自动驾驶感知-预测-决策-规划-控制学习(3):感知方向文献阅读笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
论文题目:《面向自动驾驶场景的多传感器环境感知系统研究》-中国矿业大学,朱良钦
主要目的是快速熟悉自动驾驶方向的一些专业名词与基本概念。
一、文章主题
本文使用摄像头和激光雷达传感器采集环境数据,基于深度学习理论与方法,重点解决自动驾驶行驶场景下车道线检测和三维目标检测的难题。
笔记:感知的硬件设备是摄像头和激光雷达,自动驾驶的车道线检测和三维目标(如车辆、行人、交通标志等)检测也是一个老生常谈和经久不衰的研究方向,那么作者是如何利用深度学习的理论知识在这个方向做出一定的创新呢?
二、摘要阅读
主要研究内容如下:
(1)针对车道线检测任务,提出图像与点云融合的检测方法,在二维图像分割器的基础上, 将检测结果映射到点云中,获取更丰富的深度信息。在图像分割模型上,采用轻量化卷积网络提取特征, 提升特征提取的效率, 并添加跨通道联合注意力模块和改进的空洞空间卷积池化模块, 加强局部细节特征的提取。利用图像车道线检测结果, 融合相机和激光雷达的位姿变换关系获取车道线深度信息。
(2)对于三维目标检测任务,针对单模态数据表达不够充分等缺点,采用 多模态特征融合的三维目标检测算法。先在模型输入前对图像和点云数据进行预 处理, 共同作为算法模型的输入。然后进行特征提取和信息融合, 自动提取不同模态中相关性更大的信息, 突出有效信息并削弱不相关信息。最后量化检测结果,生成预测的目标候选框。
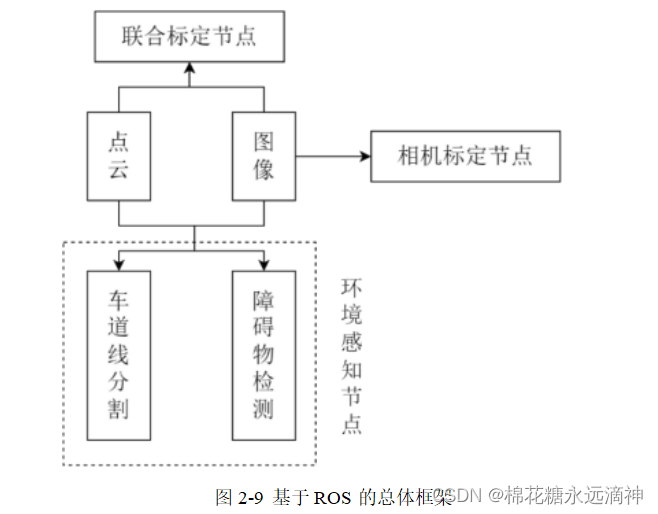
(3)设计了基于 ROS 的多传感器融合感知系统,使用 ROS 便捷的消息通信机制,完成不同传感器多进程间的通信和数据共享。使用 TensorRT 工具将感知算法模型部署在实验硬件平台上, 在保持精度的同时提升算法的推理速度,使 用 FP16 精度相比 FP32 总体速度提升了 127%。最后在自动驾驶开源数据集和实车采集数据集进行了测试验证,车道线分割任务中F1 -score 达到了 75.6,障碍物检测任务中平均精度达到了 62.99。
1.名词理解
①点云是什么?
