学习率调整策略
学习率?是指在训练模型时更新模型权重的速度(即参数到达最优值过程的速度快慢),? 学习率越高,模型更新的速度越快,? ?如果太高,模型可能在训练数据上过拟合,就是在训练数据上表现很好,测试数据上表现不佳;学习率越低,模型更新速度越慢,如果太低,模型可能无法在训练数据上充分学习
PyTorch 通过 torch.optim.lr_scheduler 接口实现对学习率的调整策略,可以分为三大类:
- 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和余弦退火 (CosineAnnealing)
- 自适应调整:自适应调整学习率ReduceLROnPlateau
- 自定义调整:自定义调整学习率LambdaLR
常见的学习率调整策略
lr_scheduler.ChainedScheduler?
等间隔调整学习率 StepLR
等间隔调整学习率,调整倍数为 gamma 倍,调整间隔是 step_size,也就是每隔step_size个epoch进行学习率的调整
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
step_size(int) - 学习率下降间隔数,若为 30,则会在第?30、 60、 90…个 epoch 时将学习率调整为 lr*gamma
gamma(float) - 学习率调整倍数,默认为 0.1 倍,即下降 10 倍
last_epoch(int) - 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值
例如:
import torch
from torch import nn, optim
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 将numpy数组格式的x_train和y_train转换为tensor张量
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
# Linear Regression Model 定义线性回归模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear1 = nn.Linear(1, 5) # input and output is 1 dimension
self.linear2 = nn.Linear(5, 1)
def forward(self, x):
out = self.linear1(x)
out = self.linear2(out)
return out
model = LinearRegression() # 创建线性回归模型的实例对象
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
# 创建一个使用SGD算法的优化器对象optimizer
optimizer = optim.SGD (
[{"params": model.linear1.parameters(), "lr": 0.01}, # 获取模型中linear1层的参数,并设置学习率为0.01
{"params": model.linear2.parameters()}], # 获取模型中linear2层的参数,并使用默认的学习率0.02
lr=0.02) # 默认的学习率为0.02
# 创建等间隔调整学习率调度策略
step_schedule = optim.lr_scheduler.StepLR(step_size=20, gamma=0.9, optimizer=optimizer)
step_lr_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
step_schedule.step()
step_lr_list.append(step_schedule.get_last_lr()[0])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(step_lr_list)), step_lr_list, label="step_lr")
plt.legend()
plt.show()运行结果
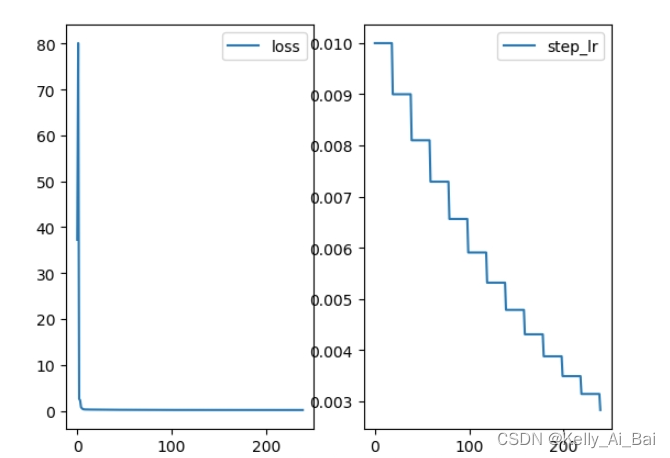
初始的学习率为0.01,gamma为0.9,step_size为?20,所以每间隔20个epoch,学习率就乘以gamma
注意:学习率调整要放在optimizer更新之后, 如果scheduler.step( )放在optimizer.step( )的前面,将会跳过学习率更新的第一个值
?
按需调整学习率 MultiStepLR
按设定的间隔调整学习率
这个方法适合后期调试使用,观察 loss 曲线,通过参数milestones给定衰减的epoch列表,可以在指定的epoch时期进行衰减
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
milestones(list)- 一个 list,每一个元素代表何时调整学习率, list 元素必须是递增的,,如 milest ones = [30,80,120]
gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍?
