【JUC】二十三、LongAdder:多线程计数的更优解
文章目录
Since 1.8,新加原子操作增强类:
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
API文档:runoob.com/manual/jdk11api/java.base/java/util/concurrent/atomic/LongAdder.html
1、常用API
常用方法:
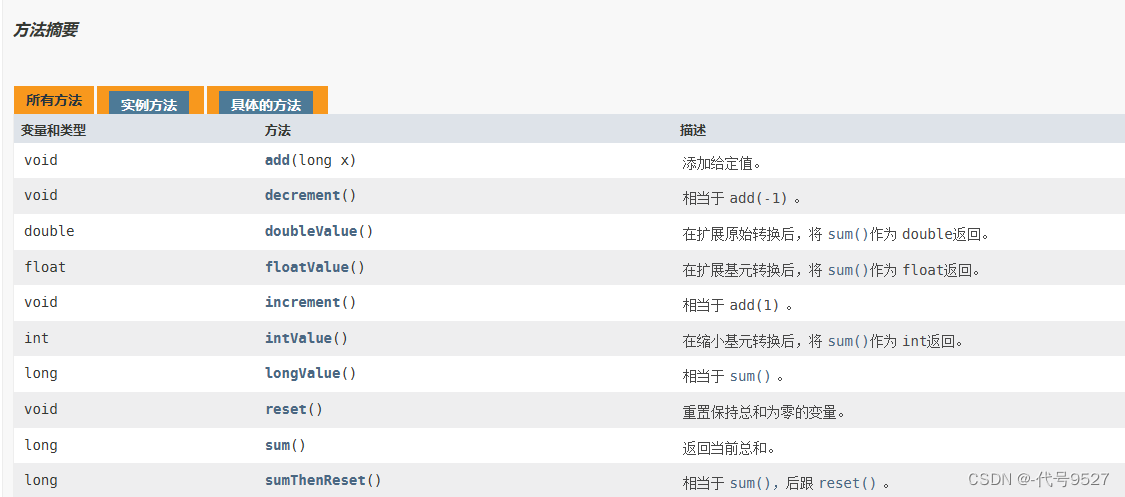
LongAdder只能用来计算加法,且从零开始计算,LongAccumulator则更灵活,可传入一个函数式接口和初始值,函数式接口中自定义计算逻辑,加减乘除。
LongAdder longAdder = new LongAdder();
longAdder.increment(); //+1
longAdder.increment();
longAdder.increment();
System.out.println(longAdder.sum()); //3
//new LongAccumulator((x, y) -> x * y, 1)
LongAccumulator longAccumulator = new LongAccumulator(new LongBinaryOperator() {
@Override
//left:初始值,right:传进来的值
public long applyAsLong(long left, long right) {
return left * right;
}
}, 1);
longAccumulator.accumulate(2); //2
longAccumulator.accumulate(3); //6
System.out.println(longAccumulator.get()); //6
2、热点商品点赞计算器
热点商品点赞计算器,点赞数加加统计,不要求实时精确。比如:50个线程,每个线程100W次,总点赞数出来。分析下,点赞一次就+1,本质是多线程下的并发的i++:
class ClickNumber{
int number = 0;
//方式一
public synchronized void clickBySynchronized(){
number++;
}
//方式二
AtomicLong atomicLong = new AtomicLong(0);
public void clickByAtomicLong(){
atomicLong.getAndIncrement();
}
//方式三
LongAdder longAdder = new LongAdder();
public void clickByLongAdder(){
longAdder.increment();
}
//方式四
LongAccumulator longAccumulator = new LongAccumulator((x,y) -> x+y,0);
public void clickByLongAccumulator(){
longAccumulator.accumulate(1);
}
}
调用4种方式,借助辅助类计数器,计算5000000点赞耗时:
public class AccumulatorDemo {
public static final int _1W = 10000;
public static final int threadNum = 50;
public static void main(String[] args) throws InterruptedException {
