【深度学习】机器学习概述(一)机器学习三要素——模型、学习准则、优化算法
?
文章目录
一、基本概念
??机器学习:通过算法使得机器能从大量数据中学习规律从而对新的样本做决策。
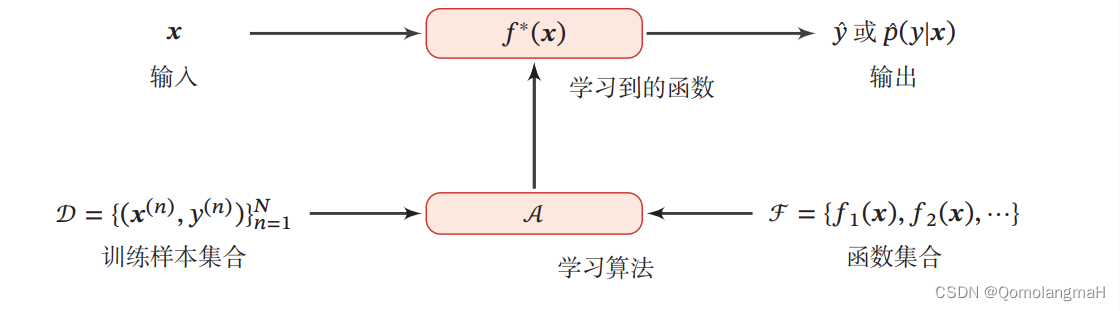
二、机器学习的三要素
??机器学习是从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并可以将总结出来的规律推广应用到未观测样本上。
??机器学习方法可以粗略地分为三个基本要素:模型、学习准则、优化算法。
1. 模型
a. 线性模型
??线性模型是一类简单但广泛应用的模型,其假设空间为一个参数化的线性函数族。对于分类问题,一般使用广义线性函数,其表达式为:
f
(
x
;
θ
)
=
w
T
x
+
b
f(\mathbf{x}; \boldsymbol{\theta}) = \mathbf{w}^T \mathbf{x} + b
f(x;θ)=wTx+b
其中,参数 θ \boldsymbol{\theta} θ 包含了权重向量 w \mathbf{w} w 和偏置 b b b。在这个模型中,输入特征 x \mathbf{x} x 和权重向量 w \mathbf{w} w 的线性组合用于产生输出。这是一个简单而有效的模型,特别适用于问题的线性关系。
b. 非线性模型
??广义的非线性模型可以写为多个非线性基函数 ? ( x ) \boldsymbol{\phi}(\mathbf{x}) ?(x) 的线性组合: f ( x ; θ ) = w T ? ( x ) + b f(\mathbf{x}; \boldsymbol{\theta}) = \mathbf{w}^T \boldsymbol{\phi}(\mathbf{x}) + b f(x;θ)=wT?(x)+b其中, ? ( x ) = [ ? 1 ( x ) , ? 2 ( x ) , … , ? K ( x ) ] T \boldsymbol{\phi}(\mathbf{x}) = [\phi_1(\mathbf{x}), \phi_2(\mathbf{x}), \ldots, \phi_K(\mathbf{x})]^T ?(x)=[?1?(x),?2?(x),…,?K?(x)]T 是由 K K K 个非线性基函数组成的向量,参数 θ \boldsymbol{\theta} θ 包含了权重向量 w \mathbf{w} w 和偏置 b b b。
??如果 ? ( x ) \boldsymbol{\phi}(\mathbf{x}) ?(x) 本身是可学习的基函数,例如:
? k ( x ) = h ( w k T ? ′ ( x ) + b k ) \phi_k(\mathbf{x}) = h(\mathbf{w}_k^T \boldsymbol{\phi}'(\mathbf{x}) + b_k) ?k?(x)=h(wkT??′(x)+bk?)其中, h ( ? ) h(\cdot) h(?) 是非线性函数, ? ′ ( x ) \boldsymbol{\phi}'(\mathbf{x}) ?′(x) 是另一组基函数, w k \mathbf{w}_k wk? 和 b k b_k bk? 是可学习的参数,那么模型 f ( x ; θ ) f(\mathbf{x}; \boldsymbol{\theta}) f(x;θ) 就等价于神经网络模型。
??这种非线性模型通过引入非线性基函数 ? ( x ) \boldsymbol{\phi}(\mathbf{x}) ?(x) 能够更灵活地适应数据中的复杂关系,使得模型能够捕捉到更丰富的特征信息。神经网络是非线性模型的一种重要实现方式。
2. 学习准则
a. 损失函数
1. 0-1损失函数
??0-1 损失函数是最直观的损失函数,用于衡量模型在训练集上的错误率。定义为:
L ( y , f ( x ; θ ) ) = { 0 if? y = f ( x ; θ ) 1 if? y ≠ f ( x ; θ ) \mathcal{L}(y, f(\mathbf{x}; \boldsymbol{\theta})) = \begin{cases} 0 & \text{if } y = f(\mathbf{x}; \boldsymbol{\theta}) \\ 1 & \text{if } y \neq f(\mathbf{x}; \boldsymbol{\theta}) \end{cases} L(y,f(x;θ))={01?if?y=f(x;θ)if?y=f(x;θ)?
