生成模型 | GAN系列生成系列论文及代码调研总结
?-------------? 生成模型 相关系列直达 ? -------------------------------------
🫧 GAN | 代码简单实现生成对抗网络(GAN)(PyTorch)_gan网络代码-CSDN博客
🫧?生成模型 | GAN系列生成系列论文及代码调研总结-CSDN博客
🫧 VAE 正在更新中
🫧 Flow 正在更新中
🫧 Diffusion Model 正在更新中
本文主要讲解生成模型中的GAN系列相关模型
目录
1.GAN(Generative Adversarial Network)生成对抗学习网络
1.GAN(Generative Adversarial Network)生成对抗学习网络
Paper : 1406.2661.pdf (arxiv.org)
Code : goodfeli/adversarial: Codeand hyperparameters for the paper "Generative Adversarial Networks"(github.com)
-
一般来说GAN由两种网络构成G(Generator)和D(Discriminator),分别用于生成图片和判断真假。
在两个网络互相博弈过程中,两个网络不断学习和升级,G生成的图片越来越像真的,D判断真假的能力越来越高。此时抛弃D,只留下G,用于图片的生成,此时我们便得到一个优质的图片生成器。
-
AN的局限性:
没有用户控制能力:在传统的GAN里,随机输入一个噪声,随机输出一幅图像。无法根据用户的要求,输出用户所需要的图像。
低分辨率和低质量的图
改善GAN:
-
提高GAN的用户控制能力
-
提高GAN生成图片的分辨率和质量
为了达到这一目的,进而产生了下述三种优化后的网络:
-
?pix2pix:有条件的使用户输入,使用成对的数据进行训练
-
CycleGAN:使用不成对的数据进行训练
-
pix2pixHD:生成分辨率更高,质量更高的图像。?
以mnist手写数据集为例、GAN网络工作的流程如下:
-
生成网络从随机数据开始,生成一张图像
-
生成的图像被输入到鉴别器中、鉴别器判断它与ground truth数据之间的差异
-
鉴别网络分别考虑他们真假的可能性
2.DCGAN
DCGAN:UNSUPERVISED REPRESENTATIONLEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
Paper : 1511.06434.pdf (arxiv.org)
Code : ×

3.CGAN
Conditional GenerativeAdversarial Nets
Paper : 1411.1784.pdf (arxiv.org)
Code : ×
4.2021.11.01_Project GAN
Projected GANs Converge Faster
Paper : 2111.01007.pdf (arxiv.org)
生成对抗网络 (GAN) 可生成高质量的图像,但训练起来具有挑战性。它们需要仔细的正则化、大量的计算和昂贵的超参数扫描。我们通过将生成的和真实的样本投射到一个固定的、预训练的特征空间中,在这些问题上取得了重大进展。由于发现判别器无法充分利用预训练模型更深层的特征,我们提出了一种更有效的策略,可以跨通道和分辨率混合特征。我们的投影 GAN 可提高图像质量、采样效率和收敛速度。它还与高达100万像素的分辨率兼容,并在22个基准数据集上推进了最先进的Fréchet起始距离(FID)。重要的是,预计 GAN 与以前最低的 FID 相匹配的速度提高了 40 倍,在相同的计算资源下,将时钟时间从 5 天缩短到不到 3 小时。