ClickNumber clickNumber = new ClickNumber(); //共享资源类对象
long startTime;
long endTime;
CountDownLatch countDownLatch1 = new CountDownLatch(threadNum); //计数器
CountDownLatch countDownLatch2 = new CountDownLatch(threadNum);
CountDownLatch countDownLatch3 = new CountDownLatch(threadNum);
CountDownLatch countDownLatch4 = new CountDownLatch(threadNum);
//====方法一的耗时===
startTime = System.currentTimeMillis();
for (int i = 1; i <= threadNum ; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 100 * _1W; j++) {
clickNumber.clickBySynchronized();
}
} finally {
//50个线程,做完一个少一个
countDownLatch1.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch1.await();
endTime = System.currentTimeMillis();
System.out.println("synchronized耗时:" + (endTime - startTime) + ",当前点赞数:" + clickNumber.number);
//====方法2的耗时===
startTime = System.currentTimeMillis();
for (int i = 1; i <= threadNum ; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 100 * _1W; j++) {
clickNumber.clickByAtomicLong();
}
} finally {
//50个线程,做完一个少一个
countDownLatch2.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch2.await();
endTime = System.currentTimeMillis();
System.out.println("AtomicLong耗时:" + (endTime - startTime) + ",当前点赞数:" + clickNumber.atomicLong.get());
//====方法3的耗时===
startTime = System.currentTimeMillis();
for (int i = 1; i <= threadNum ; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 100 * _1W; j++) {
clickNumber.clickByLongAdder();
}
} finally {
//50个线程,做完一个少一个
countDownLatch3.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch3.await();