或者使用指示函数表示:
L ( y , f ( x ; θ ) ) = I ( y ≠ f ( x ; θ ) ) \mathcal{L}(y, f(\mathbf{x}; \boldsymbol{\theta})) = \mathbb{I}(y \neq f(\mathbf{x}; \boldsymbol{\theta})) L(y,f(x;θ))=I(y=f(x;θ))
其中, I ( ? ) \mathbb{I}(\cdot) I(?) 是指示函数。
??尽管0-1损失函数直观,但由于其非连续性和不可导性,通常用其他连续可导的损失函数替代。
2. 平方损失函数(回归问题)
??平方损失函数常用于回归问题,定义为:
L
(
y
,
f
(
x
;
θ
)
)
=
1
2
(
y
?
f
(
x
;
θ
)
)
2
\mathcal{L}(y, f(\mathbf{x}; \boldsymbol{\theta})) = \frac{1}{2}(y - f(\mathbf{x}; \boldsymbol{\theta}))^2
L(y,f(x;θ))=21?(y?f(x;θ))2
平方损失函数适用于预测标签为实数值的任务,但一般不适用于分类问题。
3. 交叉熵损失函数(Cross-Entropy Loss)
??可用于分类任务,用于衡量两个概率分布之间的差异
交叉熵损失函数常用于分类问题。假设样本的标签
y
y
y 为离散的类别,模型的输出为类别标签的条件概率分布:
p
(
y
=
c
∣
x
;
θ
)
=
f
c
(
x
;
θ
)
p(y = c|\mathbf{x}; \boldsymbol{\theta}) = f_c(\mathbf{x}; \boldsymbol{\theta})
p(y=c∣x;θ)=fc?(x;θ)
其中, f c ( x ; θ ) f_c(\mathbf{x}; \boldsymbol{\theta}) fc?(x;θ) 表示模型输出向量的第 c c c 维。交叉熵损失函数定义为:
L ( y , f ( x ; θ ) ) = ? ∑ c = 1 C y c log ? f c ( x ; θ ) \mathcal{L}(\mathbf{y}, f(\mathbf{x}; \boldsymbol{\theta})) = -\sum_{c=1}^C y_c \log f_c(\mathbf{x}; \boldsymbol{\theta}) L(y,f(x;θ))=?c=1∑C?yc?logfc?(x;θ)
其中, y \mathbf{y} y 是样本的真实标签向量,表示类别 y y y 的one-hot向量。
4. Hinge 损失函数
??Hinge损失函数通常用于支持向量机等二分类问题,定义为:
L ( y , f ( x ; θ ) ) = max ? ( 0 , 1 ? y f ( x ; θ ) ) \mathcal{L}(y, f(\mathbf{x}; \boldsymbol{\theta})) = \max(0, 1 - yf(\mathbf{x}; \boldsymbol{\theta})) L(y,f(x;θ))=max(0,1?yf(x;θ))
或使用ReLU函数表示:
L ( y , f ( x ; θ ) ) = [ 1 ? y f ( x ; θ ) ] + \mathcal{L}(y, f(\mathbf{x}; \boldsymbol{\theta})) = [1 - yf(\mathbf{x}; \boldsymbol{\theta})]_+ L(y,f(x;θ))=[1?yf(x;θ)]+?
其中, [ x ] + = max ? ( 0 , x ) [x]_+ = \max(0, x) [x]+?=max(0,x)。
??这些损失函数在不同的任务和模型中发挥着关键的作用,选择合适的损失函数是模型设计中的重要决策。
b. 风险最小化准则
??在机器学习中,风险最小化准则是为了找到一个模型,使其在未知数据上的期望错误最小。然而,由于我们无法直接计算期望风险,通常使用经验风险(在训练集上的平均损失)来代替。以下是相关概念:
1. 经验风险最小化
??经验风险(Empirical Risk)是模型在训练集上的平均损失,表示为:
R emp ( θ ) = 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) ; θ ) ) \mathcal{R}_{\text{emp}}(\boldsymbol{\theta}) = \frac{1}{N} \sum_{n=1}^{N} \mathcal{L}(y^{(n)}, f(\mathbf{x}^{(n)}; \boldsymbol{\theta})) Remp?(θ)=N1?n=1∑N?L(y(n),f(x(n);θ))
其中, L \mathcal{L} L 是损失函数, N N N 是训练集中样本的数量。经验风险最小化准则的目标是找到一组参数 θ ? \boldsymbol{\theta}^* θ? 使经验风险最小化:
θ ? = arg ? min ? θ R emp ( θ ) \boldsymbol{\theta}^* = \arg\min_{\boldsymbol{\theta}} \mathcal{R}_{\text{emp}}(\boldsymbol{\theta}) θ?=argθmin?Remp?(θ)
这被称为经验风险最小化(Empirical Risk Minimization,ERM)准则。
2. 过拟合问题
??由于训练集通常是有限的,并且可能包含噪声,直接最小化经验风险可能导致模型在训练集上表现很好,但在未知数据上表现很差,即发生过拟合。
3. 结构风险最小化
??为了防止过拟合,可以在经验风险最小化的基础上引入正则化项,得到结构风险最小化(Structure Risk Minimization,SRM)准则:
θ ? = arg ? min ? θ ( R emp ( θ ) + λ 2 ∥ θ ∥ 2 2 ) \boldsymbol{\theta}^* = \arg\min_{\boldsymbol{\theta}} \left( \mathcal{R}_{\text{emp}}(\boldsymbol{\theta}) + \frac{\lambda}{2} \|\boldsymbol{\theta}\|_2^2 \right) θ?=argθmin?(Remp?(θ)+2λ?∥θ∥22?)
