使用docker镜像快速构建TVM
2024-01-07 17:50:49
TVM docekr编译
使用云镜像
- 下载docker镜像
如果对docker指令不熟悉可以查阅: docker cli命令行 AP I
docker pull tlcpack/ci-cpu:20230604-060130-0af9ff90e
- 运行container
docker run --name 2306_tvm_cpu -it -v /Users/chendongsheng/github/tvm:/root/workspace/tvm 374265cb4bb3
- 如果docker desttop有权限问题,执行
# docker的权限出现问题后,请这么处理。
sudo chown -R $(whoami) ~/.docker
- 构建TVM
在tvm的代码跟路径,创建build文件夹,将下面内容存在build文件夹内一个名为:config.cmake的文件中。具体每一项配置的含义可以参考: TVM源码编译教程
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#--------------------------------------------------------------------
# Template custom cmake configuration for compiling
#
# This file is used to override the build options in build.
# If you want to change the configuration, please use the following
# steps. Assume you are on the root directory. First copy the this
# file so that any local changes will be ignored by git
#
# $ mkdir build
# $ cp cmake/config.cmake build
#
# Next modify the according entries, and then compile by
#
# $ cd build
# $ cmake ..
#
# Then build in parallel with 8 threads
#
# $ make -j8
#--------------------------------------------------------------------
#---------------------------------------------
# Backend runtimes.
#---------------------------------------------
# Whether enable CUDA during compile,
#
# Possible values:
# - ON: enable CUDA with cmake's auto search
# - OFF: disable CUDA
# - /path/to/cuda: use specific path to cuda toolkit
set(USE_CUDA OFF)
# Whether to enable NCCL support:
# - ON: enable NCCL with cmake's auto search
# - OFF: disable NCCL
# - /path/to/nccl: use specific path to nccl
set(USE_NCCL OFF)
# Whether enable ROCM runtime
#
# Possible values:
# - ON: enable ROCM with cmake's auto search
# - OFF: disable ROCM
# - /path/to/rocm: use specific path to rocm
set(USE_ROCM OFF)
# Whether to enable RCCL support:
# - ON: enable RCCL with cmake's auto search
# - OFF: disable RCCL
# - /path/to/rccl: use specific path to rccl
set(USE_RCCL OFF)
# Whether enable SDAccel runtime
set(USE_SDACCEL OFF)
# Whether enable Intel FPGA SDK for OpenCL (AOCL) runtime
set(USE_AOCL OFF)
# Whether enable OpenCL runtime
#
# Possible values:
# - ON: enable OpenCL with OpenCL wrapper to remove dependency during build
# time and trigger dynamic search and loading of OpenCL in runtime
# - OFF: disable OpenCL
# - /path/to/opencl-sdk: use specific path to opencl-sdk
set(USE_OPENCL OFF)
# Wheather to allow OPENCL cl_mem access to host
# cl_mem will be allocated with CL_MEM_ALLOC_HOST_PTR
# OpenCLWorkspace->GetHostPtr API returns the host accessible pointer
set(USE_OPENCL_ENABLE_HOST_PTR OFF)
# Whether enable Metal runtime
set(USE_METAL OFF)
# Whether enable Vulkan runtime
#
# Possible values:
# - ON: enable Vulkan with cmake's auto search
# - OFF: disable vulkan
# - /path/to/vulkan-sdk: use specific path to vulkan-sdk
set(USE_VULKAN OFF)
