深度学习 | Pytorch深度学习实践 (Chapter 12 Basic RNN)
?
?
十二、Basic RNN —— 实际上就是对线性层的复用
?????????
使用RNN最重要的两点:
- 了解序列数据的维度;
- 循环过程所用的权重共享机制;
一般就是自己写个循环,权重层重复用就行了;
?
?
回顾:----------------------------------------------------------------------------------------------------------------------
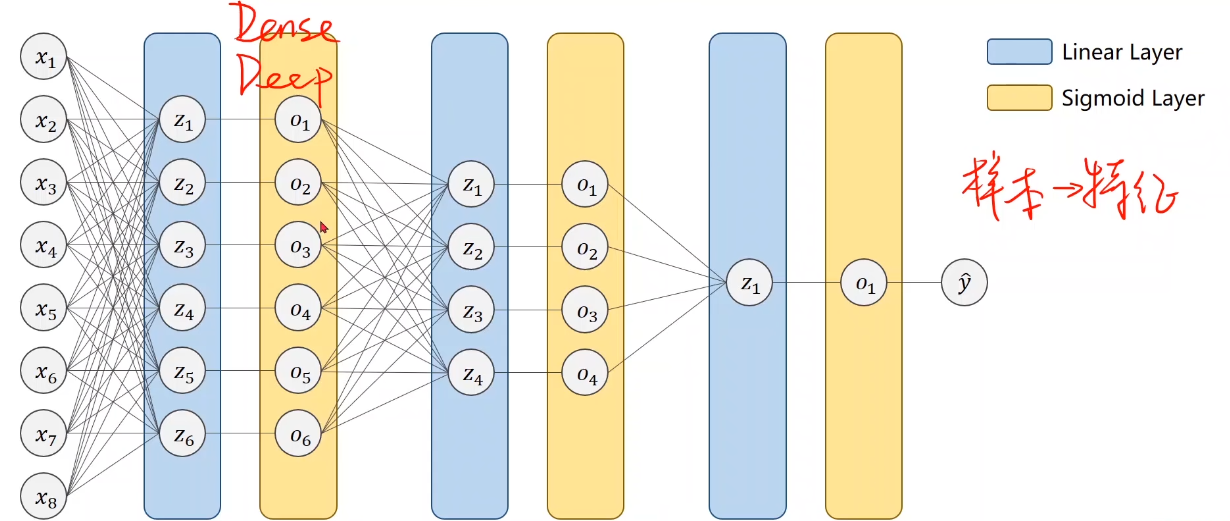
??????? 以前是用的神经网络也称为Dense、Deep(稠密层)的网络。
????????
??????? 但现在来考虑一下这个情况:
????????
??????? 若使用稠密的网络,把其拼成有九个维度的向量,但如果序列很长而且维度很高,则权重数量太多到难以处理。
????????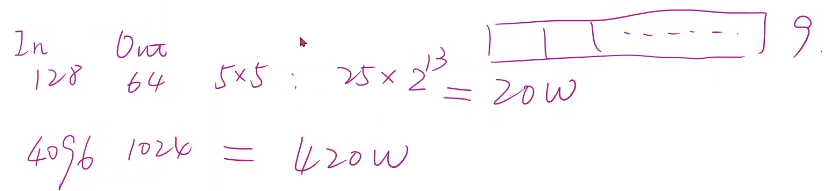
??????? 全连接层的权重要比卷积神经网络大很多,这是由于卷积神经网络虽然运算复杂但整个图像上的卷积核是共享的。
??????? —— 因此,RNN就是专门用来处理带有序列模式的数据,同时也要结合权重共享的思想来减少权重数量;不仅要考虑x1,x2之间的连接关系,还要考虑其时间上的先后序列关系(即x1和x2的数据依赖于x2/3)
????????
?????????除了天气等一系列经典的时间顺序的数据以外,自然语言也是一种有着序列关系的数据;
?
?
12.1、RNN Cell
?