endTime = System.currentTimeMillis();
System.out.println("LongAdder耗时:" + (endTime - startTime) + ",当前点赞数:" + clickNumber.longAdder.sum());
//====方法4的耗时===
startTime = System.currentTimeMillis();
for (int i = 1; i <= threadNum ; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 100 * _1W; j++) {
clickNumber.clickByLongAccumulator();
}
} finally {
//50个线程,做完一个少一个
countDownLatch4.countDown();
}
},String.valueOf(i)).start();
}
countDownLatch4.await();
endTime = System.currentTimeMillis();
System.out.println("LongAccumulator耗时:" + (endTime - startTime) + ",当前点赞数:" + clickNumber.longAccumulator.get());
}
}
运算结果:
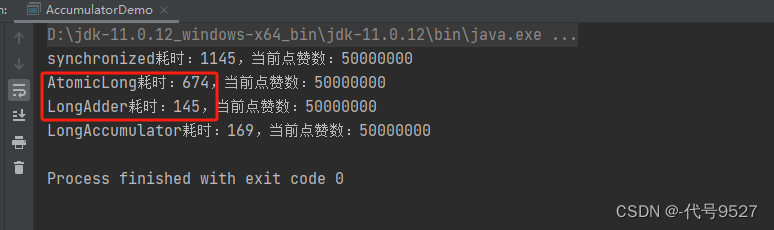
结论:很大的高并发下,LongAdder的性能优于AtomicLong(减少了乐观锁的重试次数)

3、LongAdder高性能的原理
LongAdder --> Striped64类 --> Number类,Cell类,单元格类,是Striped64类的一个内部类。
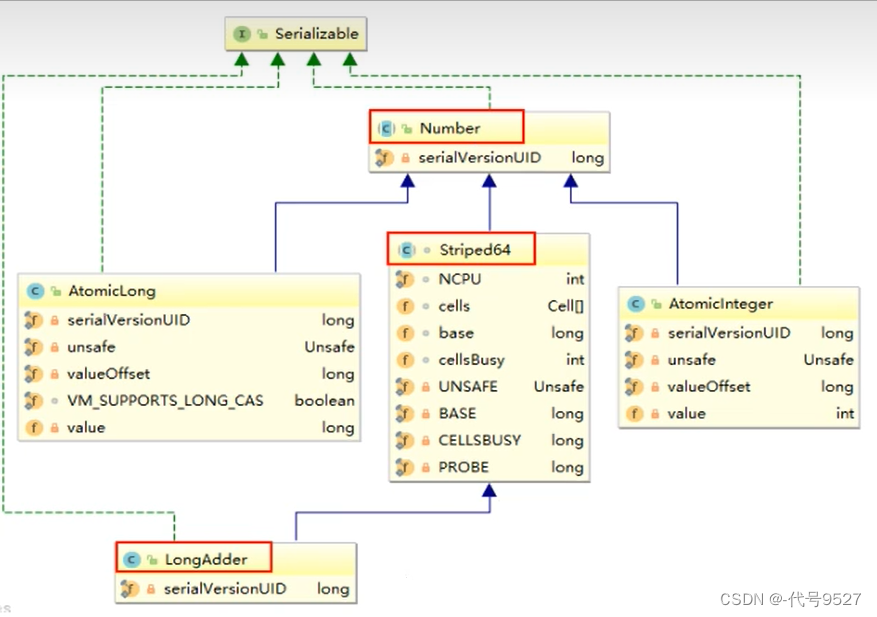
Striped64类的属性解释:

前面的AtomicLong,N个线程同时CAS修改一个值,每次只会有一个成功,而其余N-1个线程一定失败而继续不停的自旋,N很大时,就会有大量的失败自旋。
而LongAdder的基本思路就是分散热点,不要逮着一个值自旋,而是将value值分散到一个Cell数组中,不同线程会命中到Cell数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
sum()时会将所有Cel数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,每次并发CAS的失败线程数量就少了。
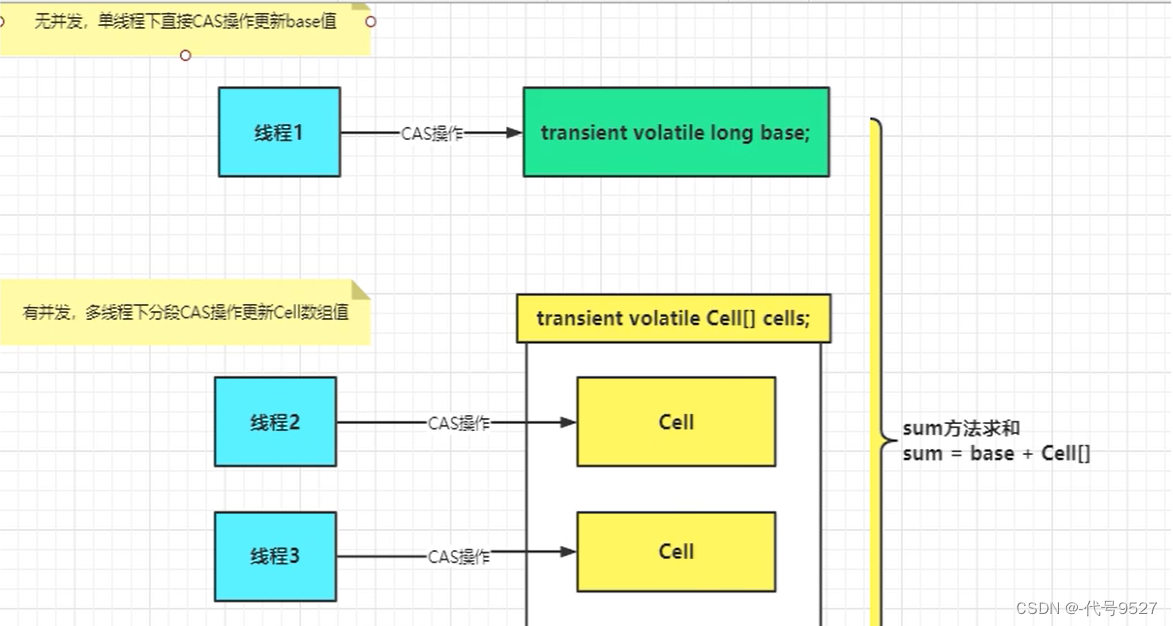
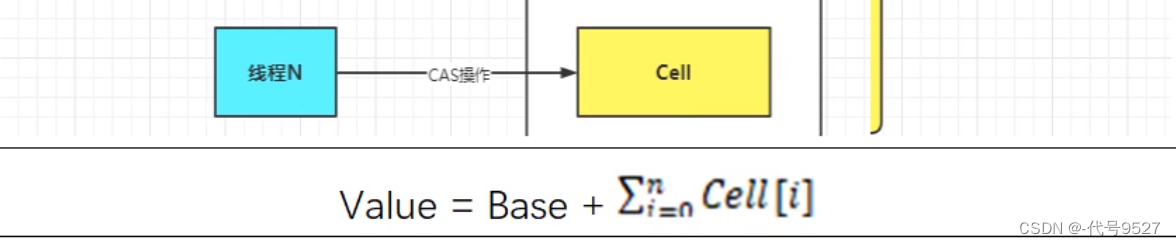
LongAdder在无竞争的情况下,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零分散热点的做法,用空间换时间,新加一个数组cells,将一个value的累加拆分进这个数组cells来分担。
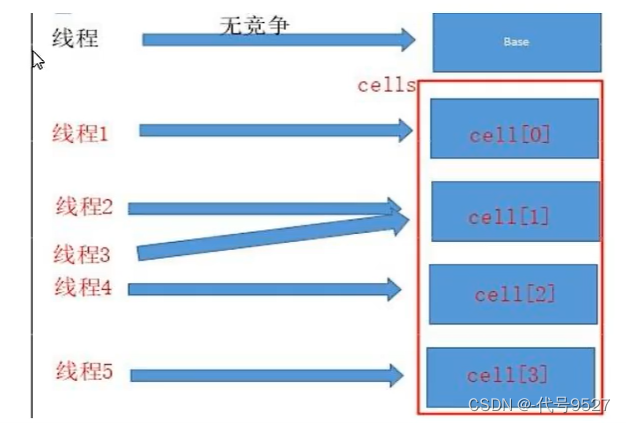
多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到cells数组的某下标,然后对该下标所对应的值进行自增换作。当所有线程操作完毕,将数组cells的所有值和base都加起来作为最终结果。
4、源码:LongAdder-add方法
new LongAdder().increment()
各方法底层的调用关系为:
increment() --> add(1L) --> longAccumulate()
//最后累加的结果
--> sum()
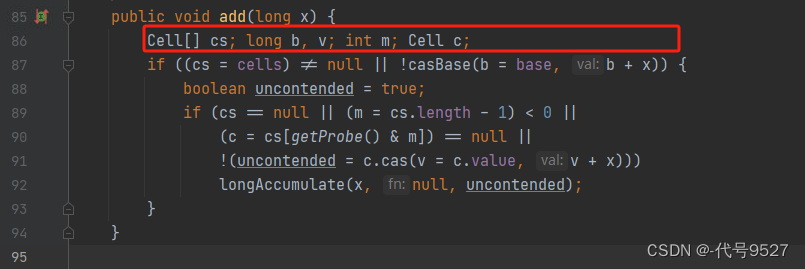
从add方法开始看,方法局部变量有:
- as:Striped64类的cells数组
- b:Striped64类的的base值
- v:期望值
- m:cells数组的长度
- a:当前线程命中的cell数组中的cell单元格对象
首次,只有一个线程的时候,base就可以完成,cell == null,casBase方法+1的操作操作成功,if条件不成立,直接跳出循环,但已经在||条件判断的时候顺带着完成了+1的操作。
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x)) {
// true无竞争,false表示竟争激烈,多个线hash到同一个CeLL,可能要扩容
boolean uncontended = true;
//||下的四个条件分别为:
//条件1:cell单元格数组为空
//条件2:cell长度小于1,一般不会,因为到这儿说明cell不为null,而其长度2次幂起步
//条件3:getProbe获取当前线程的哈希值,映射到cell后,cell为空,说明当前线程还没更新过cell,应初始化一个cell
//条件4:更新当前线程所映射的cell失败,即多个线程hash到了同一个cell,说明竞争激烈,取反后到longAccumulate继续扩容
if (cs == null || (m = cs.length - 1) < 0 ||
//getProbe方法返回的时线程中的threadLocalRandomProbe字段
//它是通过随机数生成的一个值,对于一个确定的线程,这个值固定,除非刻意修改
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended); //Striped64中的方法扩容
}
}
随着线程增多,CAS判断失败,false,取反后条件成立,进入if体中,uncountened=true,默认没有冲突,此时还没扩容,Cell[] as == null是成立的,进入longAccumulate(),按2次幂阔,出来两个Cell。(longAccumulate方法下面再详细展开)
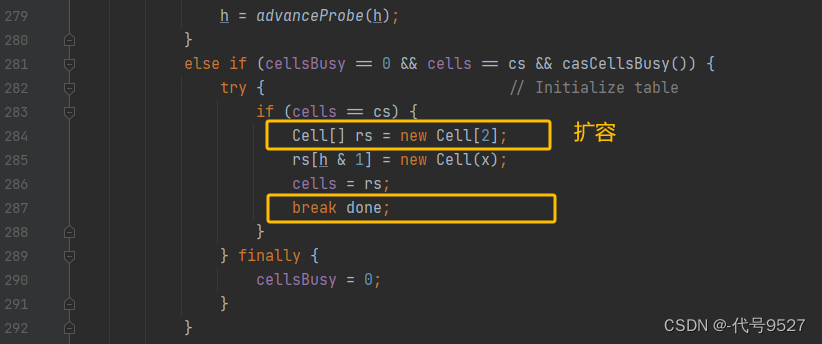
此时,base可以+1,cell0、cell1也可以做+1,再调add,此时Cell[] as不再等于null,且length-1=1>0(2次幂) ,继续看||后面的条件,a = as[getProbe() & m],算坑位,比如算到了cell1这个单元格,此时,假设cell1中有值,为1,做个CAS,x为1,则1改为2,返回true,取反为false,跳出方法,但+1也随着条件判断完成了。
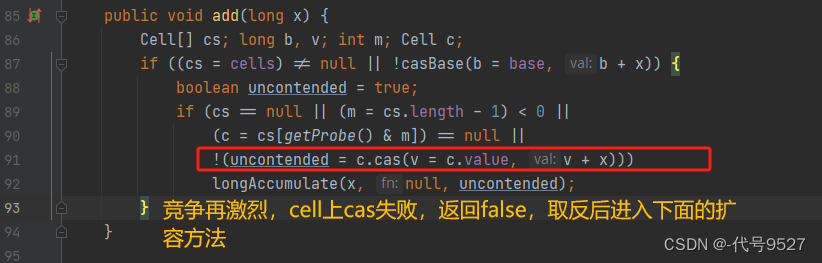
如上图,再并发,竞争激烈,cell0、cell1扛不住了也,cell上cas失败,uncontended为false,取反,true,再进入longAccumulate()扩容,2个变4个。
总结:
- 最初无竞争时只更新base;
- 如果更新base失败后,首次新建一个Cell[ ]数组
- 当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[ ]扩容
代码亮点:调用方法做为判断条件,最终的效果就是活儿干了(数据改变了),条件也做了判断了。借鉴!