点云(Point Cloud)是由大量的三维点组成的数据集合,每个点都具有空间坐标和可能的其他属性信息。点云可以看作是对三维物体或场景的采样和表示,它可以通过激光雷达、深度摄像头等传感器获取。
在自动驾驶和计算机视觉领域,点云被广泛应用于三维感知、目标检测、场景重建等任务。通过分析点云数据,可以提取出物体的几何形状、表面法线、颜色信息等。点云数据的处理和分析可以帮助自动驾驶系统理解周围环境,识别和跟踪其他车辆、行人、障碍物等。
点云数据通常以XYZ坐标形式存储,每个点的坐标表示其在三维空间中的位置。此外,点云数据还可以包含其他属性信息,如颜色、反射强度、法线方向等,这些属性信息可以提供更多的场景细节和语义信息。
比如我用C++代码来举个例子:
struct Point
{
float x, y, z; // 点的坐标
float r, g, b; // 点的颜色
};
一个三维点可以包含坐标信息和其三通道的RGB值,那么可以进一步分析出其法线方向、其他属性等。
处理点云数据的常见方法包括点云滤波、点云配准、点云分割、点云特征提取等。近年来,深度学习方法也被广泛应用于点云数据的处理和分析,如基于卷积神经网络的点云分类、目标检测和语义分割等任务。
②二维图像分割器
二维图像分割器是一种计算机视觉技术,用于将输入的二维图像分割成不同的区域或对象。图像分割的目标是将图像中的每个像素分配给特定的类别或区域,从而实现对图像的语义理解和对象识别。图像分割器可以根据不同的任务和应用领域进行设计和实现。
二维图像分割又可以分出来这几个大类:
语义分割:将图像中的每个像素分配给特定的语义类别,例如人、车、树等。这种分割器可以用于自动驾驶、图像理解和场景分析等应用。
实例分割:将图像中的每个像素分配给不同的实例对象,例如不同的人、不同的车等。实例分割器可以用于目标检测、视频分析和人体姿态估计等任务。
边界分割:将图像中的边界或轮廓分割出来,用于图像分析、形状识别和物体测量等应用。
图像分割器通常基于机器学习和深度学习技术,使用训练数据集进行模型训练和参数优化。常见的图像分割算法包括基于传统的图像处理方法(如阈值分割、边缘检测、区域生长等)以及基于深度学习的方法(如卷积神经网络、全卷积网络、U-Net等)。通过使用图像分割器,可以实现对图像中不同区域和对象的准确识别和分析,为各种计算机视觉应用提供基础支持。
③轻量化卷积网络提取特征
轻量化卷积网络是一种针对资源受限环境(如移动设备、嵌入式系统)设计的卷积神经网络,旨在在保持较高性能的同时减少模型的参数量和计算量。这些网络通常采用一些特定的设计策略,以提高模型的效率和速度。
④单模态表达和多模态特征融合的区别
这是一个比较经典的问题。
单模态表达其实顾名思义,是指仅使用一种类型的数据来表示和处理任务。
就拿车道线检测为例,一般有两种经典方法:图像分析和点云特征提取。