与gan的目标函数对比如下

主要修改了俩种方法
?Multi-scale discriminators
? Feature map : 8×8,16×16,32×32,64×64
?Random Projections
?Cross-Channel Mixing(CCM)
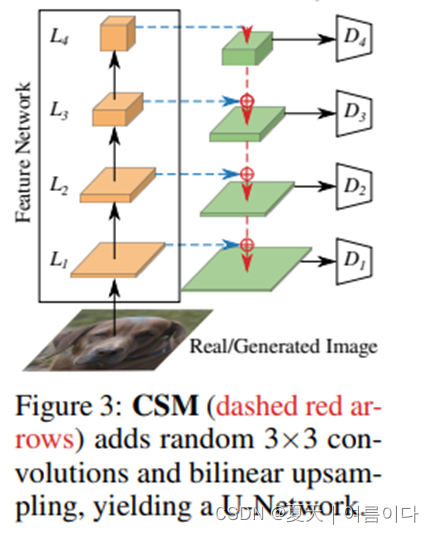
?Cross-Scale Mixing(CSM)
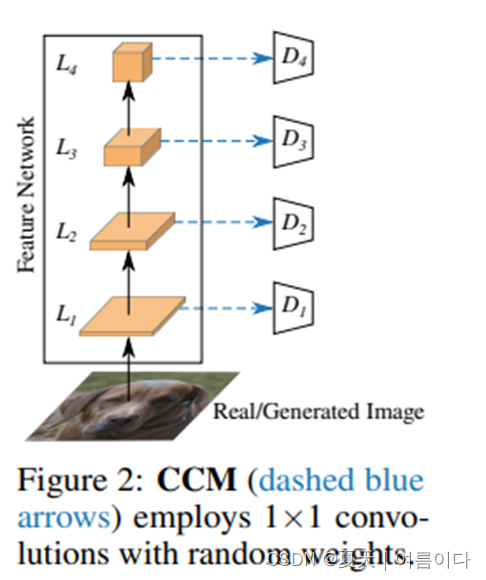 ?
?
生成结果如图
 5.Pix2pix
5.Pix2pix
Pix2pix : Image-to-Image Translation withConditional Adversarial Nets
Paper : ?[1611.07004] Image-to-ImageTranslation with Conditional Adversarial Networks (arxiv.org)
Code : phillipi/pix2pix: Image-to-image translationwith conditional adversarial nets (github.com)
Input Sketch
Output Image

模型结构如图

6.CycleGAN
CycleGAN : Unpaired Image-to-Image Translation using Cycle-Consistent AdversarialNetworks
Paper : 1703.10593.pdf (arxiv.org)
CycleGAN基于GAN的基础

Souse【1】
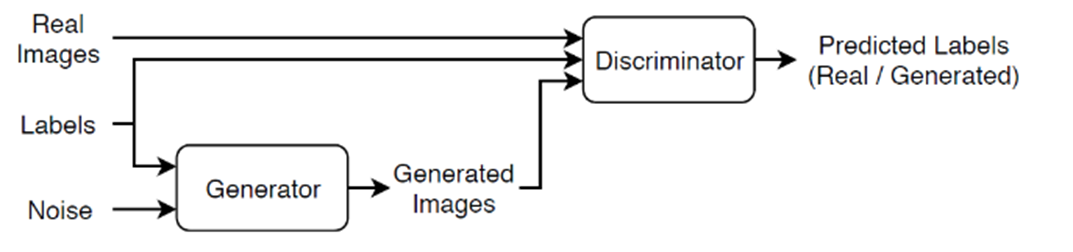
定义以下双输入网络,该网络在给定大小为 100 的随机向量和相应标签的情况下生成图像。

-
使用全连接层,然后进行整形操作,将大小为 100 的随机向量转换为 4×4 x 1024 数组。
-
将分类标签转换为嵌入向量,并将它们重新塑造为 4×4 数组。
-
沿通道维度连接来自两个输入的结果图像。输出是 4 x 4 x 1025 数组。
-
使用一系列具有批量归一化和 ReLU 层的转置卷积层将生成的数组升级到 64 x 64 x 3 数组。
将此网络体系结构定义为层图,并指定以下网络属性。
-
对于分类输入,请使用嵌入维度 50。
-
对于转置卷积层,指定 5 x 5 个滤波器,每层的滤波器数量递减,步幅为 2,并裁剪输出。"same"
-
对于最终的转置卷积层,请指定一个对应于生成图像的三个 RGB 通道的三个 5 x 5 滤波器。
-
在网络的末端,包括一个tanh层。
7.StyleGAN
7.1.StyleGAN
StyleGAN:2019_A Style-BasedGenerator Architecture for Generative Adversarial Networks
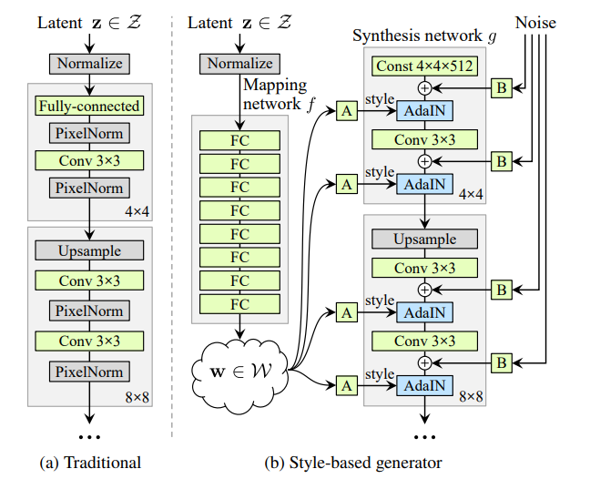
StyleGAN 模型的开发是为了创建一个更易于解释的架构,以便理解图像合成过程的各个方面。作者选择风格迁移任务是因为图像合成过程是可控的,因此他们可以监控潜在空间的变化。通常,输入潜在空间遵循训练数据的概率密度,存在一定程度的纠缠。在这种情况下,纠缠是指改变一个属性无意中改变了另一个属性,例如改变某人的头发颜色也可能改变他们的肤色。与之前的 GAN 不同,StyleGAN 生成器将输入数据嵌入到中间潜在空间中,这会影响网络中变异因素的表示方式。