例如:
model = LinearRegression()
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(
[{"params": model.linear1.parameters(), "lr": 0.01},
{"params": model.linear2.parameters()}],
lr=0.02)
# 创建按设定的间隔调整学习率的学习率调度策略
# 在epoch为120和180的时候进行学习率的调整
multi_schedule = optim.lr_scheduler.MultiStepLR(optimizer=optimizer,milestones=[120,180])
multi_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
multi_schedule.step()
multi_list.append(multi_schedule.get_last_lr()[0])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(multi_list)), multi_list, label="step_lr")
plt.legend()
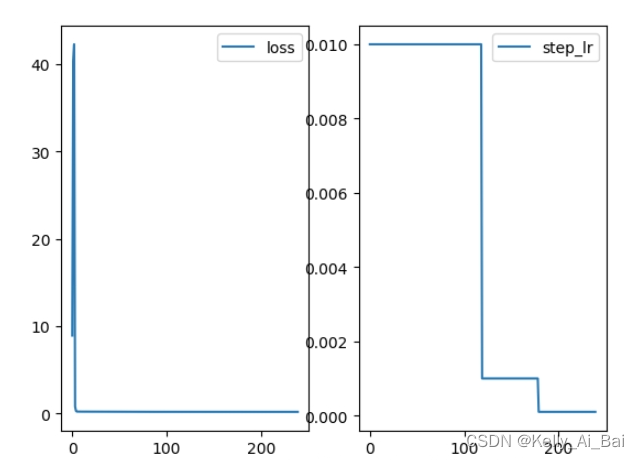
plt.show()运行结果:?
?
指数衰减调整学习率 ExponentialLR
按指数衰减调整学习率,调整公式:lr=lr?gamma**e,e代表epoch
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
gamma?- 以gamma为底,指数为 epoch,进行学习率的调整
model = LinearRegression()
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(
[{"params": model.linear1.parameters(), "lr": 0.01},
{"params": model.linear2.parameters()}],
lr=0.02)
# 创建指数衰减调整学习率的学习率调度策略
exponent_schedule = optim.lr_scheduler.ExponentialLR(optimizer=optimizer,gamma=0.9)
multi_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
exponent_schedule.step()
multi_list.append(exponent_schedule.get_last_lr()[0])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(multi_list)), multi_list, label="step_lr")
plt.legend()
plt.show()运行结果:

余弦退火调整学习率 CosineAnnealingLR
余弦学习率衰减方法相对于线性学习率衰减方法来说,可以更快地达到最佳效果,更好地保持模型的稳定性,同时也可以改善模型的泛化性能
余弦学习率衰减?前期衰减慢,中期衰减快,后期衰减慢,和模型的学习有相似之处
以?余弦函数?为周期,并在每个周期最大值时重新设置学习率
以初始学习率为最大学习率,以 2?Tmax为周期,在一个周期内先下降,后上升
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
T_max(int) - 一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率
eta_min(float) - 最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0
model = LinearRegression()
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(
[{"params": model.linear1.parameters(), "lr": 0.01},
{"params": model.linear2.parameters()}],
lr=0.02)
# 创建余弦退火调整学习率的调度策略
# 以 2*20 为周期,在一个周期内先下降后上升,即20个epoch后就重新设置学习率,在一个周期中学习率最小会降低到 0.0004
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=20,eta_min=0.0004)
multi_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
cosine_schedule.step()
multi_list.append(cosine_schedule.get_last_lr()[0])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(multi_list)), multi_list, label="cosine_lr")
plt.legend()
plt.show()运行结果:
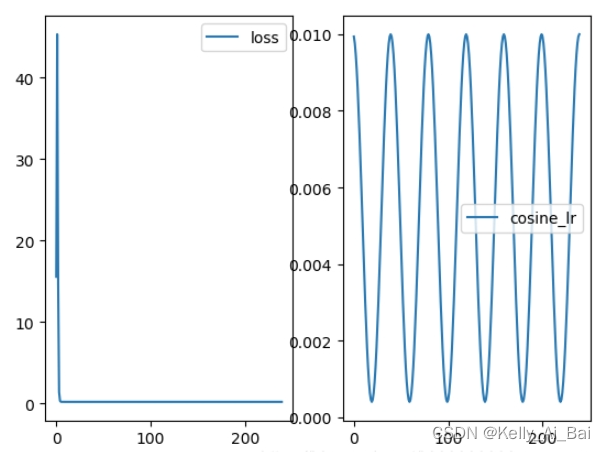
?