# Whether to use spirv-tools.and SPIRV-Headers from Khronos github or gitlab.
#
# Possible values:
# - OFF: not to use
# - /path/to/install: path to your khronis spirv-tools and SPIRV-Headers installation directory
#
set(USE_KHRONOS_SPIRV OFF)
# whether enable SPIRV_KHR_DOT_PRODUCT
set(USE_SPIRV_KHR_INTEGER_DOT_PRODUCT OFF)
# Whether enable OpenGL runtime
set(USE_OPENGL OFF)
# Whether enable MicroTVM runtime
set(USE_MICRO OFF)
# Whether enable RPC runtime
set(USE_RPC ON)
# Whether to build the C++ RPC server binary
set(USE_CPP_RPC OFF)
# Whether to build the C++ native runtime tool binary
set(USE_CPP_RTVM OFF)
# Whether to build the iOS RPC server application
set(USE_IOS_RPC OFF)
# Whether embed stackvm into the runtime
set(USE_STACKVM_RUNTIME OFF)
# Whether enable tiny embedded graph executor.
set(USE_GRAPH_EXECUTOR ON)
# Whether enable tiny graph executor with CUDA Graph
set(USE_GRAPH_EXECUTOR_CUDA_GRAPH OFF)
# Whether enable pipeline executor.
set(USE_PIPELINE_EXECUTOR OFF)
# Whether to enable the profiler for the graph executor and vm
set(USE_PROFILER ON)
# Whether enable microTVM standalone runtime
set(USE_MICRO_STANDALONE_RUNTIME OFF)
# Whether build with LLVM support
# Requires LLVM version >= 4.0
#
# Possible values:
# - ON: enable llvm with cmake's find search
# - OFF: disable llvm, note this will disable CPU codegen
# which is needed for most cases
# - /path/to/llvm-config: enable specific LLVM when multiple llvm-dev is available.
set(USE_LLVM ON)
# Whether use MLIR to help analyze, requires USE_LLVM is enabled
# Possible values: ON/OFF
set(USE_MLIR OFF)
#---------------------------------------------
# Contrib libraries
#---------------------------------------------
# Whether to build with BYODT software emulated posit custom datatype
#
# Possible values:
# - ON: enable BYODT posit, requires setting UNIVERSAL_PATH
# - OFF: disable BYODT posit
#
# set(UNIVERSAL_PATH /path/to/stillwater-universal) for ON
set(USE_BYODT_POSIT OFF)
# Whether use BLAS, choices: openblas, atlas, apple
set(USE_BLAS none)
# Whether to use MKL
# Possible values:
# - ON: Enable MKL
# - /path/to/mkl: mkl root path
# - OFF: Disable MKL
# set(USE_MKL /opt/intel/mkl) for UNIX
# set(USE_MKL ../IntelSWTools/compilers_and_libraries_2018/windows/mkl) for WIN32
# set(USE_MKL <path to venv or site-packages directory>) if using `pip install mkl`
set(USE_MKL OFF)
# Whether use DNNL library, aka Intel OneDNN: https://oneapi-src.github.io/oneDNN
#
# Now matmul/dense/conv2d supported by -libs=dnnl,
# and more OP patterns supported in DNNL codegen(json runtime)
#
# choices:
# - ON: Enable DNNL in BYOC and -libs=dnnl, by default using json runtime in DNNL codegen
# - JSON: same as above.
# - C_SRC: use c source runtime in DNNL codegen
# - path/to/oneDNN:oneDNN root path
# - OFF: Disable DNNL
set(USE_DNNL OFF)
# Whether use Intel AMX instructions.
set(USE_AMX OFF)
# Whether use OpenMP thread pool, choices: gnu, intel
# Note: "gnu" uses gomp library, "intel" uses iomp5 library
set(USE_OPENMP none)
# Whether use contrib.random in runtime
set(USE_RANDOM ON)
# Whether use NNPack
set(USE_NNPACK OFF)
# Possible values:
# - ON: enable tflite with cmake's find search
# - OFF: disable tflite
# - /path/to/libtensorflow-lite.a: use specific path to tensorflow lite library
set(USE_TFLITE OFF)
# /path/to/tensorflow: tensorflow root path when use tflite library
set(USE_TENSORFLOW_PATH none)