生成器不是通过第一层接收潜在向量,而是从学习的常数开始。映射网络是一个 8 层 MLP,接收和输出 512 维向量。当得到中间潜在向量后,学习仿射变换然后专门化在合成网络的每个卷积层之后控制自适应实例归一化(AdaIN)操作的样式。

AdaIN 操作分别对输入数据的每个特征图进行标准化,然后根据注入到操作中的相应风格向量对标准化向量进行缩放和偏置。在此模型中,他们通过编辑每个卷积步骤后输出的特征图来编辑图像。
这个风格矢量是什么?StyleGAN 可以通过不同的技术对风格进行编码,即风格混合以及在生成过程中添加像素噪声。在风格混合中,模型使用一个输入图像为生成过程的一部分生成风格向量(编码属性),然后将其随机切换为来自另一输入图像的另一个风格向量。对于每像素噪声,随机噪声在生成过程的各个阶段注入模型中。
为了确保 StyleGAN 为用户提供控制生成图像样式的能力,作者设计了两个指标来确定潜在空间的解开程度。尽管我在上面定义了“纠缠”,但我相信定义解缠进一步巩固了这个概念。解开是指单个样式操作仅影响一个变化因素(一个属性)。他们引入的指标包括:
- 感知路径长度:这是由沿线性插值采样的矢量采样形成的生成图像之间的差异。给定潜在空间内的两个点,沿着源和端点之间的线性插值以均匀的间隔采样向量。求归一化输入潜伏内的球形插值
- 线性可分离性:他们在 CelebA 的所有 40 个属性上训练辅助分类网络,然后根据这些属性对 200K 生成的图像进行分类。然后,他们拟合线性支持向量机来根据潜在空间点预测标签,并按该位置对点进行分类。然后,他们计算条件熵 H(Y|X),其中 X 是 SVM 预测的类别,Y 是由预训练分类器确定的类别。→ 这告诉我们需要多少信息来确定样本的真实类别,因为我们知道样本位于超平面的哪一侧。较低的值表明相应变化因素的潜在空间方向一致。分数越低表明特征越分散。
7.2.2019.12.03_StyleGAN2
Analyzing and Improving the Image Quality of StyleGAN
Paper : 1912.04958.pdf (arxiv.org)
第一个 StyleGAN 模型向公众发布后,其广泛使用导致人们发现了一些奇怪的地方,这些导致生成的图像上出现随机的斑点状伪影。为了解决这个问题,作者重新设计了他们在生成器中使用的特征图归一化技术,修改了他们用来生成高分辨率图像的“渐进增长”技术,并采用了新的正则化来鼓励潜在代码映射中的良好调节到图像。

- 提醒:?StyleGAN 是一种特殊类型的图像生成器,因为它需要潜在代码z�并将其转换为中间潜在代码w�使用映射网络。此后,仿射变换会产生通过自适应实例归一化 (AdaIN) 控制合成网络各层的样式。通过向合成网络提供额外的噪声来促进随机变化 → 这种噪声会导致图像变化/多样性
- 指标提醒
- FID → InceptionV3 分类器的高维特征空间中两个分布的密度差异的度量
- 精度 → 衡量生成的图像与训练数据相似的百分比
- 召回率→可生成的训练数据的百分比
作者提到,上述指标基于分类器网络,该网络已被证明专注于纹理而不是形状,因此未捕获图像质量的某些方面。为了解决这个问题,他们提出了一种与形状的一致性和稳定性相关的感知路径长度(PPL)度量。他们使用 PPL 来规范合成网络,以有利于平滑映射并提高图像质量。
