读书笔记--构建数据湖仓阅读有感
? ? ? 企业为什么要开展数据治理?为什么在数据治理过程中提出数据湖仓构建?数据湖如果没有分析基础设施的建设,就会形成数据沼泽或臭水沟,因为没有人用,也不知道数据之间的关系。我们知道数据因业务开展而产生,后续数据收集汇总后,数据需要用来分析和使用,进而形成分析服务,用于支持企业的战略决策和价值挖掘,用于商业决策,而分析数据需要不同类型数据的融合关联,以及提供数据挖掘的分析基础设施环境,否则数据就还是以原始数据方式存放,没有合适的信息和工具供数据科学家或用户便捷使用,因此提出了数据湖仓,他综合了数据仓库的数据结构和数据管理特性,同时借鉴了数据湖的低成本存储和支持多种类型数据的组织存储特性等。
一、四个术语比较
1.数据库:按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。(来自百度百科)
2.数据仓库:用于将分散在各APP的数据复制一份到另一个独立物理位置进行存放数据的仓库,主要包括元数据、数据模型、数据血缘、汇总、KPI等分析基础设施,供数据科学家或终端用户分析预测使用。
3.数据湖:用于存放所有类型原始数据集合的场所,确保数据的原汁原味。
4.数据湖仓:是数据仓库+数据湖的变种,但支持结构化数据、文本数据和非结构化数据的管理,支持数据结构和数据管理特性,同时支持数据湖的低成本存储、开放性和标准化访问集成。
开放性对比
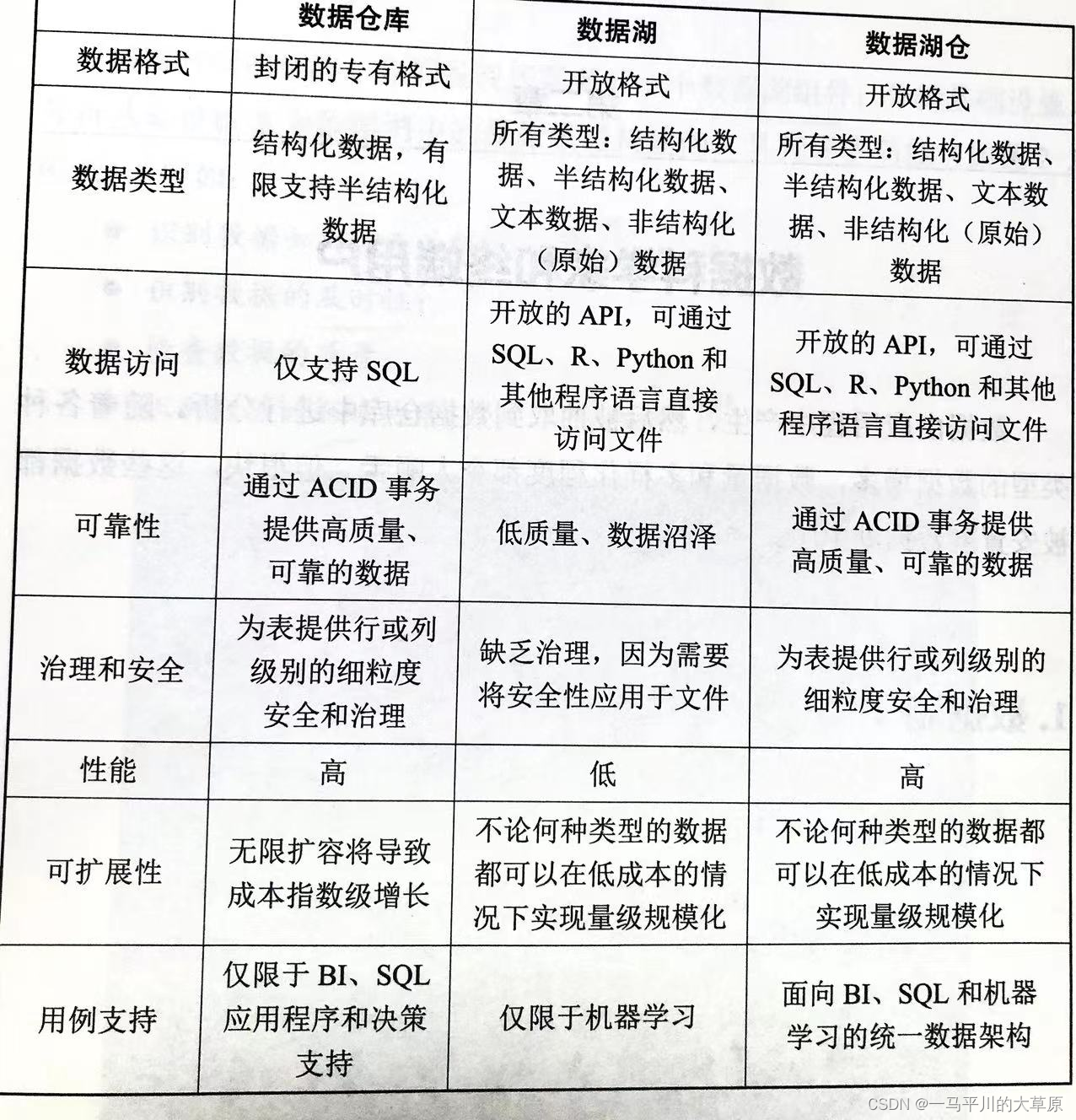
二、数据湖仓支持的数据类型有哪些
1.结构化数据:组织执行日常业务活动形成的基于事务处理的数据。
2.文本数据:公司内部函件文件、电子邮件、会议纪要、对话生成的数据等。
3.非结构化数据:物联网设备生成的语音、图像视频数据和模拟实验形成的模拟数据等。
三、数据湖仓的整体架构
数据湖仓是建立在数据湖基础上,解决了数据在哪里、数据关联性、数据是否最新、数据是否准确等挑战问题而设计形成的。架构图如下
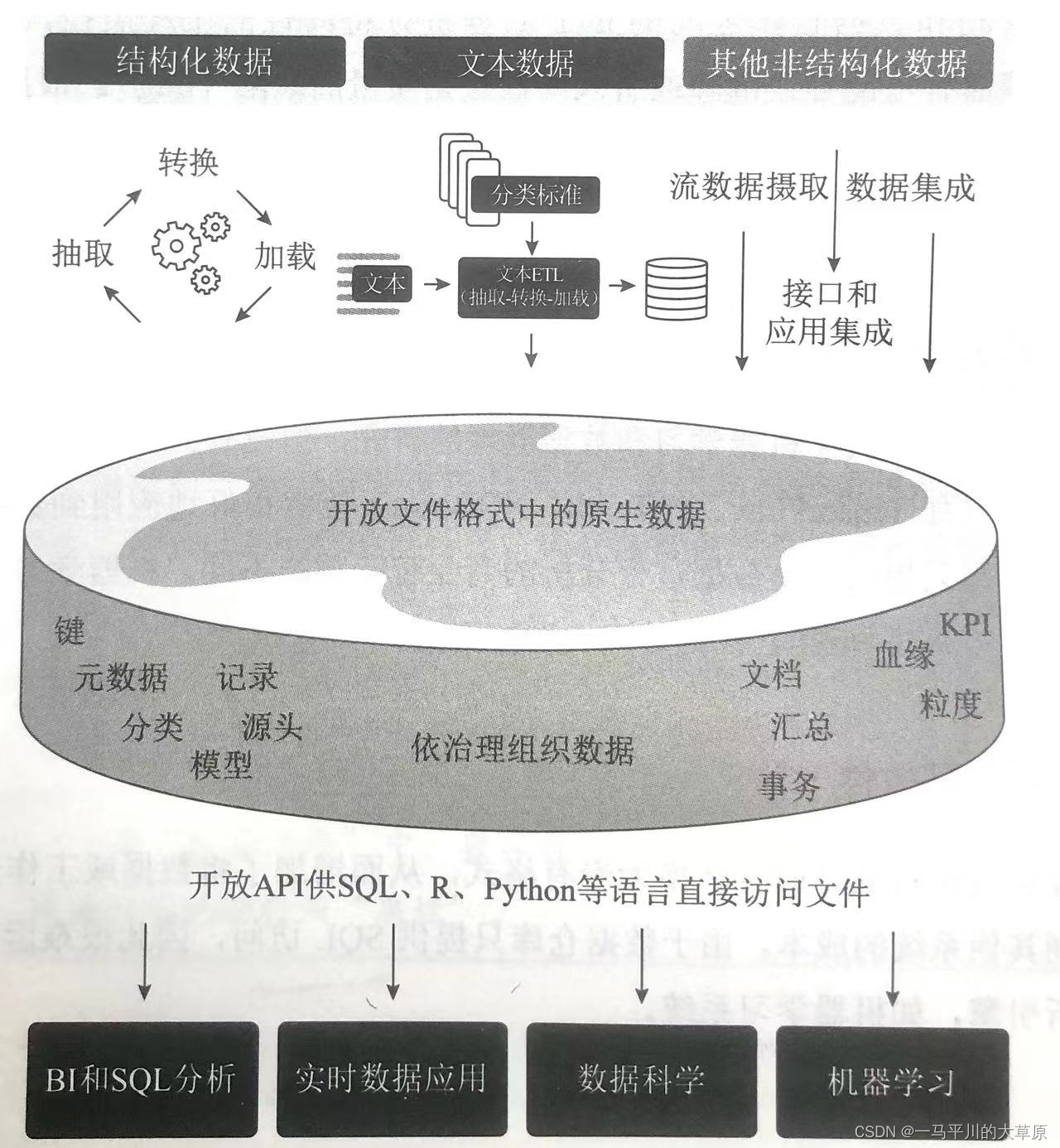
中间部分就是分析基础设施,分析基础设施包括提供卡片目录的元数据、数据模型,以及分类标准、KPI、数据血缘(数据谱系)、汇总数据、ETL、文本ETL、数据体量、数据粒度、键、粒度、数据源等,同时包括用于分析的工具方法,如SQL/R/Python语言环境、BI工具、实时App、数据科学与统计分析和机器学习工具等。
