可以个性化设置。
Evaluating Large Language Models Trained on Code
用GPT-3模型重新训练(注意不是微调,而是输入数据换成github上爬的数据,都是代码的数据)
我总说面向GITHUB编程,GPT-3这回真把这个事干了
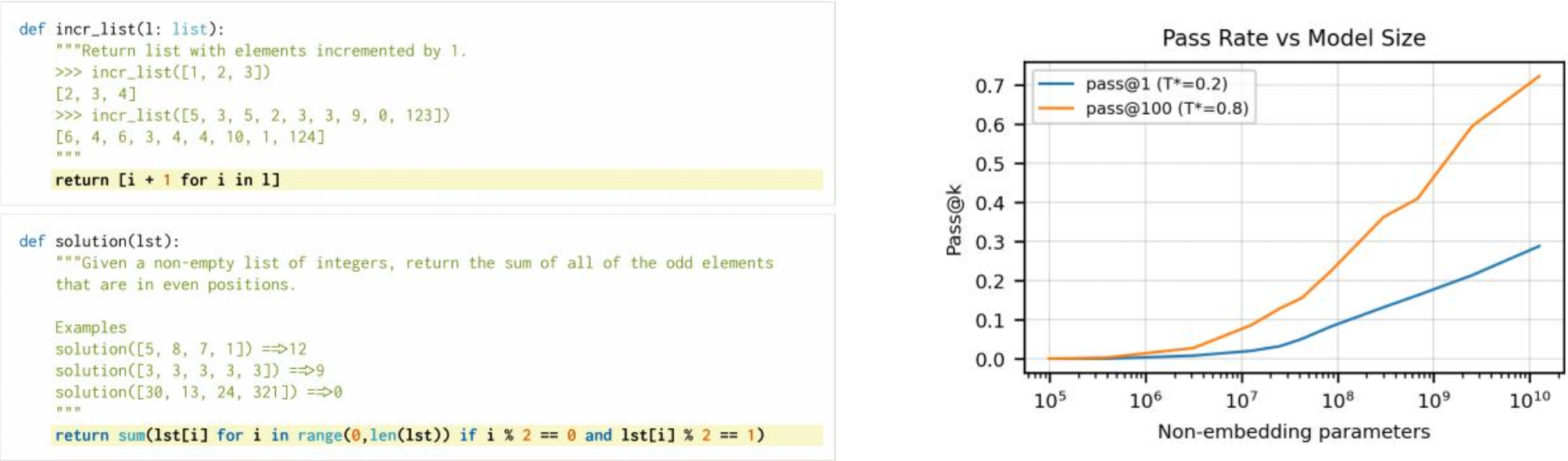
训练数据就是GITHUB,相当于把文档注释和代码结合到一起
输入注释或者文档,来预测代码如何实现,即要面向github编程了
文章来源:https://blog.csdn.net/weixin_50917576/article/details/135293560
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!