自适应调整学习率 ReduceLROnPlateau
当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略
例如,当验证集的 loss 不再下降时,进行学习率调整;或者监测验证集的 accuracy,当accuracy 不再上升时,则调整学习率
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
mode(str)- 模式选择,有 min 和 max 两种模式, min 表示当指标不再降低(如监测loss), max 表示当指标不再升高(如监测 accuracy)
factor(float)- 学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr = lr * factor
patience(int)- 忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率
verbose(bool)- 是否打印学习率信息
threshold_mode(str)- 选择判断指标是否达最优的模式,有两种模式, rel 和 abs
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best * ( 1 +threshold );
当 threshold_mode == rel,并且 mode == min 时, dynamic_threshold = best * ( 1 -threshold );
当 threshold_mode == abs,并且 mode== max 时, dynamic_threshold = best + threshold ;
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best - threshold;
threshold(float)- 配合 threshold_mode 使用
cooldown(int)- “冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式
min_lr(float or list)- 学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置
eps(float)- 学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率
?
model = LinearRegression()
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(
[{"params": model.linear1.parameters(), "lr": 0.01},
{"params": model.linear2.parameters()}],
lr=0.02)
# 创建自适应调整的学习率调度策略
reduce_schedule = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,verbose=False, threshold=1e-4, threshold_mode='rel',cooldown=0, min_lr=0, eps=1e-8)
multi_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 根据不再下降的损失值 loss 或者是不再上升的 accuracy 来调整学习率
reduce_schedule.step(loss)
multi_list.append(optimizer.param_groups[0]["lr"])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(multi_list)), multi_list, label="reduce_lr")
plt.legend()
plt.show()运行结果:
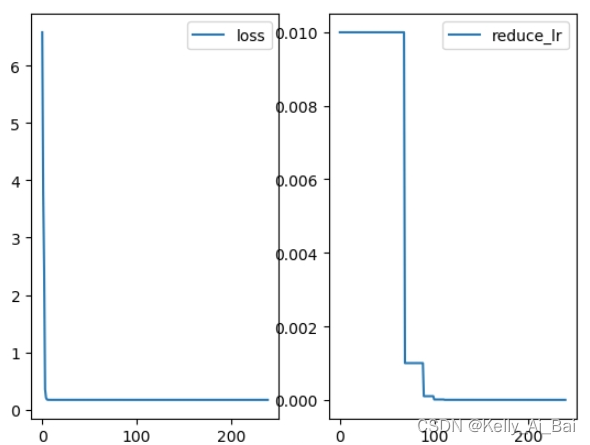
自定义调整学习率 LambdaLR
为不同参数组设定不同学习率调整策略
将每一个参数组的学习率设置为初始学习率 lr 的某个函数倍
LambdaLR 提供了更加灵活的方式让使用者自定义衰减函数,完成特定的学习率曲线
LambdaLR通过?将lambda函数的乘法因子应用到初始LR来调整学习速率
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
lr_lambda ( 是一个函数,或者列表(list) ) --?当是一个函数时,需要给其一个整数参数,使其计算出一个乘数因子,用于调整学习率,通常该输入参数是epoch数目或者是一组上面的函数组成的列表