文本ETL:context情景分析,同义解析,分类辨析,近义词辨析,客群解析,关键词解析等
分类标准用于将原始文本转换为数据库,比如按照汽车品牌、树木类型,各大洲,职业类型等。
分析基础设施的受众群体主要有数据科学家和终端用户。
1.数据开发工程师和数据科学家:主要负责寻找组织内数据新模式发现、趋势分析、统计分析、隐藏在底层的价值挖掘等。
2.终端用户:主要通过分析基础设施实现快速可视化呈现和明确报表计算,以及低粒度的数据统计分析等。
四、数据湖仓支持开源开放
什么是开源开放呢?
开源包括代码开放、社区开放和创造力开放。
开放包括开源软件、开放API、开放文件格式和开放工具。
数据湖仓遵循的原则就是开源开放的湖仓环境,支持各种开放语言和开源库,非结构化数据支持Apache Parquet等标准的开放文件格式,同时提供超越SQL的支持python和R语言处理数据的数据框架API,具体组件架构见下图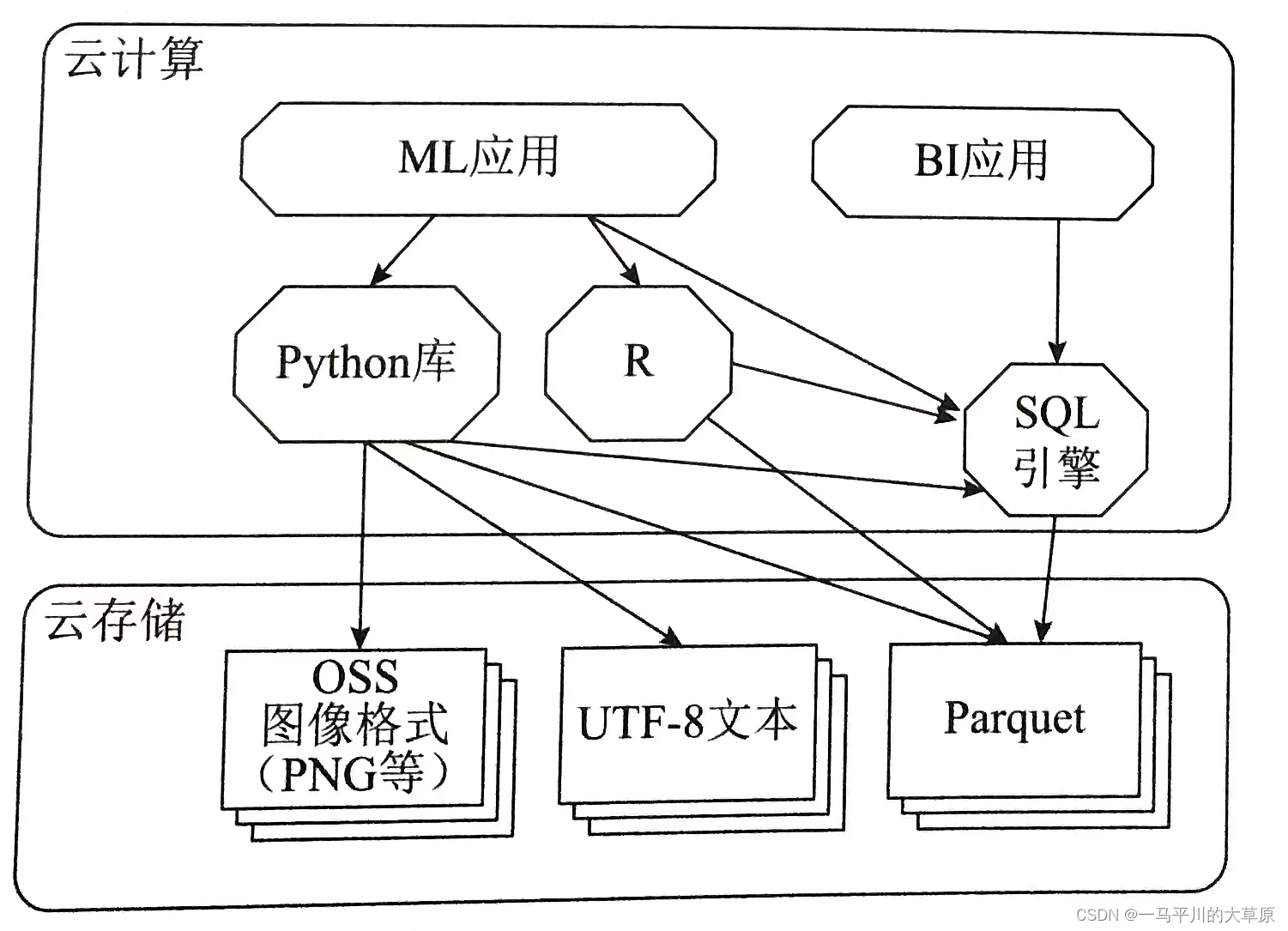
五、数据湖仓中的数据融合做什么
