爬虫练习-获取imooc课程目录
2023-12-17 20:27:35
代码:
from bs4 import BeautifulSoup
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0',
}
id='371' #课程id
html=requests.get('https://coding.imooc.com/class/chapter/'+id+'.html#Anchor',headers=headers).text
print(html)
soup=BeautifulSoup(html,'lxml')
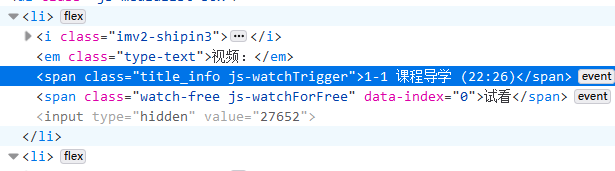
name=soup.find_all("span", "title_info")
for i in name:
print(i.text)
效果:

代码分析:
from bs4 import BeautifulSoup
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0',
}
引入库
设置请求头
id='371' #课程id
html=requests.get('https://coding.imooc.com/class/chapter/'+id+'.html#Anchor',headers=headers).text
print(html)
soup=BeautifulSoup(html,'lxml')
获取网页 使用BeautifulSoup解析
name=soup.find_all("span", "title_info")
for i in name:
print(i.text)
获取全部 class为title_info的span标签
循环输出标签的text
文章来源:https://blog.csdn.net/weixin_42403632/article/details/135049153
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!