简略版图解:

5、源码:LongAdder-longAccumulate方法
Striped64类中的一些属性和方法:getProbe方法,获取线程的hash值,这个值用于判断去cell数组的哪个槽位中去。

//getProbe方法返回的时线程中的threadLocalRandomProbe字段
static final int getProbe(){
return UNSAFE.getInt(Thread.currentThread(),PROBE);
}
longAccumulate()方法的入参:
- long x :需要做雷加的值,increment调用下,一般默认都是+1
- LongBinaryOperator fn :默认传递的是null
- wasUncontended:竞争标识,如果是false则代表有竞争,只有cells初始化之后,并且当前线程CAS竞争修改失败,才会是false
longAccumulate方法开头处理下线程的probe值:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//存储线程的probe值
int h;
//getProbe返回为0,即线程随机数未初始化
if ((h = getProbe()) == 0) {
//使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化
ThreadLocalRandom.current(); // force initialization
//重新获取probe值,hash被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为true,表示无竞争
h = getProbe();
//重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,背定还不存在竟争激烈,wasUncontended竞争状态为true
wasUncontended = true;
}
//......
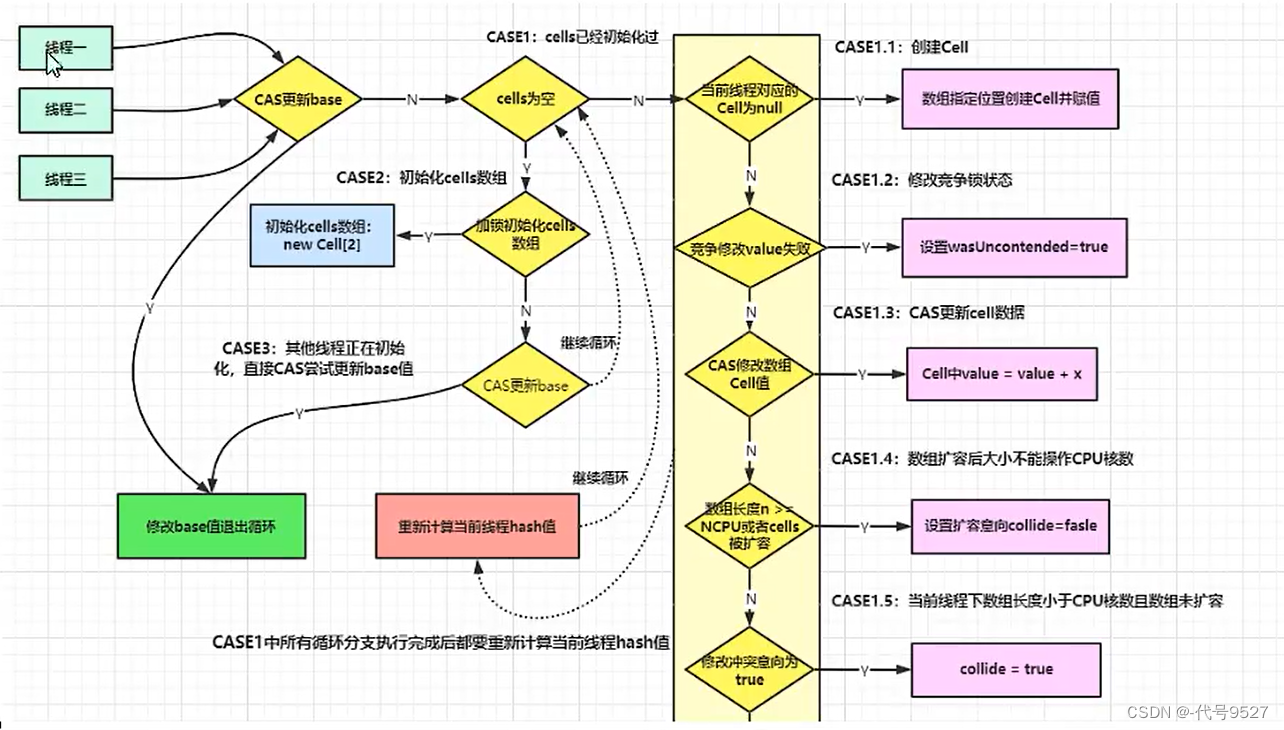
然后longAccumulate方法源码大体结构为:首先给当前线程分配一个hash值,然后进入一个for(;;)自旋,这个自旋分为三个分支:
-
CASE1: Cell[ ] 数组已经初始化
-
CASE2:CelI[ ] 数组未初始化(首次新建)
-
CASE3:Cell[ ] 数组正在初始化中
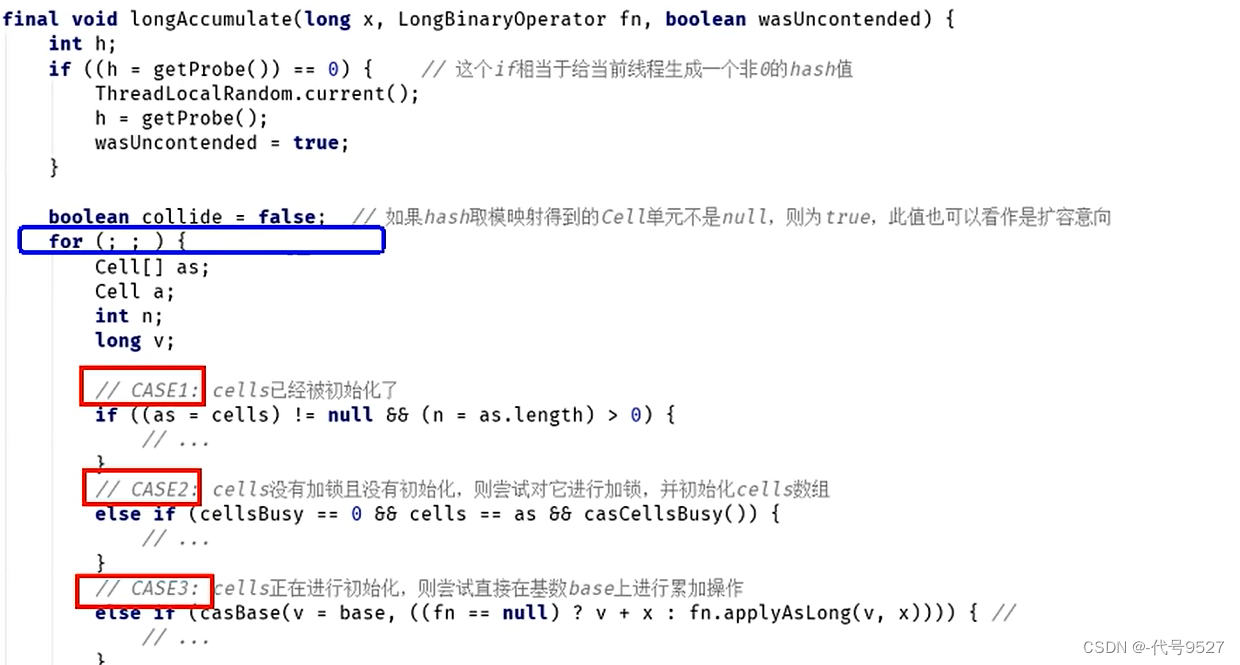
先看Case2:未初始化过Cell[ ] 数组,尝试占有锁并首次初始化cells数组
cellsBusy:初始化cells或者扩容cells需要获取锁,0表示无锁状态,1表示其他线程已经持有了锁。为0时,抢到锁,&&后面casCellsBusy改为1,初始化创建Cell[2]后,finally中cellsBusy改回0,注意下面有点双重检锁的味道。
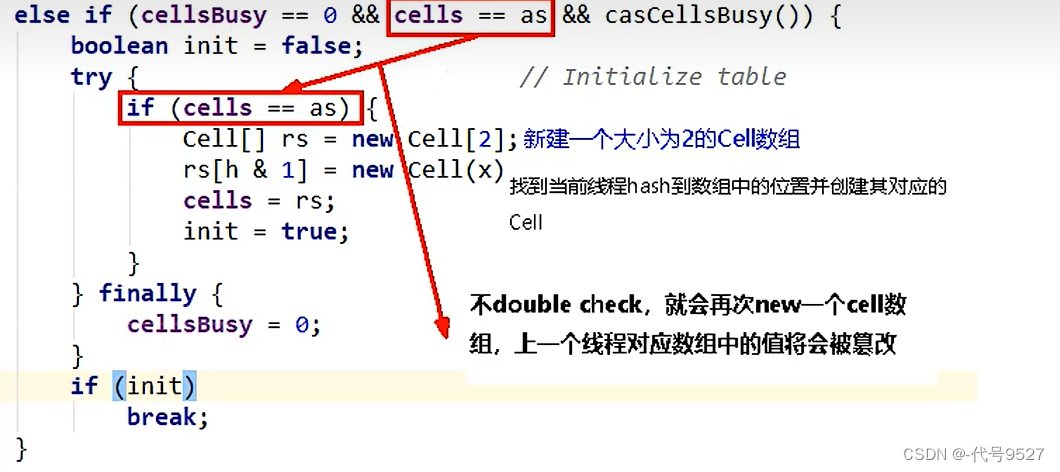
如果上面条件都执行成功就会执行数组的初始化及赋值操作, Cell[] rs = new Cell[2]表示数组的长度为2,rs[h & 1]= new Cell(x) 即创建一个新的Cell元素,value是累加的值x,默认为1。h & 1类似于之前HashMap常用到的计算散列桶index的算法,通常都是hash & (table.len - 1),同hashmap一个意恩。
再看Case3:上面竞争很激烈,else兜底的,多个线程尝试CAS修改失败的线程会走到这个分支