大数据分析环境一般只能处理一种类型数据,比如OLTP主要处理事务数据,数据仓库主要集成处理历史数据,文本环境主要处理文本数据。
数据湖仓由于存放了结构化、文本和非结构化数据,因此需要做数据融合处理,不同类型数据要进行数据融合分析处理,需要做业务和技术认知对齐、数据处理和算法的共识对齐,形成跨环境的通用信息。一般在融合过程中,需要用到通用连接器或通用标识符,比如时间、地理位置、货币、产品、名称、事件、身体测量数据、性别等。文本环境融合过程中的标识符有文档ID,分类标准,气田映射,词汇,context,关键词和关键词位置等。
六、数据可视化
数据为什么要进行可视化,可视化是一项技术,只有将数据转化为人们易于理解的信息才能体现价值,可视化是实现手段之一,通过可视化,能够发现数据中趋势、异常情况、模式规律和强相关性信息等。
数据可视化、数据分析和数据解释的关系,数据分析是使用系统化的方法查找不同类型数据之间的趋势、分组或其他关系,数据可视化是使用图形化进行展示的过程,使得数据更好理解解释,数据解释是赋予数据意义的过程,三者相互支持、相互告知和相互影响。
可视化优势:易于沟通、赢得关注、带来可信度、印象深刻、消息增强。
七、数据治理和数据湖仓的关系