通过回顾之前的 StyleGAN 模型,作者注意到类似于水滴的斑点状伪影。异常开始于642642分辨率,并且存在于所有特征图中,并且在更高的分辨率下变得更强。他们将问题追溯到 AdaIN 操作,该操作分别对每个特征图的均值和方差进行归一化。他们假设生成器通过创建一个主导统计数据的强大的局部尖峰,故意将信号强度信息偷偷地通过实例归一化操作。通过这样做,发生器可以像在其他地方一样有效地缩放信号。这导致生成的图像可以欺骗鉴别器,但最终无法通过“人类”定性测试。当他们取消标准化步骤时,伪影完全消失。
原始 StyleGAN 在样式块内应用偏差和噪声,导致它们的相对影响与当前样式的大小成反比。在 StyleGAN2 中,作者将这些操作移到样式块之外,对标准化数据进行操作。进行此更改后,标准化和调制仅对标准差进行操作。
除了类似水滴的伪影之外,作者还发现了“纹理粘附”的问题。当逐渐增长的生成器似乎对细节有强烈的位置偏好时,就会发生纹理粘连,其中图像的某些属性似乎对图像的某些区域有偏好。当生成器总是生成人的嘴位于图像中心的图像时(如上图所示),可以看到这一点。假设是,在渐进式增长中,每个中间分辨率都充当临时输出分辨率。因此,如果输入损害了平移不变性,这将迫使这些中间层学习非常高频的细节。
为了解决这个问题,他们使用了 MSG-GAN 生成器的修改版本,该生成器使用多个跳过连接来连接生成器和鉴别器的匹配分辨率。在这个新架构中,每个块都会输出一个经过求和和缩放的残差,而不是给定 StyleGAN 分辨率的“潜在输出”。

对于鉴别器,它们向每个分辨率块提供下采样图像。他们还在上采样和下采样操作中使用双线性拟合,并修改设计以使用残差连接。生成器中的跳跃连接极大地提高了 PPL,并且残差鉴别器有利于 FID。
7.3.2021_StyleGAN3
StyleGAN3:2021_Alias-Free Generaive Adversarial Nwtworks
Paper : 2106.12423.pdf (arxiv.org)
作者指出,尽管有多种控制生成过程的方法,但合成过程的基础仍然只有部分了解。在现实世界中,不同尺度的细节往往会分层变换,例如移动头部会导致鼻子移动,进而移动鼻子周围的皮肤毛孔。改变粗略特征的细节会改变高频特征的细节。这是纹理粘贴不影响生成过程的空间不变性的场景。
对于典型的 GAN 生成器,“通过上采样层对粗略、低分辨率的特征进行分层细化,通过卷积进行局部混合,并通过非线性引入新的细节”(Karras、Tero 等人)。当前的 GAN 不会以自然分层方式:粗略特征主要控制精细特征的存在,但不控制它们的精确位置。尽管他们修复了 StyleGAN2 中的伪影,但并没有完全修复头发等更精细特征的空间不变性。
StyleGAN3 的目标是创建一个“展示更自然的变换层次结构的架构,其中每个特征的精确子像素位置完全继承自底层的粗糙特征。”?这仅仅意味着在生成器的早期层中学习的粗略特征将影响某些特征的存在,但不会影响它们在图像中的位置。
当前的 GAN 架构可以通过图像边界、每像素噪声输入和位置编码以及混叠,利用中间层可用的无意位置参考来部分编码空间偏差。
尽管别名在 GAN 文献中很少受到关注,但作者确定了它的两个来源:
- 非理想上采样滤波器导致的微弱余像
- 在卷积过程中逐点应用非线性,例如 ReLU / swish
在我们深入了解 StyleGAN3 的一些细节之前,我需要为 StyleGAN 的上下文定义术语“别名”和“等变”。
混叠→“标准卷积架构由堆叠的操作层组成,这些操作会逐渐缩小图像的尺寸。混叠是下采样可能发生的众所周知的副作用:它导致原始信号的高频分量与其低频分量难以区分。”?(来源)
等方差→“等方差研究输入图像的变换如何通过表示进行编码,不变性是变换无效的特殊情况。”?(来源)