# Required for full builds with TFLite. Not needed for runtime with TFLite.
# /path/to/flatbuffers: flatbuffers root path when using tflite library
set(USE_FLATBUFFERS_PATH none)
# Possible values:
# - OFF: disable tflite support for edgetpu
# - /path/to/edgetpu: use specific path to edgetpu library
set(USE_EDGETPU OFF)
# Possible values:
# - ON: enable cuDNN with cmake's auto search in CUDA directory
# - OFF: disable cuDNN
# - /path/to/cudnn: use specific path to cuDNN path
set(USE_CUDNN OFF)
# Whether use cuBLAS
set(USE_CUBLAS OFF)
# Whether use MIOpen
set(USE_MIOPEN OFF)
# Whether use MPS
set(USE_MPS OFF)
# Whether use rocBlas
set(USE_ROCBLAS OFF)
# Whether use contrib sort
set(USE_SORT ON)
# Whether to use Arm Compute Library (ACL) codegen
# We provide 2 separate flags since we cannot build the ACL runtime on x86.
# This is useful for cases where you want to cross-compile a relay graph
# on x86 then run on AArch.
#
# An example of how to use this can be found here: docs/deploy/arm_compute_lib.rst.
#
# USE_ARM_COMPUTE_LIB - Support for compiling a relay graph offloading supported
# operators to Arm Compute Library. OFF/ON
# USE_ARM_COMPUTE_LIB_GRAPH_EXECUTOR - Run Arm Compute Library annotated functions via the ACL
# runtime. OFF/ON/"path/to/ACL"
set(USE_ARM_COMPUTE_LIB OFF)
set(USE_ARM_COMPUTE_LIB_GRAPH_EXECUTOR OFF)
# Whether to build with Arm Ethos-N support
# Possible values:
# - OFF: disable Arm Ethos-N support
# - path/to/arm-ethos-N-stack: use a specific version of the
# Ethos-N driver stack
set(USE_ETHOSN OFF)
# If USE_ETHOSN is enabled, use ETHOSN_HW (ON) if Ethos-N hardware is available on this machine
# otherwise use ETHOSN_HW (OFF) to use the software test infrastructure
set(USE_ETHOSN_HW OFF)
# Whether to build with Arm(R) Ethos(TM)-U NPU codegen support
set(USE_ETHOSU OFF)
# Whether to build with CMSIS-NN external library support.
# See https://github.com/ARM-software/CMSIS_5
set(USE_CMSISNN OFF)
# Whether to build with TensorRT codegen or runtime
# Examples are available here: docs/deploy/tensorrt.rst.
#
# USE_TENSORRT_CODEGEN - Support for compiling a relay graph where supported operators are
# offloaded to TensorRT. OFF/ON
# USE_TENSORRT_RUNTIME - Support for running TensorRT compiled modules, requires presense of
# TensorRT library. OFF/ON/"path/to/TensorRT"
set(USE_TENSORRT_CODEGEN OFF)
set(USE_TENSORRT_RUNTIME OFF)
# Whether use VITIS-AI codegen
set(USE_VITIS_AI OFF)
# Build Verilator codegen and runtime
set(USE_VERILATOR OFF)
#Whether to use CLML codegen
set(USE_CLML OFF)
# USE_CLML_GRAPH_EXECUTOR - CLML SDK PATH or ON or OFF
set(USE_CLML_GRAPH_EXECUTOR OFF)
# Build ANTLR parser for Relay text format
# Possible values:
# - ON: enable ANTLR by searching default locations (cmake find_program for antlr4 and /usr/local for jar)
# - OFF: disable ANTLR
# - /path/to/antlr-*-complete.jar: path to specific ANTLR jar file
set(USE_ANTLR OFF)
# Whether use Relay debug mode
set(USE_RELAY_DEBUG ON)
# Whether to build fast VTA simulator driver
set(USE_VTA_FSIM OFF)
# Whether to build cycle-accurate VTA simulator driver
set(USE_VTA_TSIM OFF)
# Whether to build VTA FPGA driver (device side only)
set(USE_VTA_FPGA OFF)
# Whether use Thrust
set(USE_THRUST OFF)
# Whether use cuRAND
set(USE_CURAND OFF)
# Whether to build the TensorFlow TVMDSOOp module
set(USE_TF_TVMDSOOP OFF)
# Whether to build the PyTorch custom class module
set(USE_PT_TVMDSOOP OFF)
# Whether to use STL's std::unordered_map or TVM's POD compatible Map
set(USE_FALLBACK_STL_MAP OFF)
# Whether to enable Hexagon support
set(USE_HEXAGON OFF)
set(USE_HEXAGON_SDK /path/to/sdk)
# Whether to build the minimal support android rpc server for Hexagon
set(USE_HEXAGON_RPC OFF)
