用通俗易懂的方式讲解:在 Langchain 中建立一个多模态的 RAG 管道
写在前面
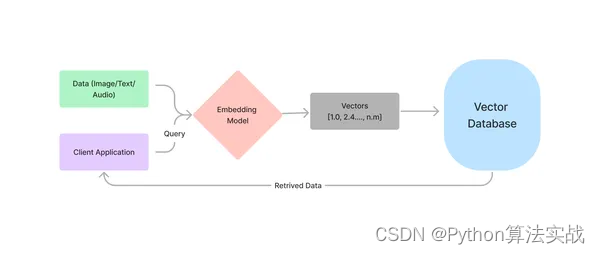
语言模型的出现彻底改变了我们从文件中提取信息的方式。然而,我们知道图片,通常是图表和表格,经常包含关键信息,但基于文本的语言模型无法处理媒体文件。
例如,我们以前只能使用 PDF 文件中的文本来查找答案。但是现在,随着不同实验室发布多模态语言模型,从图片中提取信息变得可能。像 GPT-4V 和 Gemini Pro Vision 这样的多模态模型已经展现出从图片中推断数据的强大能力。
我们可以利用这些模型来扩充常规的 RAG(检索增强生成)管道,构建一个多模态 RAG 管道。因此,在本文中,我们将使用 Gemini Pro 模型、Chroma 向量数据库和 Langchain 创建一个 MM-RAG 管道。
本文内容较长,1.2w字左右,梳理不易,记得收藏、关注、点赞
学习目标
- 对 Langchain 和向量数据库的简要介绍。
- 探讨构建多模态 RAG 管道的不同方法。
- 在 Langchain 中构建多向量检索器,使用 Chroma。
- 创建用于多模态数据的 RAG 管道。
目录
- Langchain 和向量数据库
- 构建多模态 RAG 管道的方法
- 构建 RAG 管道
- 文本和表格摘要
- 图片摘要
- 多向量检索器
- RAG 管道
- 常见问题解答
Langchain和向量数据库
Langchain 是2023年最热门的工具之一。它是一个用于构建任务链和LLM代理的开源框架。它几乎包含了创建功能性AI应用所需的所有工具。从数据加载器和向量存储到来自不同实验室的LLMs,它都涵盖了。
Langchain 有两个核心价值主张:链和代理。链是 Langchain 组件的序列。一个链的输出将作为另一个链的输入。为了简化开发,Langchain 有一种称为LCEL的表达语言。代理是由LLMs驱动的自主机器人。与链不同,步骤不是固定的;基于数据和工具描述的代理可以使用它能够访问的任何工具。我们将使用Langchain的表达语言来构建多模态管道。
RAG的另一个关键方面是向量数据库。这些数据库专为存储数据的嵌入而构建。向量数据库被设计为处理数百万个嵌入。因此,每当我们需要上下文感知检索时,向量存储变得隐式起来。为了获得数据的嵌入,使用嵌入模型;这些模型经过大量数据的训练,以找到文本的相似性。
构建多模态RAG管道的方法
那么,在多模态环境中如何构建RAG管道呢?有三种不同的方式可以创建MM-RAG管道。
选项1:使用多模态嵌入模型,如CLIP或Imagebind,创建图像和文本的嵌入。使用相似性搜索检索两者,然后将文档传递给多模态LLM。
选项2:使用多模态模型创建图像摘要。从向量存储中检索摘要,然后将它们传递给用于问答的LLM。
选项3:使用多模态LLM获取图像的描述。使用选择的任何嵌入模型嵌入文本描述,并将原始文档存储在文档存储中。通过参考原始图像和文本块检索摘要。将原始文档传递给多模态LLM进行答案生成。
每个选项都有其优缺点:
选项1对于通用图像可能效果良好,但在处理图表和表格时可能会遇到困难。
选项2是在不能频繁使用多模态模型时的选择。
选项3可提高准确性。像GPT-4V或Gemini这样的MM-LLMs可以理解图表和表格。选项3在涉及复杂图像理解时是一个选择。但它也会造成更高的成本。
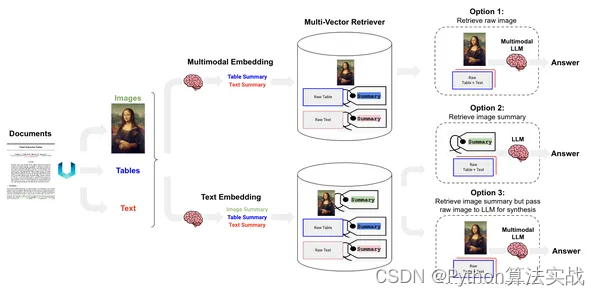
我们将使用Gemini Pro Vision来实现第三种方法。
通俗易懂讲解大模型系列
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群

构建RAG管道
既然我们已经了解所需的概念和工具,下面是一个快速的工作流程概述。
- 从文件中提取图像和文本。
- 从视觉LLM获取它们的摘要。
- 将摘要嵌入Chroma,将原始文件存储在内存数据库中。
- 创建一个多向量检索器。它使用相似度分数从数据存储中检索与其摘要相对应的原始文档。
- 将文档传递给多模态LLM以获取答案。
让我们深入研究编写 RAG 管道的过程。
依赖项
PDF和其他数据格式通常包含嵌入的表格和图片。提取它们并不像提取文本那么容易。为了实现这一点,我们需要像Unstructured这样的专用工具。Unstructured是一个用于预处理图像和文件(如HTML、PDF和Word文档)的开源工具。它可以使用OCR从文件中提取嵌入的图像。Unstrcured 需要在系统中安装Poppler和Tessecarct。
安装Tesseract和Poppler
!sudo apt install tesseract-ocr
!sudo apt-get install poppler-utils
现在,我们可以安装Unstructured以及其他所需的库。
!pip install "unstructured[all-docs]" langchain langchain_community chromadb langchain-experimental
提取图像和表格
我们使用partition_pdf来提取图像和表格。
from unstructured.partition.pdf import partition_pdf
image_path = "./"
pdf_elements = partition_pdf(
"mistral.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path=image_path
)
这将对PDF进行分区,并将图像提取到给定的路径。它还通过提供的策略和字符限制对文本进行分块。
现在,我们将文本和表格分开放入不同的组中。
# Categorize elements by type
def categorize_elements(raw_pdf_elements):
"""
Categorize extracted elements from a PDF into tables and texts.
raw_pdf_elements: List of unstructured.documents.elements
"""
tables = []
texts = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
texts.append(str(element))
return texts, tables
texts, tables = categorize_elements(pdf_elements)
文本和表格摘要