该分支直接操作base,将值累加到base

最后看Case1:Cell数组不再为空且可能存在Cell数组扩容,多个线程同时命中一个cell的竞争。此个If分支又分为6中if情况:
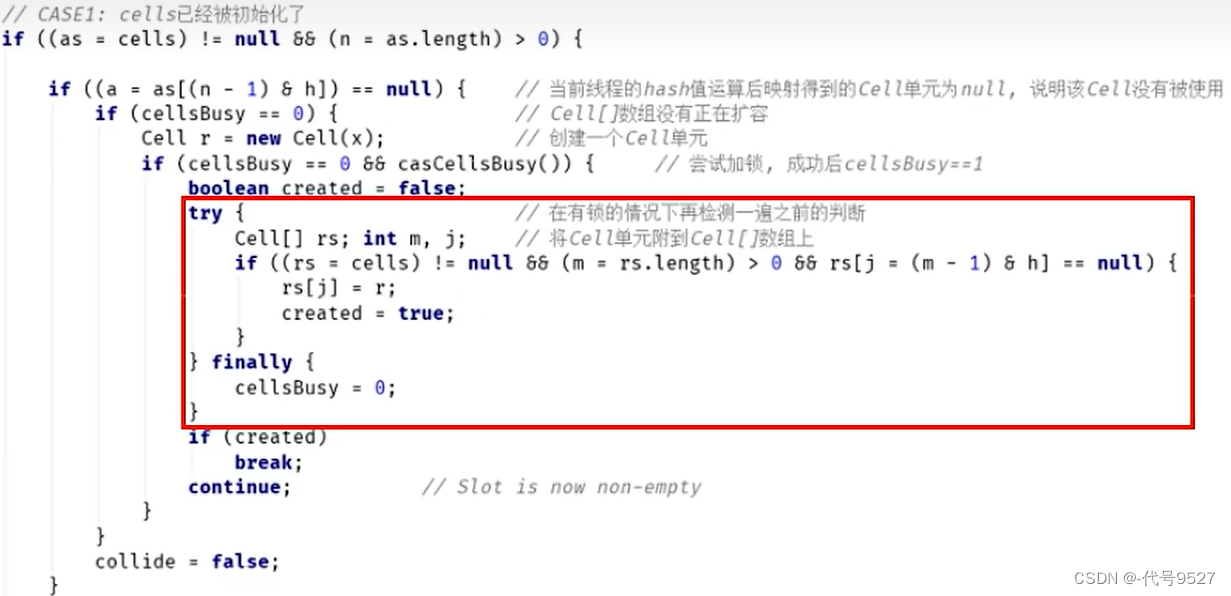
上面代码判断当前线程hash后指向的数据位置元素是否为空,如果为空则将Cell数据放入数组中,跳出循环。如果不空则继续循环。

wasUncontended表示cells初始化后,当前线程竞争修改失败wasUncontended =false,这里只是重新设置了这个值为true,紧接着执行Striped64类的advanceProbe(h)方法重置当前线程的hash,重新循环,重新再竞争一次。
 说明当前线程对应的数组中有了数据,也重置过hash值,这时通过CAS操作尝试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接break跳出循环。
说明当前线程对应的数组中有了数据,也重置过hash值,这时通过CAS操作尝试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接break跳出循环。
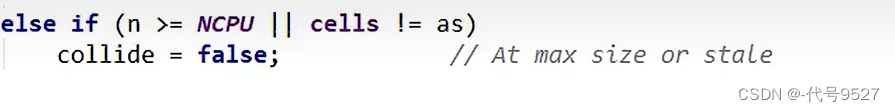
如果n大于CPU最大数量,不可扩容并通过下面的h=advanceProbe(h)方法修改线程的probe再重新尝试。

如果扩容意向collide是false则修改它为true,然后重新算当前线程的hash值继续循环,如果当前数组的长度已经大于了CPU的核数,就会再次设置扩容意向collide=false (见上一步)

总结:

6、源码:LongAdder-sum方法
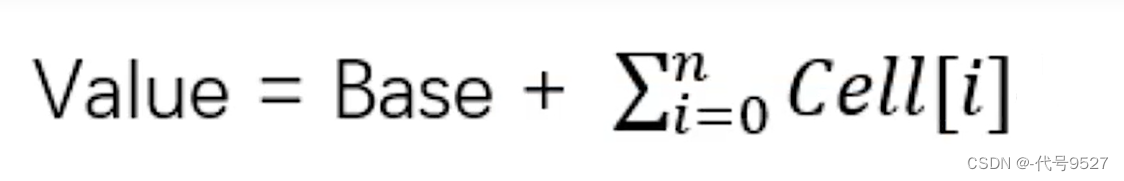
