Azkaban+Spark资源调度
2024-01-03 04:11:51
本文以利用Azkaban+Spark构建数仓的DWS层和ADS层为例
!!!前提条件:各节点之间的免密、登录启动Hadoop集群、Spark、Azkaban、Hive
免密登录操作
ssh-keygen -t rsa
slave01执行:
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave01.pub
scp ~/.ssh/id_rsa.pub hadoop@slave02:~/.ssh/slave01.pub
master和slave02执行
cd ~/.ssh
sudo cat /home/hadoop/.ssh/slave01.pub >> /home/hadoop/.ssh/authorized_keys
slave02执行:
ssh-keygen -t rsa
scp ~/.ssh/id_rsa.pub hadoop@master:~/.ssh/slave02.pub
scp ~/.ssh/id_rsa.pub hadoop@slave01:~/.ssh/slave02.pub
master和slave01执行
cd ~/.ssh
sudo cat /home/hadoop/.ssh/slave02.pub >> /home/hadoop/.ssh/authorized_keys
首先在IDEA中分别编写创建DWS数据库、DWS库中外部表并导入数据、创建ADS数据库、ADS库中外部表并导入数据的代码
代码示例如下
创建DWS数据库
import org.apache.spark.sql.SparkSession
object Azkaban_Hive {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val spark = SparkSession.builder()
.appName("Azkaban_Hive")
.master("local[*]")
.config("spark.sql.warehouse.dir", "hdfs://master:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
//任务1: 创建数据库
spark.sql("create database if not exists dws_cscd")
// 关闭 SparkSession
spark.stop()
}
}
创建DWS层外部表并导入数据(以一个表为例,可根据需求自行创建其他表)
import org.apache.spark.sql.SparkSession
object Azkaban_Hive {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val spark = SparkSession.builder()
.appName("Azkaban_Hive")
.master("local[*]")
.config("spark.sql.warehouse.dir", "hdfs://master:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
spark.sql("use dws_cscd")
// 创建dws_cscd.dws_cscd_change_industry_i_y表
spark.sql(
"""
|create external table if not exists dws_cscd.dws_cscd_change_industry_i_y(
| abbreviation string,
| change double,
| ths_industry string
|)
|row format delimited
|fields terminated by ','
|stored as textfile
|location 'hdfs://master:9000/CSCD/store/dws/change_industry'
""".stripMargin)
// 任务3: 插入数据,依赖于任务2
spark.sql(
"""
|insert overwrite table dws_cscd.dws_cscd_change_industry_i_y
|select
|abbreviation,change,ths_industry
|from dwd_cscd.dwd_cscd_a_share_i_y
|order by change desc
""".stripMargin)
// 关闭 SparkSession
spark.stop()
}
}
ADS层和ADS层外部表的创建方式与DWS层相同
将这四个文件分别在IDEA上达成jar包并上传到虚拟机自己指定的目录下
打包

复制jar包并上传到虚拟机

接着编写azkaban.project和basic.flow文件打成Azkaban_spark.zip压缩包
文件内容如下
azkaban.project(内容固定不变)
azkaban-flow-version: 2.0basic.flow
nodes:
- name: create_database_dws
type: command
config:
command: spark-submit --class Azkaban_Hive --master spark://master:7077 /home/hadoop/CSCD/dws/create_database_dws.jar
- name: create_table_dws
type: command
dependsOn:
- create_database_dws
config:
command: spark-submit --class Azkaban_Hive --master spark://master:7077 /home/hadoop/CSCD/dws/create_table_dws.jar
- name: create_database_ads
type: command
dependsOn:
- create_table_dws
config:
command: spark-submit --class Azkaban_Hive --master spark://master:7077 /home/hadoop/CSCD/ads/create_database_ads.jar
- name: create_table_ads
type: command
dependsOn:
- create_database_ads
config:
command: spark-submit --class Azkaban_Hive --master spark://master:7077 /home/hadoop/CSCD/ads/create_table_ads.jar
登录Azkaban,创建dws_and_ads项目并上传Azkaban_spark.zip压缩包
运行项目
项目依赖关系
先创建dws_cscd数据库,然后创建dws_cscd数据库的外部表,接着创建ads_cscd数据库,最后创建ads_cscd数据库的外部表

项目运行结果
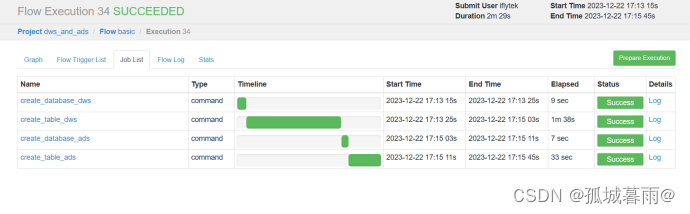
如果不成功,查看日志,可以适当调整虚拟机各节点的内存大小
还有其他问题,欢迎在评论区下面留言讨论。
文章来源:https://blog.csdn.net/jiang1182427208/article/details/135336195
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!