图像分析法我以前用过,就是边缘检测+ROI提取+霍夫变换,用一条直线去拟合当前的车道线。
点云特征提取是一种新思路,通过点云处理算法(如点云聚类、曲线拟合等)来提取点云数据中与车道线相关的特征,例如点云中的平面、曲线或其他几何形状,从而得到车道线的位置和形状。
这两种方法都是单模态的表达。当然,这两种肯定各有各的缺点,所以才需要去融合起来,实现多模态。
多模态特征融合是指将来自不同数据源的特征进行融合,以提高任务的性能和准确性。在车道线检测任务中,可以将图像和点云数据的特征进行融合,以获取更全面和准确的车道线信息。
以下是一些常见的多模态特征融合方法:
特征级融合:将从图像和点云中提取的特征进行连接、拼接或加权求和等操作,得到一个综合的特征量。这种方法简单直接,但可能无法充分利用不同数据源的特点。
模型级融合:使用不同的模型分别处理图像和点云数据,然后将它们的输出进行融合。可以使用平均、加权平均或投票等方法来融合不同模型的预测结果。
注意力机制:使用注意力机制来动态地对不同数据源的特征进行加权融合。可以通过学习注意力权重,使模型自动关注对于车道线检测更重要的特征。
多模态融合网络:设计专门的网络架构来处理多模态数据。这些网络可以同时接收图像和点云数据,并在网络中进行特征提取和融合。例如,可以使用多分支网络或多通道卷积神经网络来处理不同数据源的特征。
⑤基于ROS的多传感器融合感知
基于ROS的多传感器融合感知系统是一种常见的多模态感知系统,它可以将来自不同传感器的数据进行融合,以提高感知任务的性能和准确性。
对于车道线检测,可以使用摄像头和激光雷达等传感器获取图像和点云数据。通过将这些数据进行融合,可以提高车道线检测的准确性和鲁棒性。例如,可以使用摄像头获取图像数据,通过图像处理算法检测车道线的位置和形状;同时,使用激光雷达获取点云数据,通过点云处理算法进一步验证和补充车道线的信息。
对于三维目标识别,可以使用多种传感器,如摄像头、激光雷达和雷达等,获取丰富的感知信息。通过将来自不同传感器的数据进行融合,可以提高目标识别的准确性和鲁棒性。例如,使用摄像头获取图像数据,通过计算机视觉算法进行目标检测和识别;同时,使用激光雷达和雷达获取点云和距离信息,通过点云处理和距离测量算法进一步验证和补充目标的位置和形状。
⑥TensorRT工具
TensorRT是英伟达(NVIDIA)推出的用于高性能深度学习推理的优化和部署工具。它可以将经过训练的深度学习模型转换为高效的推理引擎,以在生产环境中实现快速的推理速度和低延迟。
TensorRT通过使用各种优化技术来提高推理性能,包括网络剪枝、量化、层融合、内存优化等。这些优化技术可以减少模型的计算量、内存占用和推理时间,从而提高深度学习模型在边缘设备和数据中心的推理效率。