sum()会将斯有Cell数组中的value和base累加作为返回值。核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。
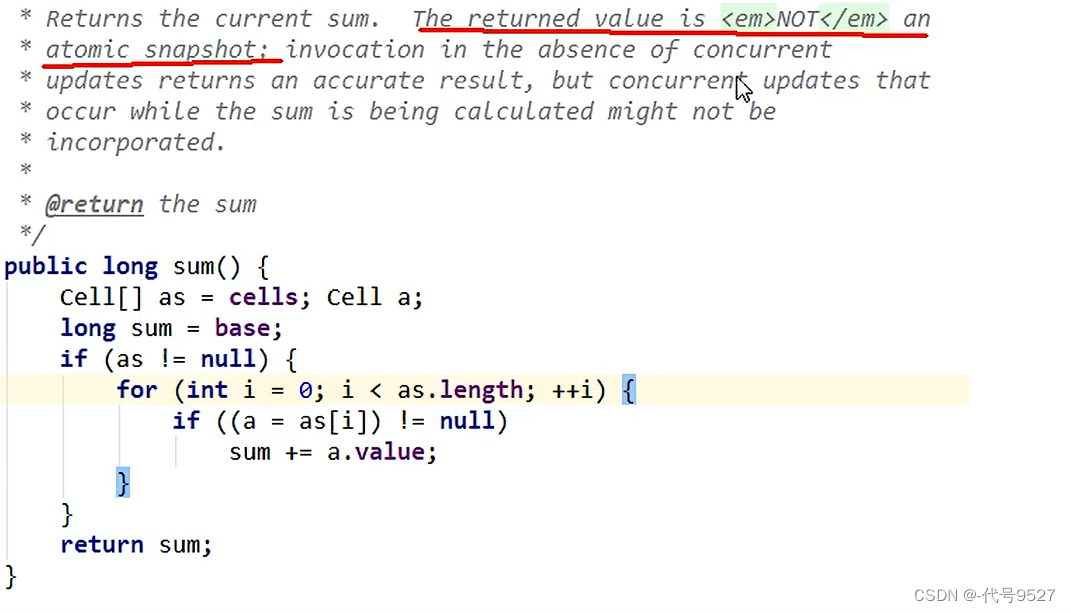
为啥并发情况下sum的值不精确?
sum执行时,并没有限制对base和cells的更新(一句要命的话),所以LongAdder不是强一致性的,它是最终一致性的。
首先,最终返回的sum局部变量,初始被复制为base,而最终返回时,很可能base已经被更新了,而此时局部变量sum不会更新,造成不一致。其次,这里对cell的读取也无法保证是最后一次写入的值。所以,sum方法在没有并发的情况下,可以获得正确的结果。
7、AtomicLong和LongAdder的对比
AtomicLong:
- 通过CAS+自旋实现
- 线程安全,可允许一些性能损耗,要求高精度时选AtomicLong
- 保证精度,但以性能为代价
- AtomicLong是多个线程针对单个热点值value进行原子操作
- 缺点是高并发下,性能急剧下降,且AtomicLong的自旋同时也是瓶颈:因为N个线程同时CAS一个值,只有一个线程成功,其余N-1个线程要不断自旋
LongAdder:
- 通过CAS+Base +Cell数组分散热点来实现
- 当需要在高并发下有较好的性能表现,且对值的精确度要求不高时,可以使用
- 保证性能,但以精度为代价
- LongAdder是每个线程拥有自己的槽,各个线程一般只对自己槽中的那个值进行CAS操作
- 缺陷是:sum求和后,还有计算线程修改结果的话,最后返回的结果不够准确
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!