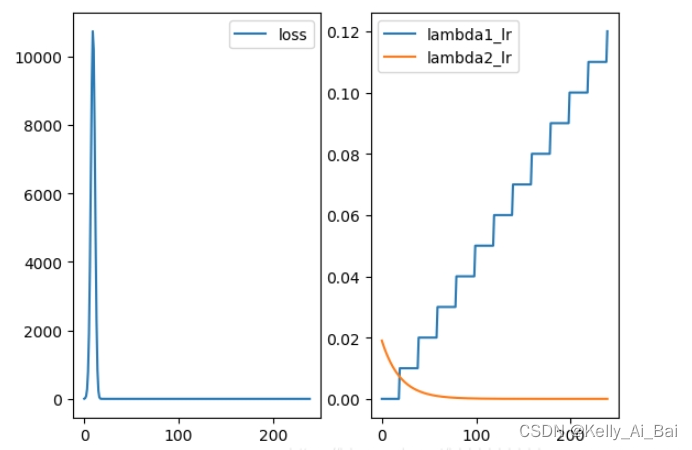
例1:
# 用于调整学习率的函数lambda1和lambda2
lambda1 = lambda epoch: epoch//20
lambda2 = lambda epoch: 0.95**epoch
model = LinearRegression()
print(model.linear1)
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(
[{"params": model.linear1.parameters(), "lr": 0.01}, # 第一个参数组
{"params": model.linear2.parameters()}], # 第二个参数组
lr=0.02)
# 创建自定义的学习率调度策略
lambda_schedule = optim.lr_scheduler.LambdaLR(optimizer=optimizer,lr_lambda=[lambda1,lambda2])
lambda1_list = []
lambda2_list = []
loss_list = []
# 开始训练
num_epochs = 240
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
lambda_schedule.step()
# 获取优化器中第一个参数组的学习率值,将其添加到lambda1_list列表中
lambda1_list.append(optimizer.param_groups[0]["lr"])
# 获取优化器中第二个参数组的学习率值,将其添加到lambda2_list列表中
lambda2_list.append(optimizer.param_groups[1]["lr"])
loss_list.append(loss.item())
plt.subplot(121)
plt.plot(range(len(loss_list)), loss_list, label="loss")
plt.legend()
plt.subplot(122)
plt.plot(range(len(lambda1_list)),lambda1_list,label="lambda1_lr")
plt.plot(range(len(lambda2_list)),lambda2_list,label="lambda2_lr")
plt.legend()
plt.show()运行结果:
例2:
import torch
# 定义了一个函数 create_lr_scheduler,用于创建学习率调度器
# 创建一个学习率调度器对象,根据给定的参数设置学习率在训练过程中的变化规律
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3,
end_factor=1e-6):
'''
optimizer, # 优化器对象,用于更新模型的参数
num_step: int, # 每个epoch中的步数,即数据加载器的长度
epochs: int, # 训练的总轮数
warmup=True, # 是否进行学习率的预热,默认为True
warmup_epochs=1, # 预热的轮数,默认为1
warmup_factor=1e-3, # 预热过程中学习率的倍率因子,默认为1e-3
end_factor=1e-6 # 训练结束时学习率的倍率因子,默认为1e-6
'''
assert num_step > 0 and epochs > 0 # 首先进行断言,确保 num_step 和 epochs 的值大于0
if warmup is False: # 如果 warmup 为 False,则将 warmup_epochs 设置为0,表示不进行预热
warmup_epochs = 0
def f(x): # 定义了一个内部函数f(x),该函数根据当前的步数x返回学习率的倍率因子
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
'''
如果进行预热(warmup=True)并且当前步数 x 小于等于预热的总步数(warmup_epochs * num_step),则 计算预热过程中学习率的倍率因子
首先计算当前步数相对于预热总步数的比例 alpha,然后将学习率倍率因子从 warmup_factor 线性地从预热因子逐渐增加到 1
'''
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
'''
如果不在预热阶段或者当前步数大于预热总步数,则 计算训练过程中学习率的倍率因子
首先计算当前步数相对于训练过程中的总步数 cosine_steps 的比例 current_step,然后使用余弦函数的形式将学习率倍率因子从 1 逐渐减小到 end_factor