StyleGAN3 的目标之一是重新设计 StyleGAN2 架构以抑制混叠。回想一下,混叠是将空间信息“泄漏”到生成过程中的因素之一,从而强制某些属性的纹理粘附。特征的空间编码在生成器的后期阶段将是有用的信息,因此使其成为高频分量。为了确保它仍然是高频分量,模型需要实现一种方法,将其从生成器早期有用的低频分量中过滤掉。他们指出,以前的上采样技术不足以防止混叠,因此需要设计高质量的滤波器。除了设计高质量滤波器之外,他们还针对逐点非线性(ReLU、
回想一下,等方差意味着输入图像的变化可以通过其向量表示来追踪。为了强制子像素平移的连续等变性,他们描述了 StyleGAN2 生成器所有信号处理方面的全面重新设计。一旦锯齿被抑制,内部表示现在包括坐标系,允许细节正确地附加到底层表面。

7.4.2022.03.05.v2_StyleGAN-XL
Paper : StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets (arxiv.org)
Code : autonomousvision/stylegan-xl: [SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets (github.com)
概述
计算机图形学最近经历了以数据为中心的方法的激增,用于创建逼真和可控的内容。特别是StyleGAN为生成式建模设定了有关图像质量和可控性的新标准。然而,StyleGAN在大型非结构化数据集(如ImageNet)上的性能会严重下降。StyleGAN是为可控性而设计的;因此,先前的研究怀疑其限制性设计不适合不同的数据集。相比之下,作者们发现主要的限制因素是当前的训练策略。遵循最近引入的投影GAN范式,我们利用强大的神经网络先验和渐进式增长策略,在ImageNet上成功训练了最新的StyleGAN3生成器。最终型号 StyleGAN-XL 在大规模图像合成方面树立了新的技术水平,并且是第一个以10242在这样的数据集规模下。证明该模型可以反转和编辑图像,超出人像或特定对象类别的狭窄范围。
StyleGAN 1,2 和 3 在人脸图像生成方面取得了巨大成功,但在更多样化的数据集的图像生成方面却落后了。StyleGAN XL 的目标是实施一种受 Projected GAN 影响的新训练策略,在 ImageNet 等大型非结构化高分辨率数据集上训练 StyleGAN3。
之前的 GAN 模型解决的两个主要问题是:
- 需要结构化数据集来保证生成的图像语义正确
- 需要更大更昂贵的模型来处理大型数据集(规模问题)
什么是预计 GAN?投影 GAN 的工作原理是将生成的样本和真实样本投影到固定的预训练特征空间中。此次修订提高了 StyleGAN3 的训练稳定性、训练时间和数据效率。目标是在 ImageNet 上训练 StyleGAN3 生成器,成功是根据主要通过初始分数 (IS) 衡量的样本质量和通过 FID 衡量的多样性来定义的。
为了在不同的类条件数据集上进行训练,他们实现了 StyleGAN3-T 层(StyleGAN3 的平移等变配置)。作者发现正则化可以改善 FFHQ 或 LSUN 等单模态数据集的结果,但对多模态数据集可能不利,因此,他们在该项目中尽可能避免正则化。
与 StyleGAN 1 和 2 不同,它们禁用样式混合和路径长度正则化,这会导致在复杂数据集上使用时结果不佳和训练不稳定。仅当模型经过充分训练时,正则化才有用。对于鉴别器,他们使用没有梯度惩罚的光谱归一化,并且还对图像应用高斯滤波器,因为它可以防止鉴别器早期关注高频。正如我们在之前的 StyleGAN 模型中看到的那样,早期关注高频可能会导致空间不变性或随机的令人不快的伪影等问题。