数据作为一种全新的生产要素,逐步得到了人们的重视,相当于黄金或石油,数据是驱动力。数据治理目的是为企业业务的战略决策提供支持,让与数据相关的需求与商业战略连成一体,数据治理通过跨越人、流程、技术和数据框架来实现,重点关注文化如何支撑商业目标达成。数据治理和业务战略的一致性见下图。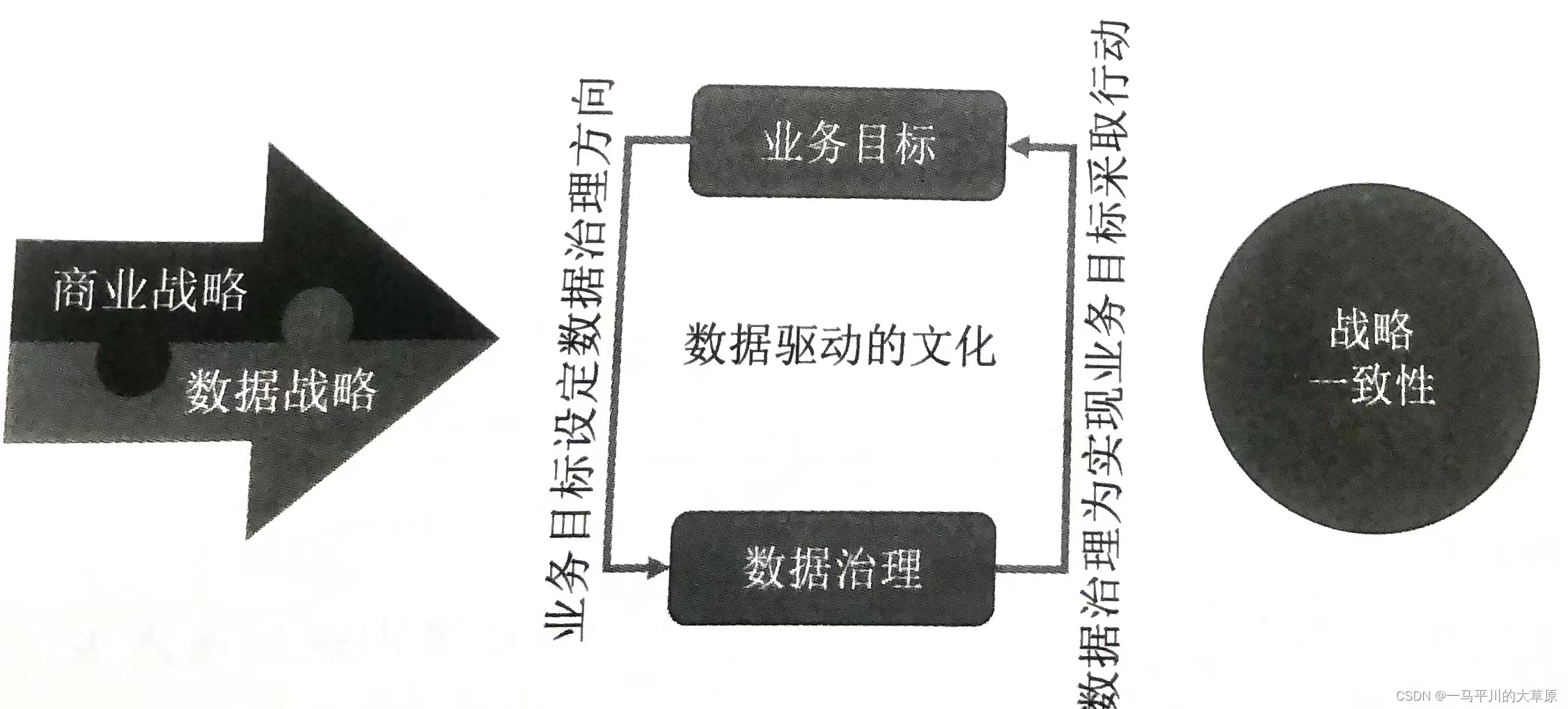
八、现代数据仓库是什么样子
现代数据仓库还是遵循数据仓库原来的定义,只是支持的技术、数据类型和技术架构都有巨大的变化,支持分布式、跨平台、多类型数据。总体应当还是面向主题域、集成、稳定、反映历史变化的仓库。
九、面向未来的数据是什么
面向未来的数据是预测未来并开放获取和组织数据的方法的过程,最大限度的减少由于丢失数据或缺乏相关数据而导致的与目标的差距,这些目标包括目标研究、相关性分析、趋势预测、模式发现、基于数据的存证、过往事件分析和实验等。而且不是企业收集的所有数据,而是具有对业务发展重要或相关性强的数据。构建需要五个阶段,分别为识别、消除淘汰、面向未来、组织和存储阶段。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!