'''
current_step = (x - warmup_epochs * num_step)
cosine_steps = (epochs - warmup_epochs) * num_step
# warmup后lr倍率因子从1 -> end_factor
return ((1 + math.cos(current_step * math.pi / cosine_steps)) / 2) * (1 - end_factor) + end_factor
# 最后,使用 torch.optim.lr_scheduler.LambdaLR 创建一个学习率调度器对象,并传入优化器 optimizer 和学习率函数 lr_lambda=f
# 函数返回创建的学习率调度器对象
# lr_lambda 函数不需要显式地接收参数 x,而是通过内部访问优化器的状态来计算学习率倍率因子, 这种方式使得学习率函数能够根据实际情况自动调整学习率,而无需外部传递参数
# 将函数对象 f 传递给 lr_lambda 参数,而不是函数调用的结果, 这样,学习率调度器就可以在每次需要计算学习率时调用函数 f,并传递当前的步数作为参数
# 在学习率调度器中,存在一个内部的计数器,用于追踪当前的步数
# 每当调用 scheduler.step() 方法时,计数器会增加,然后将当前的步数作为参数传递给学习率函数 lr_lambda,也就是函数 f(x)
# 函数 f(x) 根据当前的步数 x 来计算学习率的倍率因子,并返回该值
# 所以,参数 x 是从学习率调度器内部传递给函数 f(x) 的当前步数
# 这样设计的目的是让学习率函数能够根据实际的训练进度来自动调整学习率
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)在此段代码中使用了自定义的学习率调整策略 , torch.optim.lr_scheduler.LambdaLR ( optimizer ,lr_lambda=f?),参数 lr_lambda 接受的是自定义的函数 f,在这里函数 f 有一个参数 x,x 是从学习率调取器内部传递给函数的当前步数
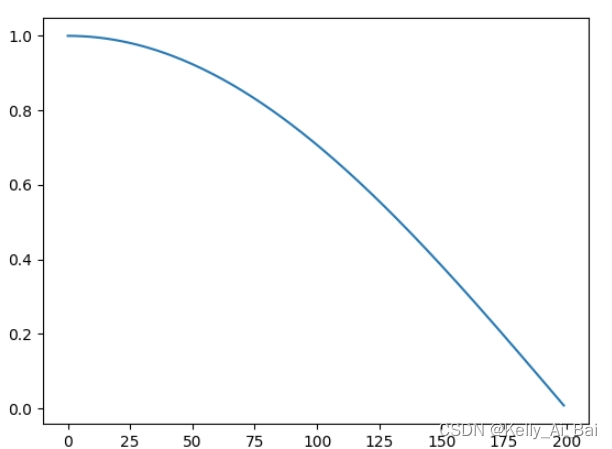
例3:
lambda1 = lambda epoch: np.cos(epoch/max_epoch*np.pi/2)
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1])运行结果:?
?
?
自定义调整学习率 MultiplicativeLR
MultiplicativeLR 同样可以自定义学习率的变化,与LambdaLR不同的是?MultiplicativeLR 通过将lambda 函数的乘法因子应用到前一个 epoch 的 LR 来调整学习速率
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
lr_lambda (函数?or 列表) –当是一个函数时,需要给其一个整数参数,使其计算出一个乘数因子,用于调整学习率,通常该输入参数是epoch数目或者是一组上面的函数组成的列表
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
例如:
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)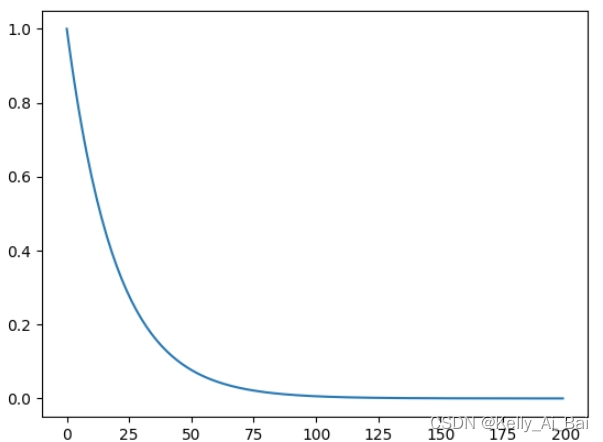
?
lr_scheduler.ConstantLR
在 total_iters 轮内将 optimizer 中指定的学习率乘以 factor ,大于 total_iters 轮就恢复原学习率
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.33, total_iters=5, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
factor (float) – 学习率衰减的常数因子,默认值:1./3
total_iters (int) – 学习率衰减直到设定的epoch值,默认值:5
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
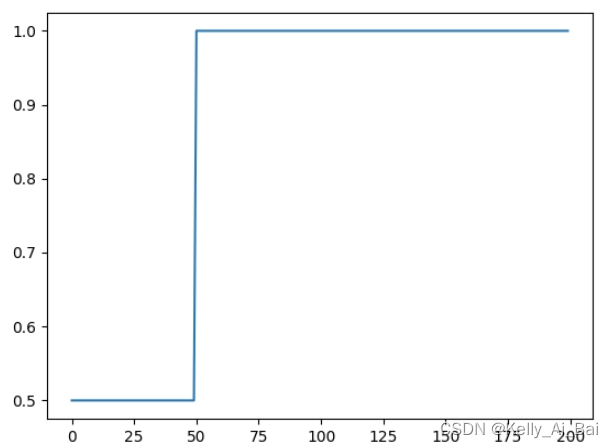
例如:
scheduler = ConstantLR(optimizer, factor=0.5, total_iters=50)前50个epoch(包括第50epoch)的学习率要乘以 factor(此处是1*0.5 = 0.5),迭代50个epoch后就恢复原始的学习率为1?