StyleGAN 本质上使用大小为 512 的潜在维度。这个维度对于自然图像数据集来说相当高(ImageNet 的维度约为 40)。512 的潜在大小代码是高度冗余的,并且使映射网络在训练开始时的任务更加困难。为了解决这个问题,他们将 StyleGAN 的潜在代码 z 减少到 64,以获得稳定的训练和较低的 FID 值。
? ?
?
根据类信息调节模型对于控制样本类和提高整体性能至关重要。在类条件 StyleGAN 中,one-hot 编码标签被嵌入到 512 维向量中并与 z 连接。对于鉴别器,类别信息被投影到最后一层。对模型的这些编辑使生成器在每个类别中生成相似的样本,从而导致高 IS,但导致召回率低。他们假设在使用 Projected GAN 进行训练时,类嵌入会崩溃。为了解决这个问题,他们通过相关简化了嵌入的优化。他们提取并在空间上汇集 Efficientnet-lite0 的最低分辨率特征,并计算每个 ImageNet 类的平均值。使用该模型使输出嵌入维度保持足够小以维持稳定的训练。
GAN 的逐步增长可以带来更快、更稳定的训练,从而产生更高分辨率的输出。然而,早期 GAN 中提出的原始方法会导致伪影。在这个模型中,他们以以下分辨率开始逐步增长162162使用 11 层,每次分辨率增加,我们就剪掉 2 层并添加 7 层新层。对于最后阶段1024210242,他们只添加 5 层,因为最后两层没有被忽略。每个阶段都会进行训练,直到 FID 停止减少。
之前的研究表明,“无论训练数据、相关目标或网络架构如何,预训练特征网络 F 在用于投影 GAN 训练时在 FID 方面的表现相似。”?(Sauer、Axel、Katja Schwarz 和 Andreas Geiger。)在本文中,他们探索了组合不同特征网络的价值。从标准配置 EfficientNet-lite0 开始,他们添加了第二个特征网络来检查其相关目标和架构的影响。他们提到,将 EfficientNet 与 ViT 结合起来可以显着提高性能,因为这两种架构学习不同的表示。结合两种架构可以产生互补的结果。
该模型的最终贡献是分类器指导的使用,主要是因为它专门针对不同的数据集。分类器指导将类别信息注入扩散模型。除了 EfficientNet 给出的类嵌入之外,它们还将类信息注入到生成器中
- 他们传递生成的图像通过预训练的分类器(DeiT-small)来预测类标签
- 添加交叉熵损失作为生成器损失的附加项,并按常数缩放
这样做会导致初始分数 (IS) 的提高,表明样本质量的提高。分类器指导仅适用于更高分辨率,否则会导致模式崩溃。为了确保模型在使用分类器指导时不会无意中针对 FID 和 IS 进行优化,他们提出了随机 FID (rFID)。他们使用sFID评估图像的空间结构。他们报告说,样本保真度和多样性是通过精确度和召回率指标进行评估的。
StyleGAN-XL 在 FID、sFID、rFID 和 IS 的所有分辨率上均明显优于所有其他 ImageNet 生成模型。由于重新定义了渐进式增长策略,StyleGAN-XL 在所有分辨率上也实现了高度多样性。
7.5.StyleGAN-T
Paper:?StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis (arxiv.org)
之前的 GAN 方法在不同数据集上的稳定训练、强文本对齐以及可控变化与文本对齐权衡方面并不优于扩散模型 (SOTA)。他们提出 StyleGAN-T 的性能优于之前的 SOTA 蒸馏扩散模型和之前的 GAN。
有几件事使测试到图像的合成成为可能:
- 文本提示使用预先训练的大型语言模型进行编码,从而可以根据一般语言理解来条件合成
- 包含图像和标题对的大型数据集