# Hexagon architecture to target when compiling TVM itself (not the target for
# compiling _by_ TVM). This applies to components like the TVM runtime, but is
# also used to select correct include/library paths from the Hexagon SDK when
# building runtime for Android.
# Valid values are v65, v66, v68, v69, v73.
set(USE_HEXAGON_ARCH "v68")
# Whether to use QHL library
set(USE_HEXAGON_QHL OFF)
# Whether to use ONNX codegen
set(USE_TARGET_ONNX OFF)
# Whether enable BNNS runtime
set(USE_BNNS OFF)
# Whether to build static libtvm_runtime.a, the default is to build the dynamic
# version: libtvm_runtime.so.
#
# The static runtime library needs to be linked into executables with the linker
# option --whole-archive (or its equivalent). The reason is that the TVM registry
# mechanism relies on global constructors being executed at program startup.
# Global constructors alone are not sufficient for the linker to consider a
# library member to be used, and some of such library members (object files) may
# not be included in the final executable. This would make the corresponding
# runtime functions to be unavailable to the program.
set(BUILD_STATIC_RUNTIME OFF)
# Caches the build so that building is faster when switching between branches.
# If you switch branches, build and then encounter a linking error, you may
# need to regenerate the build tree through "make .." (the cache will
# still provide significant speedups).
# Possible values:
# - AUTO: search for path to ccache, disable if not found.
# - ON: enable ccache by searching for the path to ccache, report an error if not found
# - OFF: disable ccache
# - /path/to/ccache: use specific path to ccache
set(USE_CCACHE AUTO)
# Whether to use libbacktrace to supply linenumbers on stack traces.
# Possible values:
# - ON: Find libbacktrace from system paths. Report an error if not found.
# - OFF: Don't use libbacktrace.
# - /path/to/libbacktrace: Looking for the libbacktrace header and static lib from a user-provided path. Report error if not found.
# - COMPILE: Build and link to libbacktrace from 3rdparty/libbacktrace.
# - AUTO:
# - Find libbacktrace from system paths.
# - If not found, fallback to COMPILE on Linux or MacOS, fallback to OFF on Windows or other platforms.
set(USE_LIBBACKTRACE AUTO)
# Whether to install a signal handler to print a backtrace on segfault.
# Need to have USE_LIBBACKTRACE enabled.
set(BACKTRACE_ON_SEGFAULT OFF)
# Whether to enable PAPI support in profiling. PAPI provides access to hardware
# counters while profiling.
# Possible values:
# - ON: enable PAPI support. Will search PKG_CONFIG_PATH for a papi.pc
# - OFF: disable PAPI support.
# - /path/to/folder/containing/: Path to folder containing papi.pc.
set(USE_PAPI OFF)