TensorRT支持多种深度学习框架,如TensorFlow、PyTorch和ONNX等,可以将这些框架训练的模型转换为TensorRT可识别的格式。转换后的模型可以在TensorRT的推理引擎上进行部署和优化,以获得更高的推理性能。
TensorRT还提供了C++和Python的API,使开发者可以方便地集成和使用TensorRT。开发者可以使用TensorRT API加载和推理优化后的模型,还可以进行批处理、异步推理和动态形状推理等操作。
基于ROS的多传感器融合感知系统可以提供更全面、准确和鲁棒的感知能力,而TensorRT工具可以将深度学习模型转换为高效的推理引擎,提供快速的推理速度和低延迟,使得感知算法模型可以在实验硬件平台上高效地运行。
2.总结摘要
就是说作者针对车道线检测和三维目标识别,算法方面,同时使用了图像处理和点云特征的多模态特征提取思路,获取了车道线的更深度的信息和准确率更高的三维目标识别候选框。系统实现上,部署了摄像头和激光雷达分别获取图像信息和三维点云信息,由ROS的消息订阅与主题发布机制来进行数据通信和共享,最后用英伟达的TensorRT完成了模型的部署。
三、绪论解析

大部分的论文都是这样一个格式,绪论部分讲述一个背景意义,以及当前国内外的研究情况。
文章的主旨是针对自动驾驶中多传感器三维环境感知系统展开研究, 采用三维激光雷达和 RGB (Red,Green,Blue)单目相机, 基于深度学习理论和方法, 重点攻克多模态数据匹配融合和复杂交通工况下三维目标检测、分割难点, 使感 知系统在城市及非结构化场景下具备优良的鲁棒性、准确性与适应性。
1.首先分析了车道线检测方面有三类工作
(1)基于相机的车道线检测方法:即对图像进行一系列的处理
(2)基于激光雷达的车道线检测方法:即利用三维点云的数据进行算法分析
(3)基于相机和激光雷达融合的车道线检测方法:即二者的综合
2.又分析了三维目标检测研究的三类工作
(1)基于图像的三维目标检测方法
(2)基于激光点云的三维目标检测方法
(3)基于多模态数据融合的三维目标检测方法
3.综述各章节内容
第一章: 指出多传感器融合方法在环境感知任务中的先进性, 最后总结了车道线检测、三维目标检测的感知任务当前的国内外研究现状, 从而确定研究内容和方向。
第二章: 介绍了本课题使用的多传感器感知系统, 包括系统的硬件平台、软件方法。针对环境感知这一任务以及具体的需求确定算法设计方案, 包括整体的方案设计和各个检测任务的算法设计。
第三章:主要描述了基于图像的车辆行驶车道线分割算法和基于图像与点云 信息融合的车道线深度获取。在将图像输入车道线分割算法之前, 先去除图像畸 变,使其更贴近真实场景。针对车道线分割算法,先使用 GhostNet 提取图像特 征,在此基础上添加跨通道联合注意力模块和改进空洞空间卷积池化模块提取更 细致的特征, 再使用逐行像素检测的算法对车道线进行识别, 并在训练过程添加 辅助分割网络优化整体网络参数。针对车道线深度获取, 主要任务是获取相机和 激光雷达传感器的外参矩阵, 介绍了张正友标定法获取相机内参,静态联合标定 方法和流程,以及基于 ROS 话题机制同步获取两类传感器的数据,最后根据外 参矩阵将车道线从图像映射到点云中,从而获取车道线的深度信息。