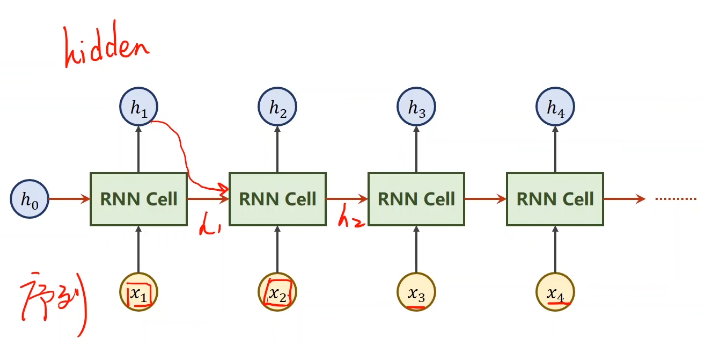
????????RNN Cell:xt是指在序列中t时刻相应的数据,它可以把3维向量变为5维的向量。不难看出其本质为一个线性层。
?????????
?????????和普通的线性层相比,这里的RNN Cell是可以共享的。将上面的图像展开后就是下面这样:
?????????
12.1.1、和线性层的区别
在于:
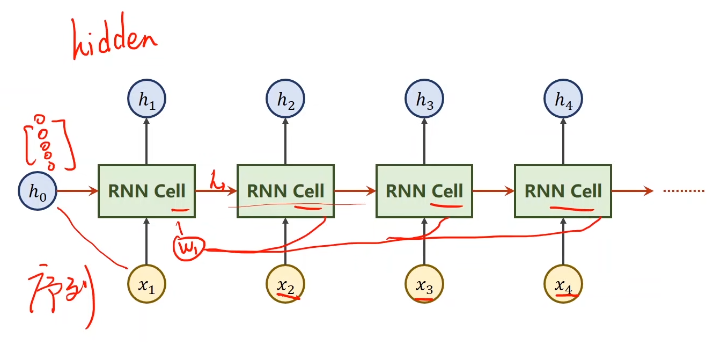
????????由于每一项的数据都和前一项相关,所以送进RNN Cell的数据不止其本身的数据,还要有上一项的数据(也就是图中的红色箭头。)
??????? 而对于x1来说也需要一个相应的h0,表示先验知识。比如果要通过图像来生成文本,那么h0就设成一个CNN+Fc,如果没有的话就可以把它设成一个对应维度的0向量)。
????????注意,这里所有的RNN Cell是同一个层;
????????
??????? 若用公式来表示一下这个循环过程:
????????
?
?
12.1.2、具体计算过程
?
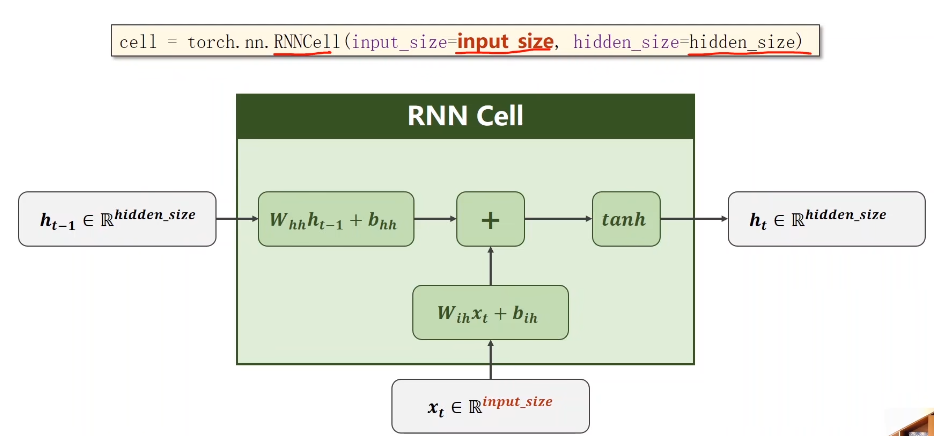
????????xt为输入,input_size为输入维度,hodden_size为隐层维度。
????????
