【大模型实践】ChatGLM3微调输入-输出模型(六)
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
更全面的开源序列: 除了对话模型 ChatGLM3-6B外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32k。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
本文介绍了ChatGLM3-6B在AdvertiseGen数据集上的微调结果。请确保我完成了【大模型实践】ChatGLM3安装及体验(四)中的环境安装及模型下载部分。
一、准备数据集
对于输入-输出格式,样例采用如下输入格式:
[
{
"prompt": "<prompt text>",
"response": "<response text>"
}
// ...
]预处理时,不会拼接任何角色标识符。
作为示例,使用 AdvertiseGen 数据集来进行微调。Advertise是一个根据提示词生成广告的数据集,其部分内容如下:
{"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞",
"summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。"}
该数据集内有train.json和dev.json共2个文件:
进入finetune_chatmodel_demo目录:
cd finetune_chatmodel_demo下面使用chatglm3-6b的数据处理工具将该数据集的格式转换成chatglm3的格式(json文件的路径更换为自己的训练数据路径):
python scripts/format_advertise_gen.py --path "data/advertisegen/train.json"处理完成后,该目录下会多出一个formatted_data目录,下面有处理好的数据:
二、P-Tuning v2微调
本教程使用P-Tuning v2微调。将ChatGLM3/finetune_chatmodel_demo/scripts/finetune_pt.sh的BASE_MODEL_PATH替换为自己的chatglm-6b的路径):
#! /usr/bin/env bash
set -ex
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
MAX_SOURCE_LEN=1024
MAX_TARGET_LEN=128
DEV_BATCH_SIZE=1
GRAD_ACCUMULARION_STEPS=32
MAX_STEP=1000