# Whether to use GoogleTest for C++ unit tests. When enabled, the generated
# build file (e.g. Makefile) will have a target "cpptest".
# Possible values:
# - ON: enable GoogleTest. The package `GTest` will be required for cmake
# to succeed.
# - OFF: disable GoogleTest.
# - AUTO: cmake will attempt to find the GTest package, if found GTest will
# be enabled, otherwise it will be disabled.
# Note that cmake will use `find_package` to find GTest. Please use cmake's
# predefined variables to specify the path to the GTest package if needed.
set(USE_GTEST AUTO)
# Enable using CUTLASS as a BYOC backend
# Need to have USE_CUDA=ON
set(USE_CUTLASS OFF)
# Enable to show a summary of TVM options
set(SUMMARIZE OFF)
# Whether to use LibTorch as backend
# To enable pass the path to the root libtorch (or PyTorch) directory
# OFF or /path/to/torch/
set(USE_LIBTORCH OFF)
# Whether to use the Universal Modular Accelerator Interface
set(USE_UMA OFF)
# Set custom Alloc Alignment for device allocated memory ndarray points to
set(USE_KALLOC_ALIGNMENT 64)
- 构建指令
# 配置
cmake .. -G Ninja
# 编译
ninja
# 安装
ninja install
- 设置python环境
# add TVM path
export TVM_HOME=/root/workspace/tvm/
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
- 测试python环境
root@3a017d3a3d46:~/workspace/tvm/build# python
Python 3.8.16 (default, Dec 7 2022, 01:12:06)
[GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tvm
>>> print(tvm.__version__)
0.15.dev0
>>>
使用docker进行本地构建
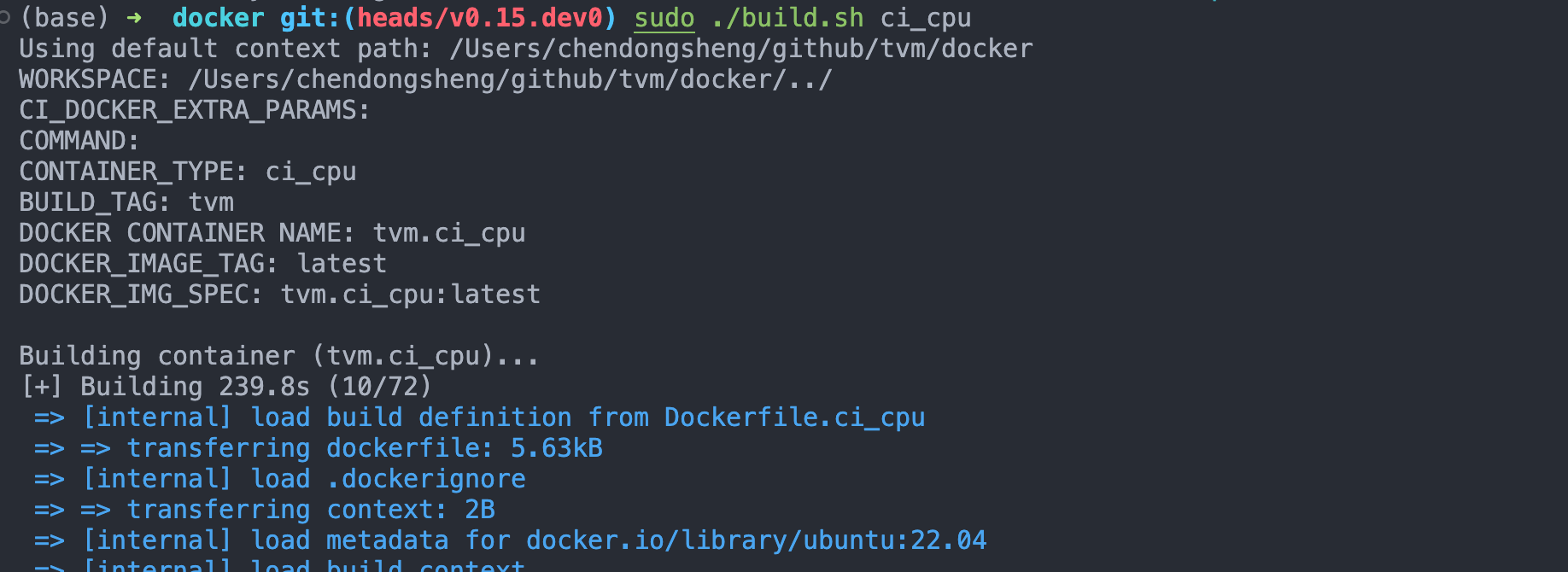
** 本地构建CPU上的镜像,我一直在失败,我放弃了 **
下面是记录本地构建的过程和报错,供参考:
# 在tvm的跟路径下的docker文件夹内,存放着构建镜像的dockerfile和帮助构建的脚本
sudo ./docker/build.sh ci_cpu
# 创建镜像
docker run --name 2306_tvm_cpu -it -v /Users/chendongsheng/github/tvm:/root/workspace/tvm 374265cb4bb3
# 设置工作空间:-w /path/to/dir/
- 报错记录

文章来源:https://blog.csdn.net/sexyluna/article/details/135438181
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!