运行结果:?
?
lr_scheduler.LinearLR
线性改变每个参数组的学习率,直到 epoch 达到预定义的值(total_iters)
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.33, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
start_factor (float) – 在开始时,学习率的值。默认值:1./3
end_factor (float) – 在结束时,学习率的值。默认值:1.0
total_iters (int) – 学习率衰减率变为1时的epoch值,默认值:5.
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
?
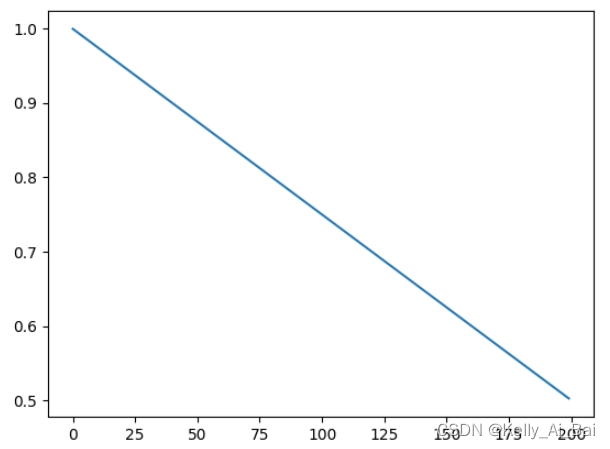
例如:
scheduler = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=200)在上述代码中,刚开始时 start_factor=1 表示学习率为1,迭代200个epoch后 end_factor 表示学习率最终变为1/2?
运行结果:?
?
?
lr_scheduler.SequentialLR?
可以?将多种衰减方式以串联的方式进行组合
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
schedulers (list) – 学习率调整策略(scheduler)的列表
milestones (list) – 策略变化的epoch转折点,整数列表
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
例如:
scheduler1 = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=100)
scheduler2 = CosineAnnealingLR(optimizer, T_max=100, eta_min=0.5)
schedulers = [scheduler1, scheduler2]
milestones = [100]
scheduler = SequentialLR(optimizer, schedulers, milestones)
运行结果:

?
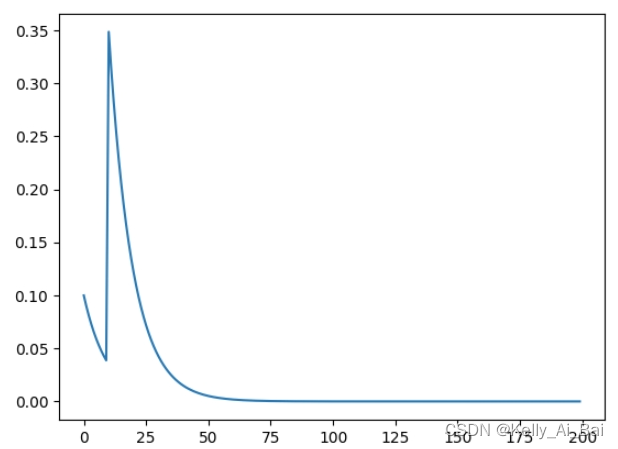
lr_scheduler.ChainedScheduler?
ChainedScheduler 和 SequentialLR 类似,也是?按照顺序调用多个串联起来的学习率调整策略,不同的是 ChainedScheduler 里面的学习率变化是连续的
torch.optim.lr_scheduler.ChainedScheduler(schedulers)
schedulers (list) – 学习率调整策略(scheduler)的列表
例如:
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=10)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = ChainedScheduler([scheduler1,scheduler2])运行结果:
总结
介绍完上面的学习率设置后,要根据实际情况选择不同的策略?
一般来说等间隔调整学习率、自适应调整学习率、余弦退火调整学习率
参考文章:?
PyTorch学习之六个学习率调整策略_multisteplr-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!