SAVE_INTERVAL=500
DATESTR=`date +%Y%m%d-%H%M%S`
RUN_NAME=advertise_gen_pt
BASE_MODEL_PATH=chatglm3-6b
DATASET_PATH=formatted_data/advertise_gen.jsonl
OUTPUT_DIR=output/${RUN_NAME}-${DATESTR}-${PRE_SEQ_LEN}-${LR}
mkdir -p $OUTPUT_DIR
torchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS finetune.py \
--train_format input-output \
--train_file $DATASET_PATH \
--preprocessing_num_workers 1 \
--model_name_or_path $BASE_MODEL_PATH \
--output_dir $OUTPUT_DIR \
--max_source_length $MAX_SOURCE_LEN \
--max_target_length $MAX_TARGET_LEN \
--per_device_train_batch_size $DEV_BATCH_SIZE \
--gradient_accumulation_steps $GRAD_ACCUMULARION_STEPS \
--max_steps $MAX_STEP \
--logging_steps 1 \
--save_steps $SAVE_INTERVAL \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN 2>&1 | tee ${OUTPUT_DIR}/train.log
开始训练:
bash scripts/finetune_pt.sh训练中。。。。
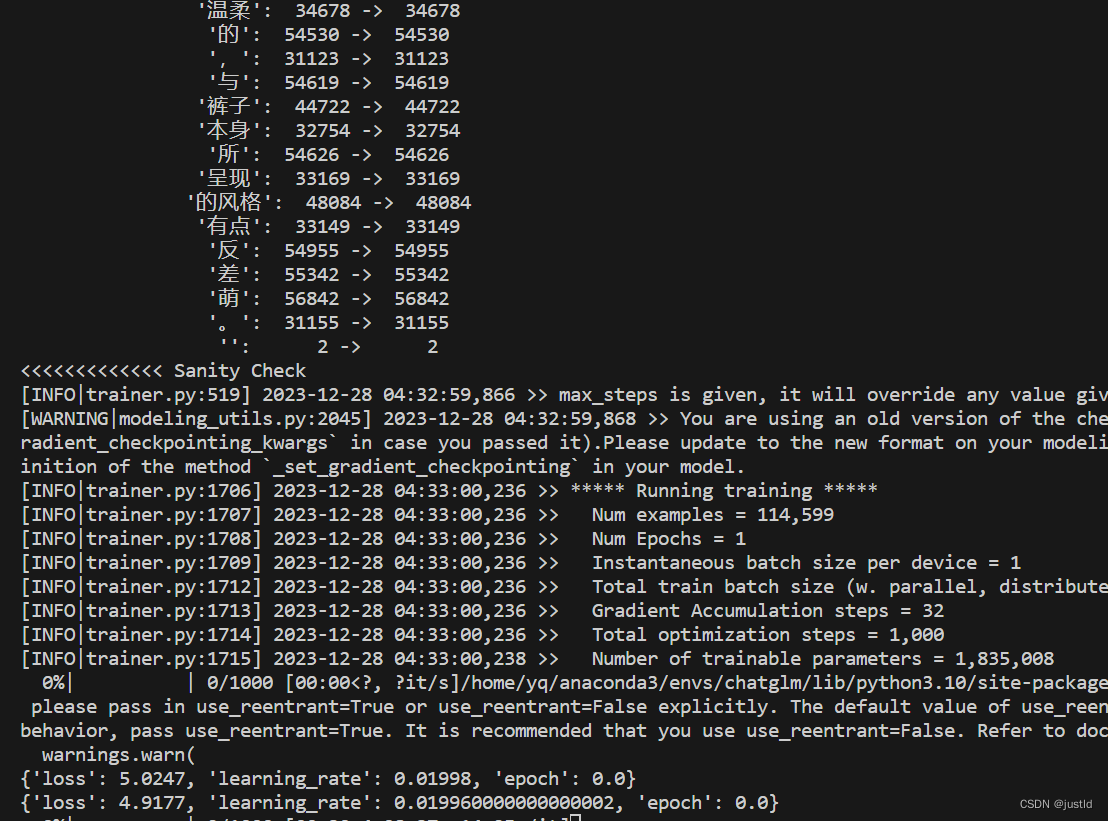
显存占用约16GB:
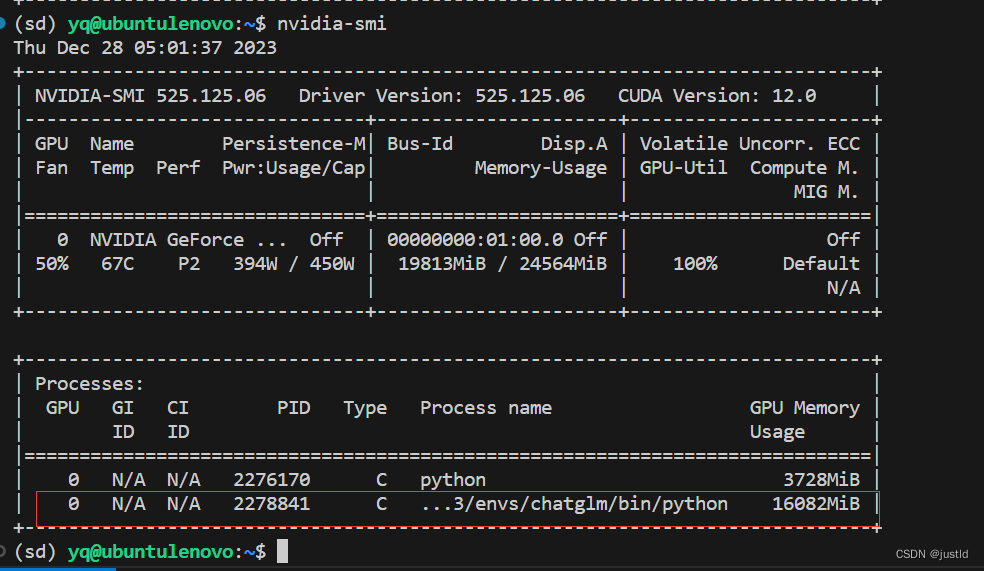
训练结束:

三、部署
获得了微调的模型后,可以很简单的部署(MODEL_PATH改为自己的chatglm3-6b的权重路径,PT_PATH指向微调的路径,PT_PATH的路径再训练结束的日志中):
python inference.py --pt-checkpoint "output/advertise_gen_pt-20231228-043228-128-2e-2" --model chatglm3-6b 效果如下:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!