其中, λ \lambda λ 是正则化参数,控制正则化的强度。正则化项 λ 2 ∥ θ ∥ 2 2 \frac{\lambda}{2} \|\boldsymbol{\theta}\|_2^2 2λ?∥θ∥22? 通过限制参数的大小,有助于防止过拟合。
4. 正则化项的选择
??正则化项可以使用不同的函数,例如 ? 1 \ell_1 ?1? 范数。正则化的引入通常可以被解释为引入了参数的先验分布,使其不完全依赖于训练数据,从而有助于泛化。正则化的选择需要在模型训练中进行调整,以平衡经验风险和正则化项之间的权衡。
5. 欠拟合
??相反的情况是欠拟合(Underfitting),它发生在模型能力不足,不能很好地拟合训练数据,导致在训练集上的错误率较高。
??机器学习的目标不仅仅是在训练集上获得好的拟合,还需要在未知数据上表现良好,即具有较低的泛化错误。因此,学习准则的选择应该考虑到模型的泛化能力,防止过拟合和欠拟合的发生。
3. 优化
机器学习问题转化成为一个最优化问题
??一旦确定了训练集 D \mathcal{D} D、假设空间 F \mathcal{F} F 以及学习准则,接下来的任务就是通过优化算法找到最优的模型 f ( x , θ ? ) f(\mathbf{x}, \boldsymbol{\theta}^*) f(x,θ?)。机器学习的训练过程本质上是最优化问题的求解过程。
a. 参数与超参数
??优化可以分为参数优化和超参数优化两个方面:
-
参数优化: ( x ; θ ) (\mathbf{x}; \boldsymbol{\theta}) (x;θ) 中的 θ \boldsymbol{\theta} θ 称为模型的参数,这些参数通过优化算法进行学习。这些参数可以通过梯度下降等算法迭代地更新,以使损失函数最小化。
-
超参数优化: 除了可学习的参数 θ \boldsymbol{\theta} θ 外,还有一类参数用于定义模型结构或优化策略,这些参数被称为超参数。例如,聚类算法中的类别个数、梯度下降法中的学习率、正则化项的系数、神经网络的层数、支持向量机中的核函数等都是超参数。与可学习的参数不同,超参数的选取通常是一个组合优化问题,很难通过优化算法自动学习。通常,超参数的设定是基于经验或者通过搜索的方法对一组超参数组合进行不断试错调整。
b. 优化算法
??在训练模型的过程中,常用的优化算法包括梯度下降法、随机梯度下降法、牛顿法等。这些算法的核心思想是通过迭代更新模型的参数,使损失函数逐渐减小。
-
梯度下降法(Gradient Descent): 基本思想是沿着损失函数的梯度方向调整参数,以减小损失。学习率是一个重要的超参数,控制了每次迭代中参数更新的步长。
-
随机梯度下降法(Stochastic Gradient Descent,SGD): 与梯度下降法类似,但每次迭代只随机选择一个样本进行参数更新,通常更适用于大规模数据集。
-
牛顿法(Newton’s Method): 利用损失函数的二阶导数信息进行参数更新,收敛速度通常比梯度下降法快,但计算代价较高。
-
共轭梯度法(Conjugate Gradient): 特别适用于解线性方程组问题。
-
拟牛顿法(Quasi-Newton): 通过近似 Hessian 矩阵来加速梯度下降法的收敛速度。
-
Adam、Adagrad、RMSprop 等自适应学习率算法: 这些算法通过自适应地调整学习率,使得不同参数可以有不同的学习速度。
??选择合适的优化算法以及超参数是训练过程中的关键问题,通常需要进行实验和调参来获得最佳性能。
机器学习 = 优化?
??机器学习并不是只是单纯追求最小化经验风险
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!