我们将使用Gemini Pro来获取文本块的简短摘要。Langchain为此目的提供了一个摘要链。我们将使用表达语言来构建一个简单的摘要链。要在Langchain中使用Gemini模型,您需要设置一个GCP(Google Cloud Platform)帐户。启用VertexAI并配置相应的凭据。
from langchain.chat_models import ChatVertexAI
from langchain.llms import VertexAI
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_core.messages import AIMessage
from langchain_core.runnables import RunnableLambda
# Generate summaries of text elements
def generate_text_summaries(texts, tables, summarize_texts=False):
"""
Summarize text elements
texts: List of str
tables: List of str
summarize_texts: Bool to summarize texts
"""
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text for retrieval. \
These summaries will be embedded and used to retrieve the raw text or table elements. \
Give a concise summary of the table or text that is well-optimized for retrieval. Table \
or text: {element} """
prompt = PromptTemplate.from_template(prompt_text)
empty_response = RunnableLambda(
lambda x: AIMessage(content="Error processing document")
)
# Text summary chain
model = VertexAI(
temperature=0, model_name="gemini-pro", max_output_tokens=1024
).with_fallbacks([empty_response])
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Initialize empty summaries
text_summaries = []
table_summaries = []
# Apply to text if texts are provided and summarization is requested
if texts and summarize_texts:
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 1})
elif texts:
text_summaries = texts
# Apply to tables if tables are provided
if tables:
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 1})
return text_summaries, table_summaries
# Get text, table summaries
text_summaries2, table_summaries = generate_text_summaries(
texts[9:], tables, summarize_texts=True
)
在这个链中,我们有四个不同的组件。第一个是一个字典,第二个用于创建一个提示模板,第三个是LLM模型,最后一个是字符串解析器。每个组件的输出被用作后续模块的输入。
AI Message类与可运行的Lambda一起,如果从LLM查询失败,则返回一条消息。
图片摘要
正如我们之前讨论的,我们将使用视觉模型获取图像的文本描述。您可以使用任何视觉模型,如GPT-4、Llava、Gemini等。在这里,我们将使用Gemini Pro Vision。
为了处理图像,我们将把它们转换为base64格式,并使用默认提示将它们传递给Gemini Pro Vision模型。
import base64
import os
from langchain_core.messages import HumanMessage
def encode_image(image_path):
"""Getting the base64 string"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def image_summarize(img_base64, prompt):
"""Make image summary"""
model = ChatVertexAI(model_name="gemini-pro-vision", max_output_tokens=1024)
msg = model(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img_base64}"},
},
]
)
]
)
return msg.content
def generate_img_summaries(path):
"""
Generate summaries and base64 encoded strings for images
path: Path to list of .jpg files extracted by Unstructured
"""
# Store base64 encoded images
img_base64_list = []
# Store image summaries
image_summaries = []
# Prompt
prompt = """You are an assistant tasked with summarizing images for retrieval. \
These summaries will be embedded and used to retrieve the raw image. \
Give a concise summary of the image that is well optimized for retrieval."""