- 先将输入做一次线性变化,将其维度(input_size)转为隐藏层的维度(hidden_size)——Wih是一个hidden_size×input_size的矩阵;
- 而上一个隐层的输入的权重矩阵就是hidden_size×hidden_size;
- 然后将他们俩相加就完成了信息融合;
- 接着要做一次激活,tanh被认为是一个效果较好的激活函数,得到的结果就是ht了;
????????实际上黄色阴影和红色阴影部分可以写到一起。见上面图上面部分的红色笔迹。
??????? 在构建RNN Cell的时候,实际上的工作就是把x和h拼起来。
??????? 最后的公式即为:
????????![]()
?
?
12.2、RNN
?
??????? 那什么叫RNN呢?
—— 将RNN Cell以循环的形式把序列一个一个送进去,然后依次算出隐层的过程,就叫做循环神经网络,其中RNN Cell是其中的一个单元。
??????? 在pytorch中有两种构造RNN的方式:
??????? 1、做自己的RNN Cell,自己设计处理逻辑的循环。
??????? 2、直接使用RNN。
?
?
12.2.1、RNN Cell in Pytorch
????????
#要设定的参数主要是两个:输入维度和隐层的维度
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
#调用方法
hidden = cell(input, hidden)
# 本质上还是一个线性层。??????? 使用时注意维度的要求。
????????
举例:----------------------------------------------------------------------------------------------------------------------
先假设我们的参数是下面这样的:
- 𝑏𝑎𝑡𝑐?𝑆𝑖𝑧𝑒 = 1 (N)
- 𝑠𝑒𝑞𝐿𝑒𝑛 = 3 (有多少个x)
- 𝑖𝑛𝑝𝑢𝑡𝑆𝑖𝑧𝑒 = 4 (每个x的维度)
- ?𝑖𝑑𝑑𝑒𝑛𝑆𝑖𝑧𝑒 = 2
- 那么RNNCell的输入以及输出就是:
- input.shape = (batchSize,inputSize)
- output.shape = (batchSize,outputSize) —— 在h0的时候也要满足这个要求。
- 整个序列的维度就是:
- dataset.shape = (seqLen,batchSize,inputSize)
- 注意这里seqLen放第一位,这是为了在循环的时候,每次拿出当前循环时刻t的张量,也就是后两项参数,显得自然一些;
?代码:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
#(seq, batch, faetures)
dataset = torch.randn(seq_len, batch_size, input_size)
#构造h0
hidden = torch.zeros(batch_size, hidden_size)
#训练的循环
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('input size:',input.shape)
hidden = cell(input, hidden)
print('outputs size:',hidden.shape)
print(hidden)
?结果:
????????
?
?
12.2.2、RNN in Pytorch
?
# 仅多了个指明层数的参数num_layers
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers = num_layers)
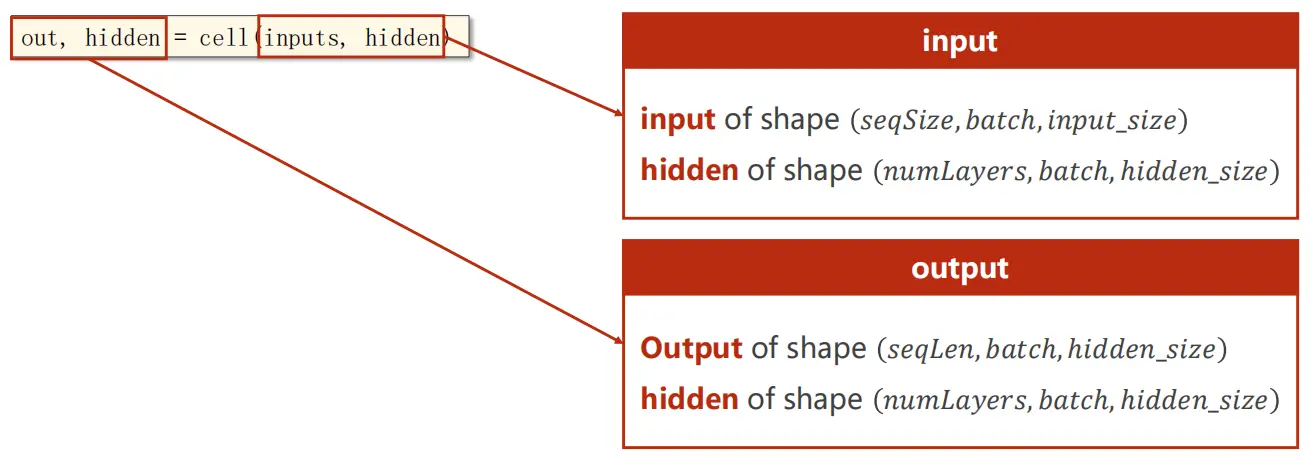
# 输出的out是指h1,...,hN,而hidden则是特指最后一个hN
out, hidden = cell(inputs, hidden)
# 这样一来,就不用自己写循环了
# inputs为整个输入的序列
???????? ?
