IO零拷贝
在介绍零拷贝之前我们先看看传统的 Java 网络 IO 编程是怎样的。
下面代码展示了一个典型的 Java 网络程序。
File file = new File("index.jsp");
RandomAccessFile rdf = new RandomAccessFile(file, "rw");
byte[] arr = new byte[(int) file.length()];
rdf.read(arr);
Socket socket = new ServerSocket(8080).accept();
socket.getOutputStream().write(arr);
程序中调用 RandomAccessFile 的 read 方法将 index.jsp 的内容读取到字节数组中。然后调用 write 方法将字节数组中的数据写入到 Socket 对应的输出流中发送给客户端。那么 Java 应用程序中的 read、write 方法对应到 OS 底层是怎样的呢。下图展示了这个过程。
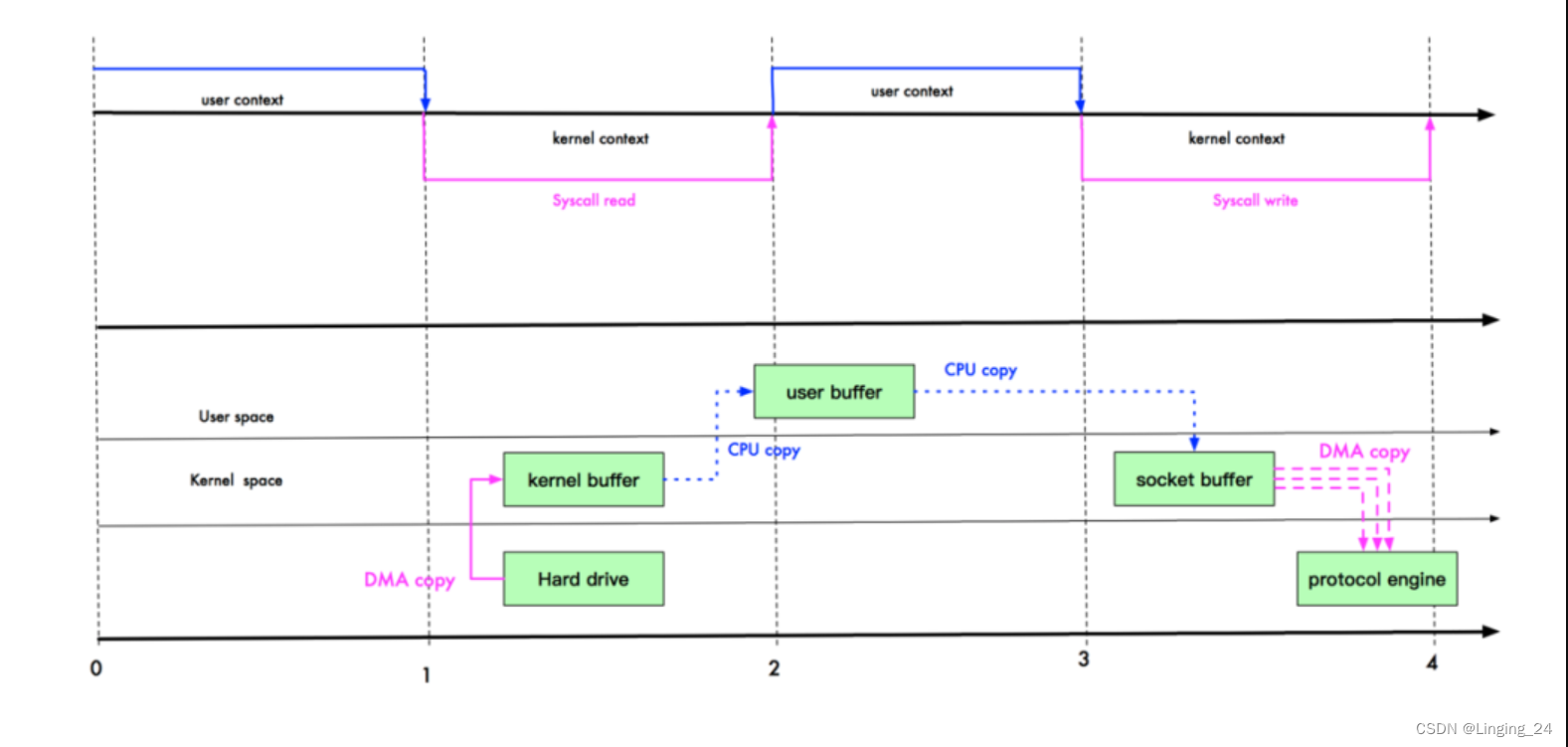