# Apply to images
for img_file in sorted(os.listdir(path)):
if img_file.endswith(".jpg"):
img_path = os.path.join(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
image_summaries.append(image_summarize(base64_image, prompt))
return img_base64_list, image_summaries
fpath = "./"
# Image summaries
img_base64_list, image_summaries = generate_img_summaries(fpath)
多向量检索器
正如我们之前讨论的,我们将图像和表格描述的嵌入存储在向量存储中,并将原始文档存储在内存文档存储中。然后,我们从向量存储中检索与检索到的向量相对应的原始文档。Langchain具有一个多向量检索器来实现这一目标。因此,下面是我们如何构建一个多向量检索器。
import uuid
from langchain.embeddings import VertexAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
def create_multi_vector_retriever(
vectorstore, text_summaries, texts, table_summaries, tables, image_summaries, images
):
"""
Create retriever that indexes summaries, but returns raw images or texts
"""
# Initialize the storage layer
store = InMemoryStore()
id_key = "doc_id"
# Create the multi-vector retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Helper function to add documents to the vectorstore and docstore
def add_documents(retriever, doc_summaries, doc_contents):
doc_ids = [str(uuid.uuid4()) for _ in doc_contents]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(doc_summaries)
]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, doc_contents)))
# Add texts, tables, and images
# Check that text_summaries is not empty before adding
if text_summaries:
add_documents(retriever, text_summaries, texts)
# Check that table_summaries is not empty before adding
if table_summaries:
add_documents(retriever, table_summaries, tables)
# Check that image_summaries is not empty before adding
if image_summaries:
add_documents(retriever, image_summaries, images)
return retriever
# The vectorstore to use to index the summaries
vectorstore = Chroma(
collection_name="mm_rag_mistral",
embedding_function=VertexAIEmbeddings(model_name="textembedding-gecko@latest"),
)
# Create retriever
retriever_multi_vector_img = create_multi_vector_retriever(
vectorstore,
text_summaries,
texts,
table_summaries,
tables,
image_summaries,
img_base64_list,
)
在上面的代码中,我们定义了一个Chroma向量存储和一个内存文档存储,并将它们传递给多向量检索器。我们嵌入和存储了文本、表格和图像的摘要在Chroma集合中。
RAG管道
我们将使用Langchain表达语言来构建最终的管道。
import io
import re
from IPython.display import HTML, display
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from PIL import Image
def looks_like_base64(sb):
"""Check if the string looks like base64"""
return re.match("^[A-Za-z0-9+/]+[=]{0,2}$", sb) is not None
def is_image_data(b64data):
"""
Check if the base64 data is an image by looking at the start of the data
"""
image_signatures = {
b"\xFF\xD8\xFF": "jpg",
b"\x89\x50\x4E\x47\x0D\x0A\x1A\x0A": "png",
b"\x47\x49\x46\x38": "gif",
b"\x52\x49\x46\x46": "webp",
}
try:
header = base64.b64decode(b64data)[:8] # Decode and get the first 8 bytes
for sig, format in image_signatures.items():
if header.startswith(sig):
return True
return False
except Exception:
return False
def resize_base64_image(base64_string, size=(128, 128)):
"""
Resize an image encoded as a Base64 string
"""
# Decode the Base64 string
img_data = base64.b64decode(base64_string)
img = Image.open(io.BytesIO(img_data))
# Resize the image
resized_img = img.resize(size, Image.LANCZOS)
# Save the resized image to a bytes buffer
buffered = io.BytesIO()
resized_img.save(buffered, format=img.format)
# Encode the resized image to Base64
return base64.b64encode(buffered.getvalue()).decode("utf-8")