第四章: 本章节研究的是一种多传感器融合的三维障碍物检测算法。 首先, 对点云数据进行了直通滤波、统计滤波和体素滤波等预处理方式进行降噪和降采样,并使用地面平面拟合算法滤除地面点云, 减少无效信息对后续处理的干扰。 然后,将处理后的点云数据转化为鸟瞰图,并使用 ResNet 进行特征提取,以提 高算法效率和精度。采用特征级融合的方式, 结合 FPN 和 PAN 的网络结构, 输 出不同尺度的三维候选框, 并通过分类和回归分支的处理, 得到最终的三维目标框。
第五章:针对本课题中车道线分割和障碍物检测两项任务算法的实验验证以 及模型部署的结果分析。对于车道线分割任务, 使用 DataCC 数据集(CULane 数据集和实车数据集)。对于障碍物检测任务, 使用 DataKC 数据集(KITTI 数据集和实车数据集)。根据与相关的优秀算法进行指标对比,并在对应数据集上进行 效果可视化,综合评估算法模型的性能,最后对比不同精度下的 TensorRT 模型 部署效率,确定部署方案。
四、硬件与软件设计


激光雷达被固定在车体顶部, 可以获得更为开阔的视野。摄像机则安装在激 光雷达的下方, 与激光雷达的重合视野更大。
核心计算设备:
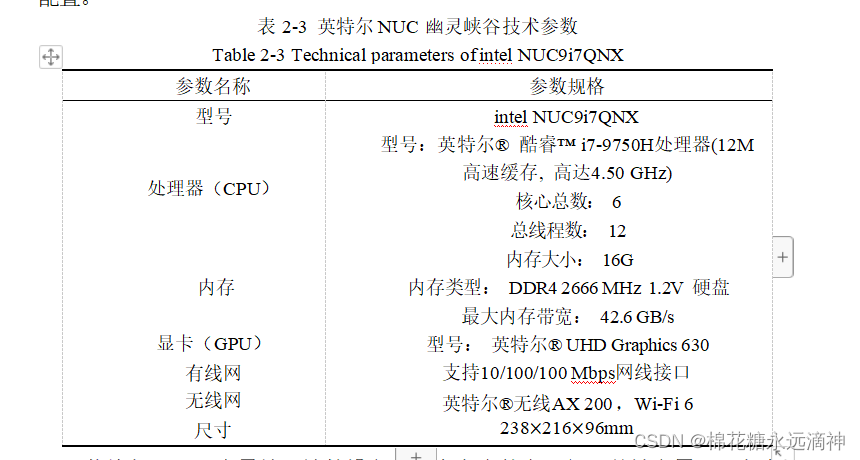
1.总体方案
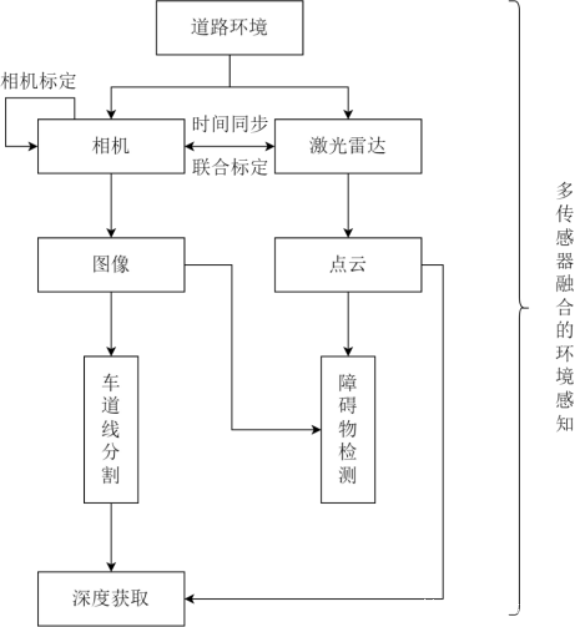
2.车道线语义分割算法
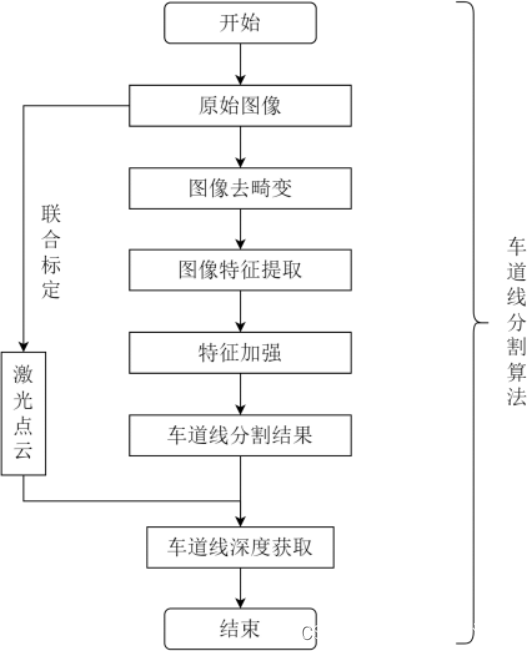
3.三维障碍物检测算法
4.ROS框架
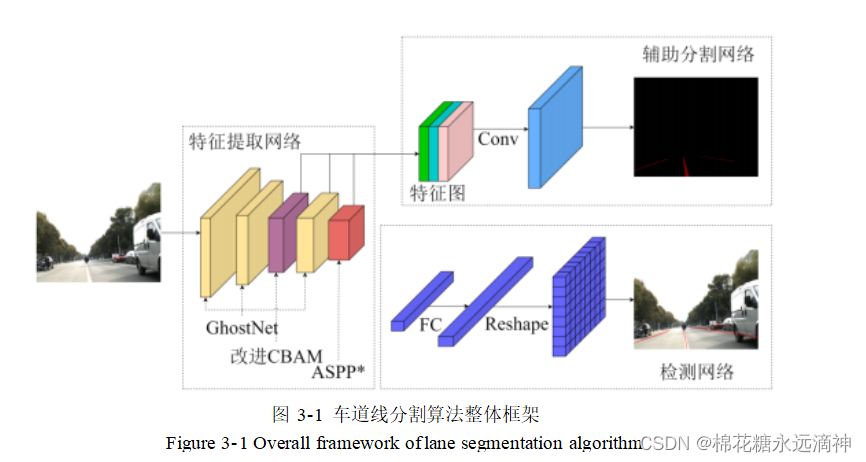
五、车道线分割算法实现
本课题使用基于行驶场景图像的深度学习算法,整体算法流程如图 ,首 先采用了轻量化的特征提取网络GhostNET来提取图像中的关键特征。为了增强特征的表达 能力,还引入了跨通道联合注意力模块, 以进一步提升网络性能。在这个基础上, 采用了改进的空洞空间卷积池化技术, 以扩大感受野的范围, 使网络能够更好地 理解图像中的上下文信息, 从而更好地识别车道线, 提高车道线的检测准确性。 在车道线检测方面, 采用了逐行像素检测的方法, 极大地提升了处理效率, 这种 方法能够快速而准确地识别每一行像素中的车道线信息, 从而有效地降低了计算 复杂度。此外, 在训练过程中还引入了辅助分割算法, 对整个网络的参数进行优 化, 以进一步提高车道线检测的性能和稳定性。最后, 输出感兴趣的车道线像素区域,得到了基于图像的车道线分割结果。
1.什么是特征?
