高光谱分类论文解读分享之基于多模态融合Transformer的遥感图像分类方法
IEEE TGRS 2023:基于多模态融合Transformer的遥感图像分类方法
题目
Multimodal Fusion Transformer for Remote Sensing Image Classification
作者
Swalpa Kumar Roy , Student Member, IEEE, Ankur Deria , Danfeng Hong , Senior Member, IEEE,
Behnood Rasti , Senior Member, IEEE, Antonio Plaza , Fellow, IEEE, and Jocelyn Chanussot ,Fellow, IEEE
关键词
Convolutional neural networks (CNNs), multihead cross-patch attention (mCrossPA), remote sensing (RS), vision transformer (ViT).
研究动机
在原始的ViT模型中,如果我们将HIS作为输入,由于HIS巨大的光谱波段数量,可能会导致过拟合;并且对于其他模态的融合,如果采用拼接的方式去实现信息互补,会加剧这种问题。
模型
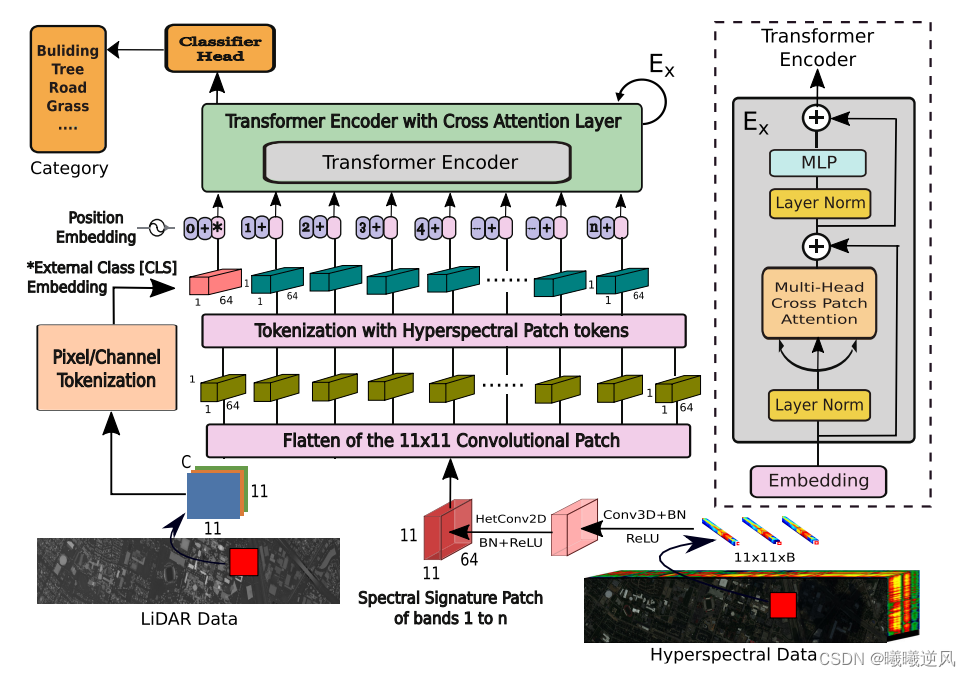
与卷积神经网络相比,ViT在图像分类任务中具有良好的性能。因此,许多研究人员尝试将ViT应用到高光谱图像分类任务中。为了获得满意的性能,接近于CNN,变换需要更少的参数。VITS和其他类似的变换使用外部分类(CLS)标记,该标记是随机初始化的,通常不能很好地推广,而其他多模式数据集的来源,如光检测和测距(LiDAR),提供了通过CLS来改进这些模型的潜力。提出了一种新的多模式融合变换(MFT)网络,该网络包括用于HSI土地覆盖分类的多头交叉斑块注意力(MCrossPA)。我们的mCrosspA利用了除了变换编码器中的HSI之外的其他补充信息源来实现更好的泛化。使用标记化的概念来生成CLS和HSI斑块标记,帮助在精简和分层的特征空间中学习独特的表示。在广泛使用的基准数据集上进行了大量的实验,例如休斯顿大学(UH),特伦托大学(Trento),南密西西比湾公园大学(MUUFL),和Augsburg。我们将提出的MFT模型的结果与其他最先进的变压器、经典的CNN和传统的分类器模型进行了比较。该模型的卓越性能归功于mCrosSPA的使用。
亮点
提出了一种新型的多模融合transformer网络(MFT),其中包含multihead cross patch attention(mCrossPA)机制,将补充信息作为cls token,将HSI作为patch token。
论文以及代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!