def split_image_text_types(docs):
"""
Split base64-encoded images and texts
"""
b64_images = []
texts = []
for doc in docs:
# Check if the document is of type Document and extract page_content if so
if isinstance(doc, Document):
doc = doc.page_content
if looks_like_base64(doc) and is_image_data(doc):
doc = resize_base64_image(doc, size=(1300, 600))
b64_images.append(doc)
else:
texts.append(doc)
if len(b64_images) > 0:
return {"images": b64_images[:1], "texts": []}
return {"images": b64_images, "texts": texts}
def img_prompt_func(data_dict):
"""
Join the context into a single string
"""
formatted_texts = "\n".join(data_dict["context"]["texts"])
messages = []
# Adding the text for analysis
text_message = {
"type": "text",
"text": (
"You are an AI scientist tasking with providing factual answers.\n"
"You will be given a mixed of text, tables, and image(s) usually of charts or graphs.\n"
"Use this information to provide answers related to the user question. \n"
f"User-provided question: {data_dict['question']}\n\n"
"Text and / or tables:\n"
f"{formatted_texts}"
),
}
messages.append(text_message)
# Adding image(s) to the messages if present
if data_dict["context"]["images"]:
for image in data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image}"},
}
messages.append(image_message)
return [HumanMessage(content=messages)]
def multi_modal_rag_chain(retriever):
"""
Multi-modal RAG chain
"""
# Multi-modal LLM
model = ChatVertexAI(
temperature=0, model_name="gemini-pro-vision", max_output_tokens=1024
)
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(split_image_text_types),
"question": RunnablePassthrough(),
}
| RunnableLambda(img_prompt_func)
| model
| StrOutputParser()
)
return chain
# Create RAG chain
chain_multimodal_rag = multi_modal_rag_chain(retriever_multi_vector_img)
RAG链是使用多向量检索器、Gemini Pro Vision和一个用于在LLM响应中添加指令的函数创建的。
该链具有多个组件链接在一起:
- 第一个组件是一个包含上下文和用户查询的字典。上下文键的值是另一个包含检索器和用于分离图像和文本的函数的链。
- 然后将最终的字典传递给一个函数,该函数为加强LLM响应添加指令。
- Chat模型接收上一步骤的输出,并根据查询和上下文生成响应。
- 最后,使用StrOutputParser解析输出。
现在,我们可以调用该链并获取我们的查询答案。您可以运行检索器,看它是否检索到了正确的文档。
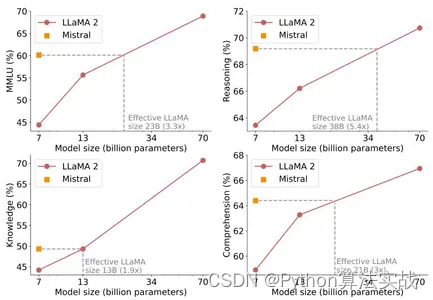
query = """compare and contrast between mistral and llama2 across benchmarks and
explain the reasoning in detail"""
docs = retriever_multi_vector_img.get_relevant_documents(query, limit=1)
docs[0]
我使用了官方的 Mistral Arxiv 论文作为参考的 PDF。运行该单元格返回了以下图表。考虑到我提出的查询,这看起来是正确的。
现在,使用查询调用RAG链,看看链是否按预期工作。
chain_multimodal_rag.invoke(query)
为了获得更好的答案,尝试调整提示。通常,通过微调提示,您可以获得更好的响应。
因此,这就是构建在Langchain中的MM-RAG的全部内容。
结论
RAG与向量数据库的配对填补了LLMs的一个关键缺陷,即减少了虚构。RAG和向量搜索创造了一种新的技术子流派。随着具有视觉功能的LLMs,我们现在可以从图像中检索信息。我们还可以处理并从文件中嵌入的图像以及文本中获取答案。
因此,在本文中,我们使用了Langchain、chroma、Gemini和Unstructured来构建一个多模态的RAG管道。
以下是主要要点。
在标准RAG中,很多信息以图像的形式保持不变。通过增加具有视觉功能的LLMs的现有RAG,多模态RAG填补了这一差距。
有不同的方法来构建多模态RAG。使用多模态LLM进行图像摘要,通过计算摘要的相似度分数检索到的原始文档传递给多模态LLM以查询文本,提供了最高的准确性。
Langchain是一个用于构建LLM工作流和代理的开源框架。
它提供了一个多向量检索器,用于从多个数据存储中检索文档。
常见问题解答
Q1. Langchain用于什么?
A. LangChain是一个开源框架,简化了使用大型语言模型创建应用程序的过程。它可用于各种任务,包括聊天机器人、文档分析、代码分析、问答和生成性任务。
Q2. Langchain中的链和代理有什么区别?
代理比链更复杂。它们可以决定执行哪些步骤,还可以从经验中学习。代理通常用于需要大量创造力或推理的任务,例如数据分析和代码生成。
Q3. 什么是多模态AI?
A. 多模态AI是指能够处理和理解各种数据模态,如图像、文本、音频等的机器学习模型。
Q4. 什么是RAG管道?
A. RAG管道从外部数据存储中检索文档,对其进行处理以存储在知识库中,并提供查询工具。
Q5. Langchain和Llama Index之间有什么区别?
A. Llama Index专门设计用于搜索和检索应用程序,而Langchain提供了创建自定义AI代理的灵活性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!