在机器学习和深度学习中,特征(Feature)是指从原始数据中提取出来的有用信息。在图像处理中,特征可以是图像中的边缘、角点、纹理等视觉信息。在自然语言处理中,特征可以是文本中的单词、词性、句法结构等语言信息。
特征提取是机器学习和深度学习中非常重要的一步,因为原始数据往往包含大量的冗余信息和噪声,而特征提取可以帮助我们从中提取出有用的信息,减少冗余和噪声的影响,从而提高模型的性能和准确度。
在深度学习中,特征提取通常是通过卷积神经网络(CNN)来实现的。CNN可以自动学习图像和文本中的特征,从而减少人工特征工程的工作量。
六、三维点云进行物体识别

首先是对点云数据进行预处理,使用直通滤波、统计滤波、 体素滤波完成对点云的去噪和降采样, 又使用地面平面拟合算法完成对地面点云 的滤除,预处理阶段大幅降低了点云数量, 并去除了无效点云, 有利于模型对有 利信息的提取; 其次是特征提取阶段,将处理后的点云数据转为鸟瞰图, 使用与 单目图像一样的特征提取网络 ResNet,有效减少原始数据的冗余,提高了算法的 效率;最后, 使用特征级融合方法, 增加 FPN 和 PAN 的网络结构,输出不同尺度的三维候选框,通过更精细的分类和回归分支确定最终的三维目标框。
七、算法结果分析与比较
针对本课题中车道线分割和障碍物检测两项任务算法的实验验证 以及模型部署的结果分析,本课题的算法在实验中都取得了显著的成果。
笔记:作者找了网上公开的北京地区的道路数据集约8000张,以及自己实验室搭载单目摄像头和激光雷达的实验小车采集的5000张数据集(内含三维点云)。
对于车道线分割算法,在 CULane 数据集和实车数据集的所有场景中, 本文算法的 F1 分数达到了 75.6%,相较于 PINet 提升了 1.2%。此外, 还展示了车道线深度获取 的效果, 可以车辆后续的决策控制提供更多有价值的辅助信息。对于障碍物检测 算法,在 KITTI 开源数据集和实车数据集上进行了测试, 与相关优秀算法的 mAP 分数相比, 本文算法也有了不小提升。此外, 本课题中多模态数据融合的方案在 目标障碍物被遮挡、小目标的场景下也能完成正确识别, 相比单模态的检测模型 具有更好的鲁棒性和准确性。最后使用 TensorRT 部署模型, 在 FP16 精度下总体速度提升约 127%。
八、自动驾驶感知方面的关键知识点:
自动驾驶感知是指自动驾驶系统通过感知环境中的各种信息来理解和识别道路、障碍物、交通标志等,并做出相应的决策和控制。以下是自动驾驶感知方面的一些关键知识与技术的总结:
传感器技术:自动驾驶系统使用多种传感器来获取环境信息,包括摄像头、激光雷达、毫米波雷达、超声波传感器等。这些传感器可以提供车辆周围的图像、点云和距离等数据。
计算机视觉:计算机视觉是自动驾驶感知的核心技术之一,通过图像处理和分析来识别道路、车辆、行人、交通标志等。深度学习在计算机视觉中发挥了重要作用,可以通过卷积神经网络(CNN)等模型进行目标检测、语义分割和实例分割等任务。
点云处理:激光雷达可以生成车辆周围的点云数据,点云处理技术可以对点云进行滤波、分割和聚类等操作,以提取出障碍物的位置、形状和运动信息。
传感器融合:自动驾驶系统通常会将多个传感器的数据进行融合,以获得更全面和准确的环境感知。传感器融合可以通过滤波器(如卡尔曼滤波器和粒子滤波器)和融合算法(如扩展卡尔曼滤波器和无迹卡尔曼滤波器)来实现。
地图与定位:地图和定位是自动驾驶感知的重要组成部分。高精度地图可以提供道路拓扑结构、车道线和交通标志等信息,而定位技术(如GPS、惯性测量单元和视觉里程计)可以确定车辆在地图中的位置和姿态。
目标跟踪与预测:自动驾驶系统需要对周围的车辆、行人和障碍物进行跟踪和预测,以预测它们的未来行为并做出相应的决策。目标跟踪和预测技术可以使用滤波器、轨迹预测算法和机器学习模型等来实现。
人机交互:自动驾驶系统需要与驾驶员和乘客进行有效的交互,以传达系统的状态、意图和决策。人机交互技术可以包括语音识别、自然语言处理、语音合成和图形界面等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!