?
?
??????? 也要注意维度!
????????
?
????????要确认的数多了一个numlayer:
- 𝑏𝑎𝑡𝑐?𝑆𝑖𝑧𝑒
- 𝑠𝑒𝑞𝐿𝑒𝑛
- ?𝑖𝑛𝑝𝑢𝑡𝑆𝑖𝑧𝑒, ?𝑖𝑑𝑑𝑒𝑛𝑆𝑖𝑧𝑒,
- 𝑛𝑢𝑚𝐿𝑎𝑦𝑒𝑟s
????????输入以及h_0的维度要求:
- input.shape = (seqLen, batchSize, inputSize)
- h_0.shape = (numLayers, batchSize, hiddenSize)
????????输出以及h_n的维度要求:
- output.shape = (seqLen, batchSize, hiddenSize)
- h_n.shape = (numLayers, batchSize, hiddenSize)
?
????????numLayers的结构:
????????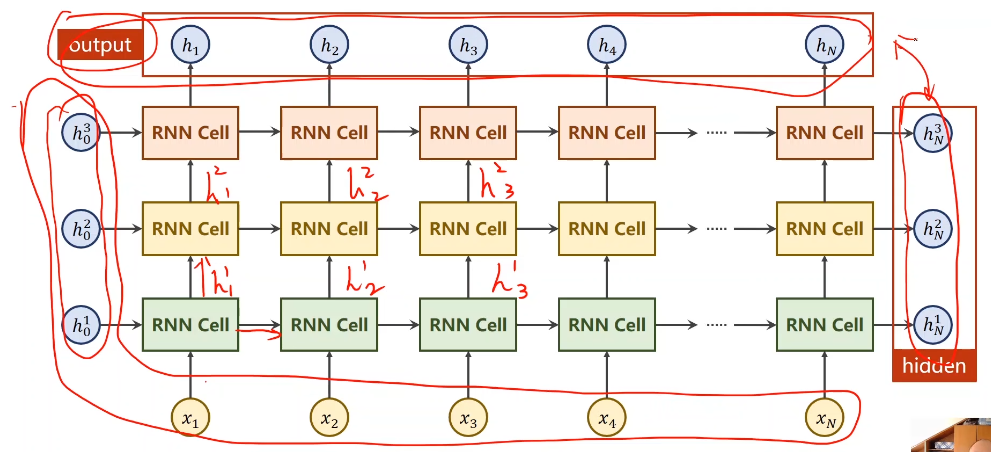
????????每个xi结合多个Hij后得到输出的hi;
????????这里同样颜色的RNN Cell全都是一个层;
?
举例:----------------------------------------------------------------------------------------------------------------------?
?代码:
import torch
# 模型参数
batch_size = 1 #仅在构造h0时才会用到
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,
num_layers=num_layers)
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size)
out,hidden = cell(inputs,hidden)
print('Output size:',out.shape)
print('Output:', out)
print('Hidden size:', hidden.shape)
print('Hidden:',hidden)?结果:
? 
12.2.3、RNN的其他参数
?
????????batch_first:
????????若设为True,那么batchSize和seqLen两个参数的位置就会互换,输入时要把batch_size作为第一个参数;

?
?