图中上半部分记录了用户态和内核态的上下文切换。下半部分展示了数据的复制过程。上述 Java 代码对应的操作系统底层步骤:
-
read 方法触发操作系统从用户态到切换到内核态。同时通过 DMA 的方式从磁盘读取文件到内核缓冲区。DMA(Direct Memory Access)是 l/O 设备与主存之间由硬件组成的直接数据通路。即不需要 CPU 拷贝数据到内存,而是直接由 DMA 引擎传输数据到内存。
-
紧接着发生第二次数据拷贝,即从内核缓冲区拷贝到用户缓冲区,同时发生一次内核态到用户态的上下文切换。
-
调用 write 方法时,触发第三次数据拷贝,即从用户缓冲区拷贝到 Socket 缓冲区。同时发生一次用户态到内核态的上下文切换。
-
最后数据从 Socket 缓冲区异步拷贝到网络协议引擎,这一步采用的是 DMA 方式。同时没有发生上下文切换。
-
write 方法返回时,触发了最后一次内核态到用户态的切换。
由此可见,复制的操作太频繁,共有 2 次 DMA 拷贝、2 次 CPU 拷贝、4 次上下文切换。能否优化呢?
这就要介绍称之为"零拷贝"的技术。首先声明,零拷贝技术依赖底层 OS 内核提供的支持。Linux 中提供的这类支持有 mmap(),sendfile() 以及 splice() 系统调用。说白了就是减少数据在操作系统内核的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。
mmap
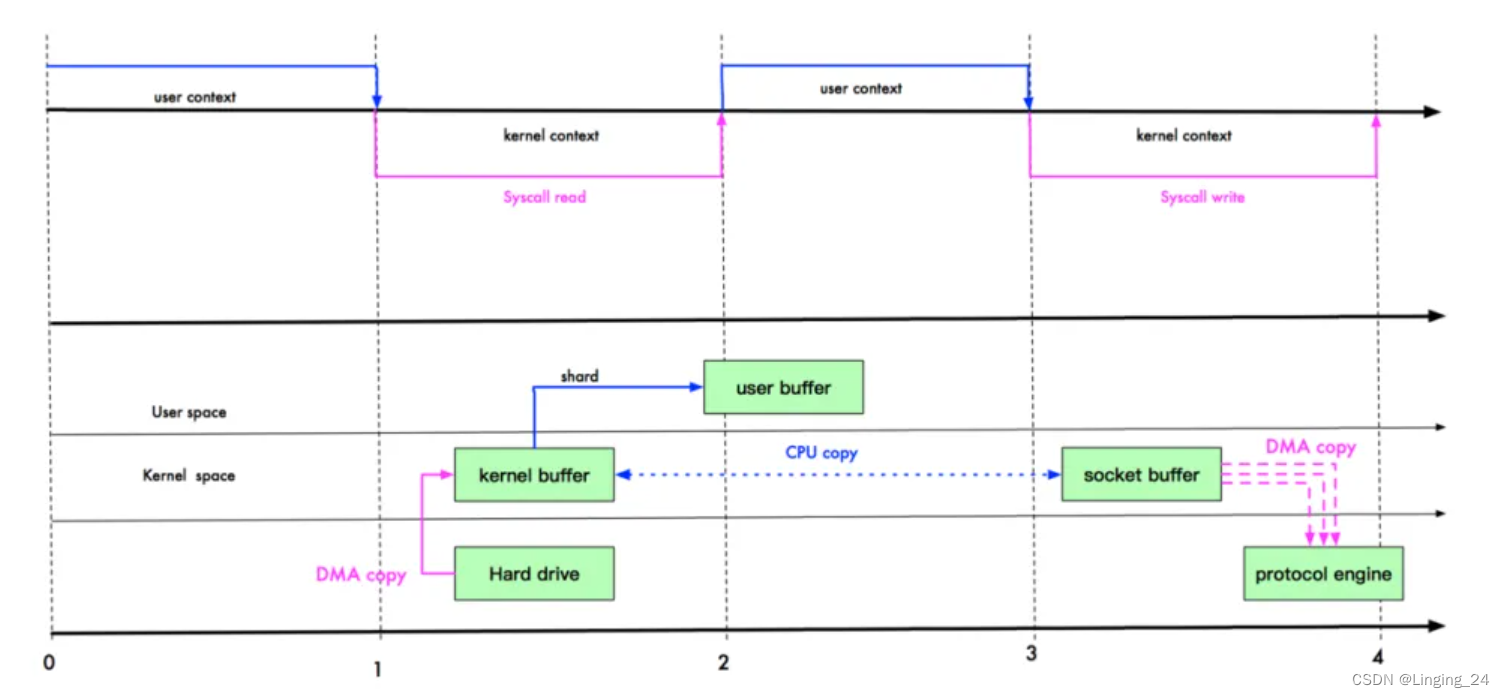
mmap 通过内存映射,将文件通过 DMA 的方式映射到内核缓冲区。操作系统会把这段内核缓冲区与应用程序(用户空间)共享。这样,在进行网络传输时,就能减少内核空间到用户空间的拷贝次数。此时输出数据时只要从内核缓冲区拷贝到 Socket 缓冲区即可。可见减少了一次 CPU 拷贝,但是上下文切换次数并没有减少。整个过程共 2 次 DMA 拷贝,1 次 CPU 拷贝,4 次上下文切换。示意图如下。
sendFile
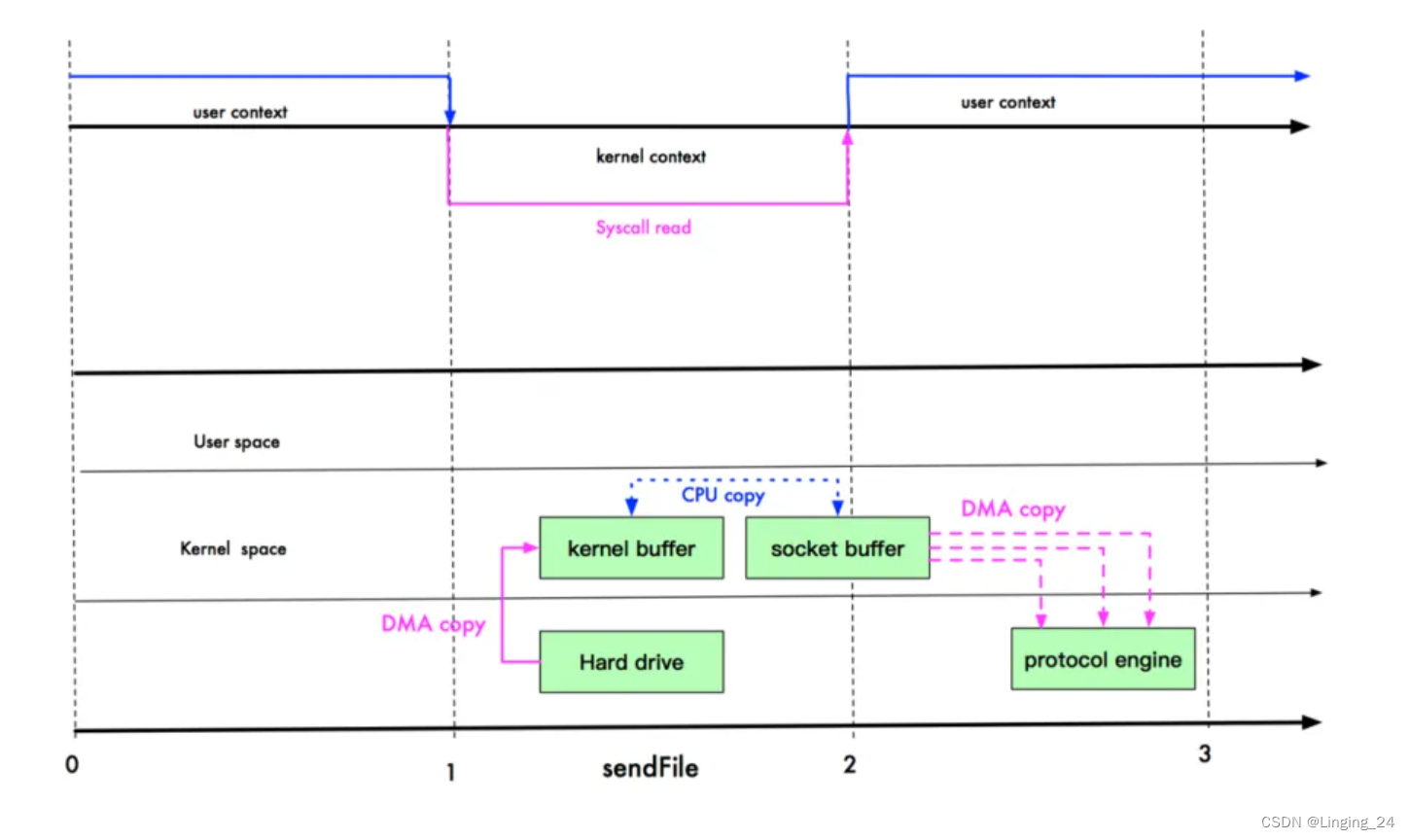
