机器学习(二)什么是机器学习
文章目录
什么是机器学习
在开始讲解术语概念之前我们首先梳理下之前讲到的一些概念。
(基本认识)机器学习专门研究计算机怎样模拟或实现人类的学习行为,使之不断改善自身性能。是一门能够发掘数据价值的算法和应用,它是计算机科学中最激动人心的领域。我们生活在一个数据资源非常丰富的年代,通过机器学习中的自学习算法,可以将这些数据转换为知识。
(机器学习库)借助于近些年发展起来的诸多强大的开源库,我们现在是进入机器学习领域的最佳时机。
(机器学习目的)从20世纪后半段,机器学习已经逐渐演化成为人工智能的一个分支,其目的是通过自学习算法从数据中获取知识,进而对未来进行预测。与以往通过大量数据分析而人工推导出规则并构造模型不同,机器学习提供了一种从数据中获取知识的方法,同时能够逐步提高预测模型的性能,并将模型应用于基于数据驱动的决策中去。
(应用)机器学习技术的存在,使得人们可以享受强大的垃圾邮件过滤带来的便利,拥有方便的文字和语音识别软件,能够使用可靠的网络搜索引擎,同时在象棋的网络游戏对阵中棋逢对手,而且Google已经将机器学习技术应用到了无人驾驶汽车中。
机器学习模型=数据+机器学习算法
1.4.1确定是否为机器学习问题
机器学习:从已有的经验中学习经验,从经验中去分析,接下来的若干问题请大家思考哪些问题可以用机器学习方式处理?
(1)计算每种颜色箱子的个数?----确定的问题
(2)计算一组数据平均值大小?----数值计算问题
机器学习的目的是建立预测模型–看是否有预测的过程
(1)确定收到的邮件是否为垃圾邮件?
(2)获取2014年世界杯冠军的名字?2018年?
(3)自动标记你在Facebook中的照片
(4)选择统计课程中成绩最高的学生(不是)
(5)考虑购物习惯,推荐相关商品?
(6)根据病人状况确定属于什么疾病?
(7)预测2018年人民币汇率涨or不涨?
(8)计算公司员工的平均工资?
1.5基于规则学习和基于模型的学习
1.5.1基于规则学习
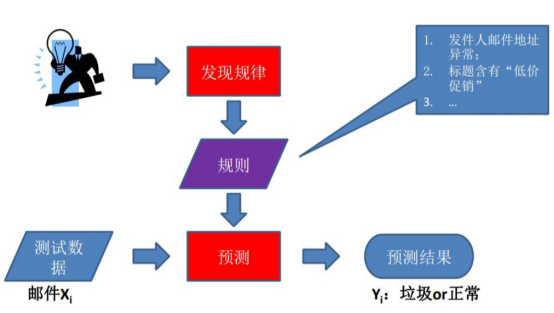
1.5.2基于模型学习
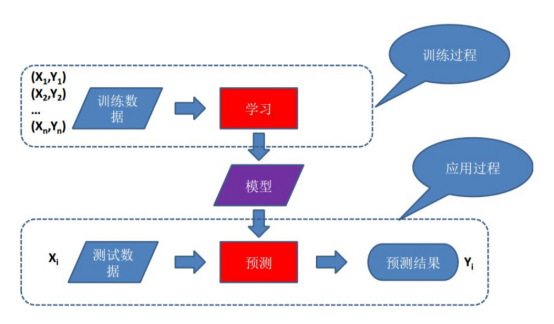
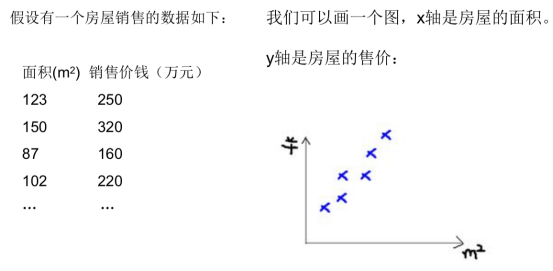
1.5.3房价预测问题
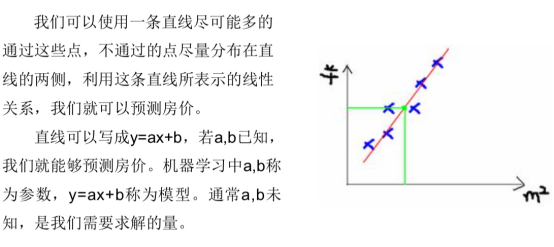
机器学习学习的是什么?
构建机器学习模型,如:y=kx+b,k和b是参数,x和y是特征和类别标签列。机器学习学习的是k和b的参数,如果k和b知道了,直接利用y=kx+b进行预测分析。
1.6机器学习数据的基本概念
1.6.1机器学习数据集基本概念强化实践
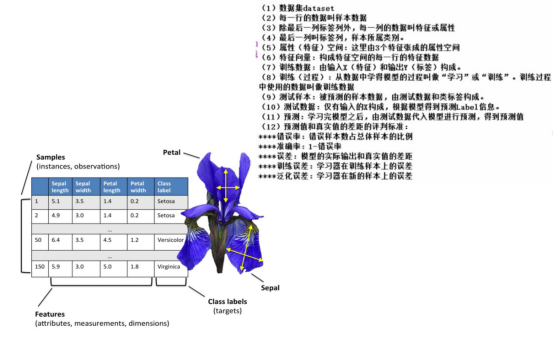
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,该数据集可以从加州大学欧文分校(UCI)的机器学习库中得到。鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Setosa、Versicolour和Virginica,每个花的特征用下面5种属性描述。
(1)萼片长度(厘米)
(2)萼片宽度(厘米)
(3)花瓣长度(厘米)
(4)花瓣宽度(厘米)
(5)类(Setosa、Versicolour、Virginica)
花的萼片是花的外部结构,保护花的更脆弱的部分(如花瓣)。在许多花中,萼片是绿的,只有花瓣是鲜艳多彩的,然而对与鸢尾花,萼片也是鲜艳多彩的。下图中的Virginica鸢尾花的图片,鸢尾花的萼片比花瓣大并且下垂,而花瓣向上。如下图:
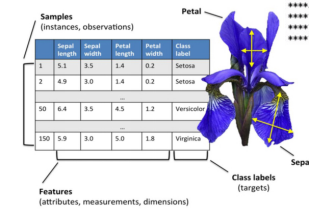
在鸢尾花中花数据集中,包含150个样本和4个特征,因此将其记作150x4维的矩阵,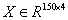 ,其中R表示向量空间,这里表示150行4维的向量,记作:
,其中R表示向量空间,这里表示150行4维的向量,记作:
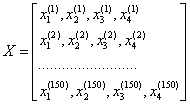
我们一般使用上标(i)来指代第i个训练样本,使用小标(j)来指代训练数据集中第j维特征。一般小写字母代表向量,大写字母代表矩阵。
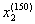 表示第150个花样本的第2个特征萼片宽度。在上述X的特征矩阵中,每一行表代表一个花朵的样本,可以记为一个四维行向量
表示第150个花样本的第2个特征萼片宽度。在上述X的特征矩阵中,每一行表代表一个花朵的样本,可以记为一个四维行向量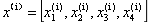
数据中的每一列代表样本的一种特征,可以用一个150维度的列向量表示:
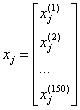
类似地,可以用一个150维度的列向量存储目标变量(类标)
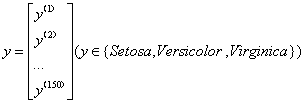
总结:
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12468207.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!