12.2.4、一个例子 seq → seq
?
- 例子:把模型训练成一种序列到序列的转换模型,比如将"hello"转化为"ohlol”。
- 对应的流程图如下所示:

?
- 第一步,将输入的字符向量化,因为RNN Cell的输入得是向量:?
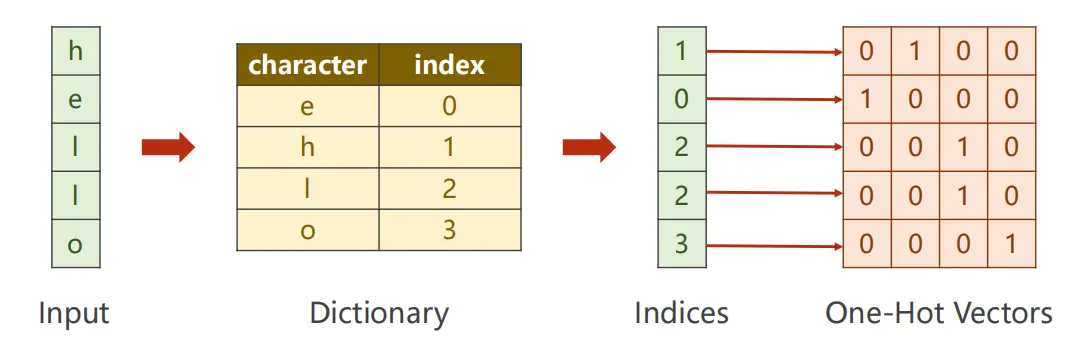
- 此时,InputSize就是4(矩阵的宽)
?
????????一般都是根据字符来构造词典,并分配索引,再通过独热向量来进行查询字符。
????????宽度就是词的种类数量;?
?
- 这样一来,就可以化为一个多分类问题,也就是把输入经过RNN来分类到对应的输出上去。可以接一个softmax 把这个变成一个分布,就可以拿去训练了;

?
????????整个代码流程如下:
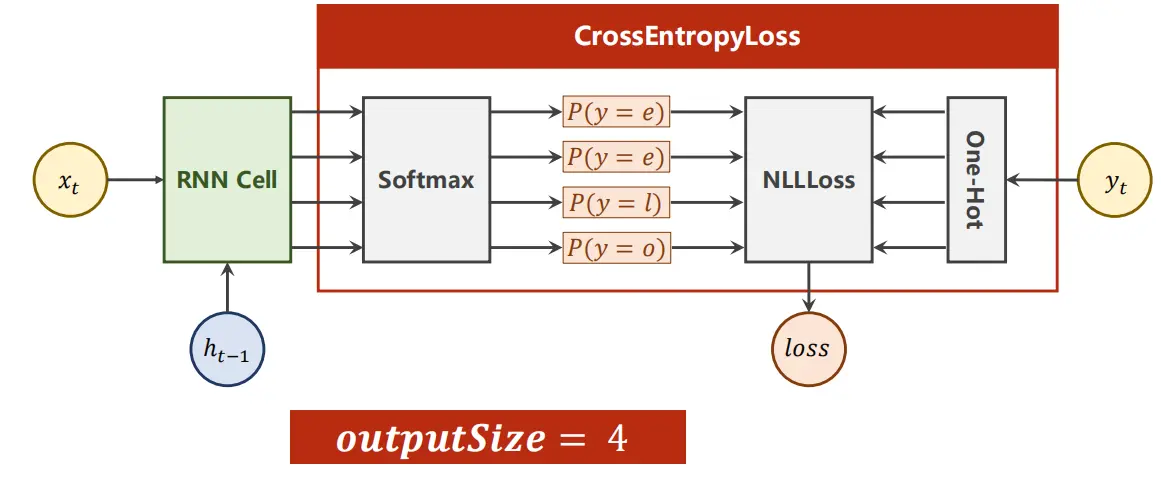 ?
?
?