TI 最近的成功是由扩散模型 (DM) 和自回归 (ARM) 模型推动的,这些模型具有吸收训练数据的巨大能力和处理高度多模态数据的能力。GAN 最适用于较小且不太多样化的数据集,这使得它们不如高容量扩散模型那么理想
由于对潜在空间的操纵,GAN 具有更快的推理速度和对合成图像的控制的优点。StyleGAN-T 的优点包括“在文本到图像合成的背景下快速推理速度和平滑的潜在空间插值”
作者选择 StyleGAN-XL 模型作为基准架构,因为它“在类条件 ImageNet 合成中表现强劲”。他们使用的图像质量指标是使用在 LAION-2B 上训练的 ViT-g-14 模型的 FID 和 CLIP 分数。为了将类条件转换为文本条件,他们使用预先训练的 CLIP ViT-L/14 文本编码器嵌入文本提示,并使用嵌入代替类嵌入。
对于生成器,作者放弃了平移等方差的约束,因为成功的 DM 和 ARM 不需要等方差。他们“放弃等方差并切换到合成层的 StyleGAN2 主干,包括输出跳跃连接和空间噪声输入,以促进低级细节的随机变化”(Sauer、Axel 等人)
StyleGAN 的基本配置意味着“生成器深度的显着增加会导致训练中的早期模式崩溃”。为了解决这个问题,他们“使一半的卷积层残差并通过 GroupNorm 包裹它们”以进行归一化,并通过 LayerScale 来缩放其贡献。这使得模型能够逐渐融入卷积层的贡献并稳定早期的训练迭代。
在基于样式的架构中,所有这些变化都必须由每层样式来实现。这使得文本嵌入影响合成的空间很小。
该模型 StyleGAN-T 在 64x64 分辨率上的零样本 FID 分数比论文中包含的许多扩散和自回归模型好得多。其中一些包括 Imagen、DALL-E (1&2) 和 GLIDE。然而,它在 256x256 分辨率图像上的性能比大多数 DM 和 ARM 差。
总结Summary
基于GAN的缺点
-
没有用户控制能力:在传统的GAN里,随机输入一个噪声,随机输出一幅图像。无法根据用户的要求,输出用户所需要的图像。
-
低分辨率和低质量的图
进而产生了下述三种优化后的网络:
-
?pix2pix:有条件的使用户输入,使用成对的数据进行训练
-
CycleGAN:使用不成对的数据进行训练
-
pix2pixHD:生成分辨率更高,质量更高的图像。?
对于GAN系列模型主要差别为:
- DCGAN:在生成器和判别器中引入了卷积结构(原始GAN采用的是简单的MLP)
- CGAN:在生成器和判别器中引入了条件变量,使用额外信息对模型增加条件,使得生成器能够朝着规定方向进行生成
- WGAN:修改了原始GAN的目标函数,用Wasserstein距离替代JS散度来作为两个分布之间的距离度量
参考文献
【1】Train Conditional Generative Adversarial Network (CGAN) - MATLAB & Simulink - MathWorks?
【2】Generative Adversarial Networks for beginners – O’Reilly (oreilly.com)
【3】Generative Adversarial Networks (cpang4.github.io)
【4】What is a Generative Adversarial Network (GAN)? | Definition from TechTarget?
【5】The Evolution of StyleGAN: Introduction
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!