Linux 2.1 开始提供了 sendFile 函数,其基本原理是:数据根本不经过用户态,直接从 Kernel Buffer 进入到 Socket Buffer,并且由于和用户态完全无关,这就避免了一次上下文切换。下图展示了整个过程。磁盘中的数据通过 DMA 引擎从复制到内核缓冲区。调用 write 方法时从内核缓冲区拷贝到 Socket 缓冲区。由于在同一个空间,因此没有发生上下文切换。最后由 Socket 缓冲区拷贝到协议引擎。整个过程共发生了 2 次 DMA 拷贝,1 次 CPU 拷贝,3 次上下文切换。
在 Linux 2.4 版本中,进一步做了优化。从 Kernel Buffer 拷贝到 Socket Buffer 的操作也省了,直接拷贝到协议栈,再次减少了 CPU 数据拷贝。下图展示了整个流程。本地文件 index.jsp 要传输到网络中,只需 2 次拷贝。第一次是 DMA 引擎从文件拷贝到内核缓冲区;第二次是从内核缓冲区将数据拷贝到网络协议栈;内核缓存区只会拷贝一些元信息,比如 offset 和 length 信息到 SocketBuffer,基本无消耗。
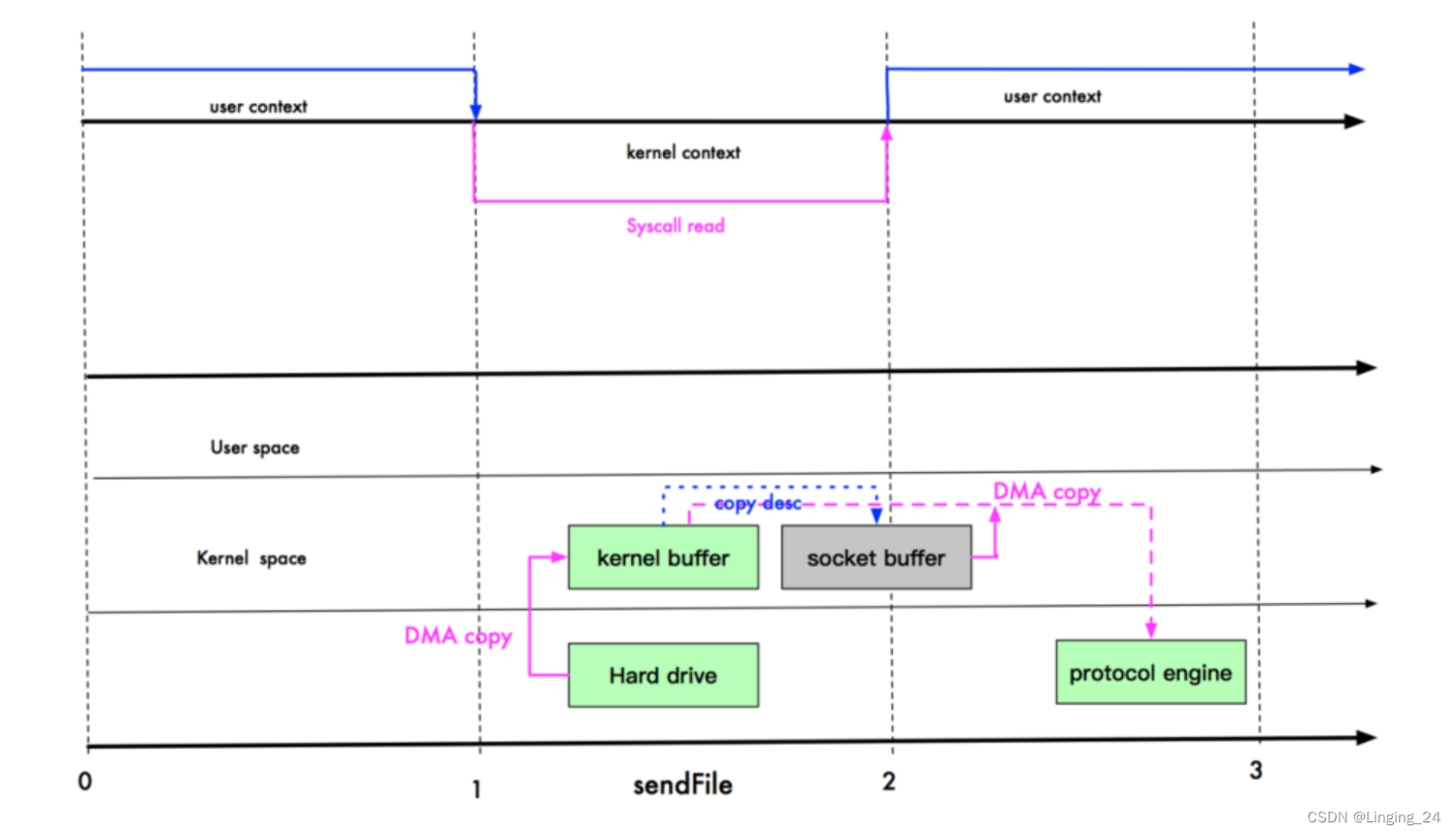
综上所述,最后一种方式发生了 2 次 DMA 拷贝、0 次 CPU 拷贝、3 次上下文切换。这就是所谓的“零拷贝”实现。
总结:
因此零拷贝通常是站在操作系统的角度看,即整个过程中,内核缓冲区之间是没有重复数据的。同时伴随着更少的上下文切换。这就带来了 IO 性能质的提升!
实际开发中,mmap 和 sendFile 都有应用,可以认为是“零拷贝”的两种实现方式。它们都有各自的适用场景。mmap 更适合少量数据读写,sendFile 适合大文件传输。sendFile 可以利用 DMA 方式将内核缓冲区将数据拷贝到网络协议栈,减少 CPU 拷贝,而 mmap 则不能(必须从内核拷贝到 Socket 缓冲区)。
案例:
RocketMQ 在 CommitLog 和 CosumerQueue 的实现中都采用了 mmap。而 Kafka 的零拷贝实现则使用了 sendFile。
RocketMQ 和 Kafka 高性能的原因之一便是顺序写入和近似顺序读取 + 零拷贝。
引用:https://zhuanlan.zhihu.com/p/543661648
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!