?代码:
1)RNN Cell实现:
import torch
# 模型参数
batch_size = 1 #仅在构造h0时才会用到
input_size = 4
hidden_size = 4
# 1、数据准备:将hello输出为ohlol
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3]
y_data = [3,1,2,3,2]
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] #seq x input_size
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #(segLen , batchSize, inputSize)
labels = torch.LongTensor(y_data).view(-1,1) #变为seq x 1
# 2、定义模型
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(Model,self).__init__()
#self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
def forward(self,input,hidden):
hidden = self.rnncell(input,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size)
net = Model(input_size,hidden_size,batch_size)
# 3、选择优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.1)
# 4、训练
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden() #初始化h0
print('Predicted string:',end='')
for input,label in zip(inputs,labels):
hidden = net(input,hidden)
loss += criterion(hidden,label) # loss需要累加计算图
#输出预测值
_,idx = hidden.max(dim=1)
print(idx2char[idx.item()],end='')
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
?结果:
????????
?
2)若使用RNN
import torch
num_layers = 1
seq_len = 5
input_size = 4
hidden_size = 4
batch_size = 1
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size #用于构造隐层的h0,如果放外面构造的话这一句不用也可以,但是一般都是放里面构造的
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size = self.input_size, hidden_size = self.hidden_size, num_layers=self.num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers)
#数据
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
#训练,用RNN
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
print('Predicted string:', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch[%d/15] loss=%.4f' % (epoch+1, loss.item()))
?
?
12.3、独热编码与嵌入层
?
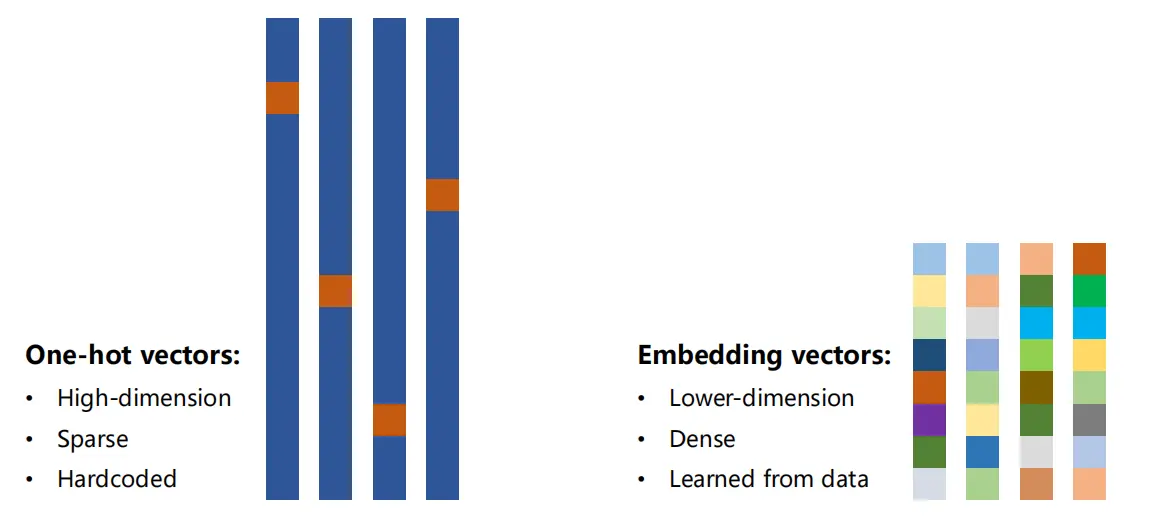
????????独热向量的缺点:
- 维度太高;
- 向量过于稀疏;
- 是硬编码的,即每个词对应的向量是早就编码好的;
????????目标就是要变成:
- 低维;
- 稠密;
- 学习的;
——>常用的方式叫嵌入层Embeding:把高维,稀疏的样本映射到低维,稠密的空间当中去 - (即降维,其实可以高低互转,看情况);
?
????????降维示意图
????????
?????????通过嵌入层,就可以直接学习一个单词,而不是一个个字母;
?????????
????????这样一来,把网络变成下面这样的结构:
????????????????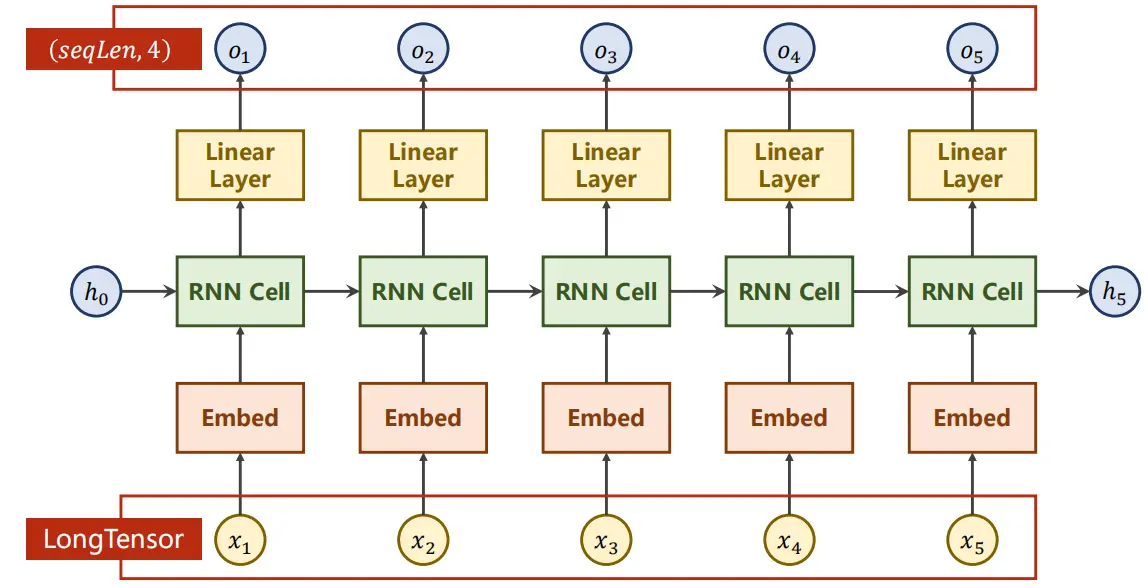
经过Embed把独热向量变成稠密表示,最上面的线性层用于调整维度
?
- Embedding类,但是常用的就前两个参数
class torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None)
???????? ?
?
框起来的第一个参数代表input的维度;第二个参数代表了矩阵的宽和高
????????
????????*就是inputsize,就是seq×batch
?????????
线性层的参数和输入输出
其实就是把维度相同的input和output进行转换;
?????????
交叉熵的参数和输入输出
这里的输入可以加入维度di,反正最终的结果就是每个维度上的交叉熵求和;
?代码:
import torch
# embedding层
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size
,hidden_size=hidden_size
,num_layers=num_layers
,batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x) #这样就可以变成稠密的向量
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1,num_class)
#一堆参数
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
#准备数据
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # (batch * seq_len)
inputs = torch.LongTensor(x_data).view(batch_size, seq_len)
labels = torch.LongTensor(y_data)
#实例化模型并构造损失函数和优化器
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
#训练
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted string:', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch[%d/15] loss=%.4f' % (epoch+1, loss.item()))
?结果:
???????? ?
?
????????可以看到:能够更早的获得ohlol,这是因为模型的学习能力比之前要强
?
Homework:
1、LSTM
???????? ?
?
????????遗忘门,前面来的数据乘上(0,1)的参数,从而使其少了一部分?
???????? ?
?
????????简单来说就是运用上一层的数据来构建下一层的,有点像迭代算法。但是这种方法可以减小梯度消失的情况;
???????? ?
?
????????σ函数就是
????????这样一来就多了一条c t+1的通路,方便反向传播。
????????一般来说,LSTM的效果要比RNN好得多,但是其运算较为复杂。所以时间复杂度也就高,那么就采用折中的方法:
????????GRU,就是下面这堆公式
????????
?????????W就是对应的权重。在构造cell时只需要拿来做上面相应的运算就可以了;
?
作业2:用下GRU来训练模型;
?
部分参考于
讲解视频:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!