hive聚合函数之排序
1 全局排序(Order By)
Order By:全局排序,只有一个Reduce。
(1).使用Order By子句排序
asc(ascend):升序(默认)
desc(descend):降序
(2).Order By子句在select语句的结尾
基础案例实操
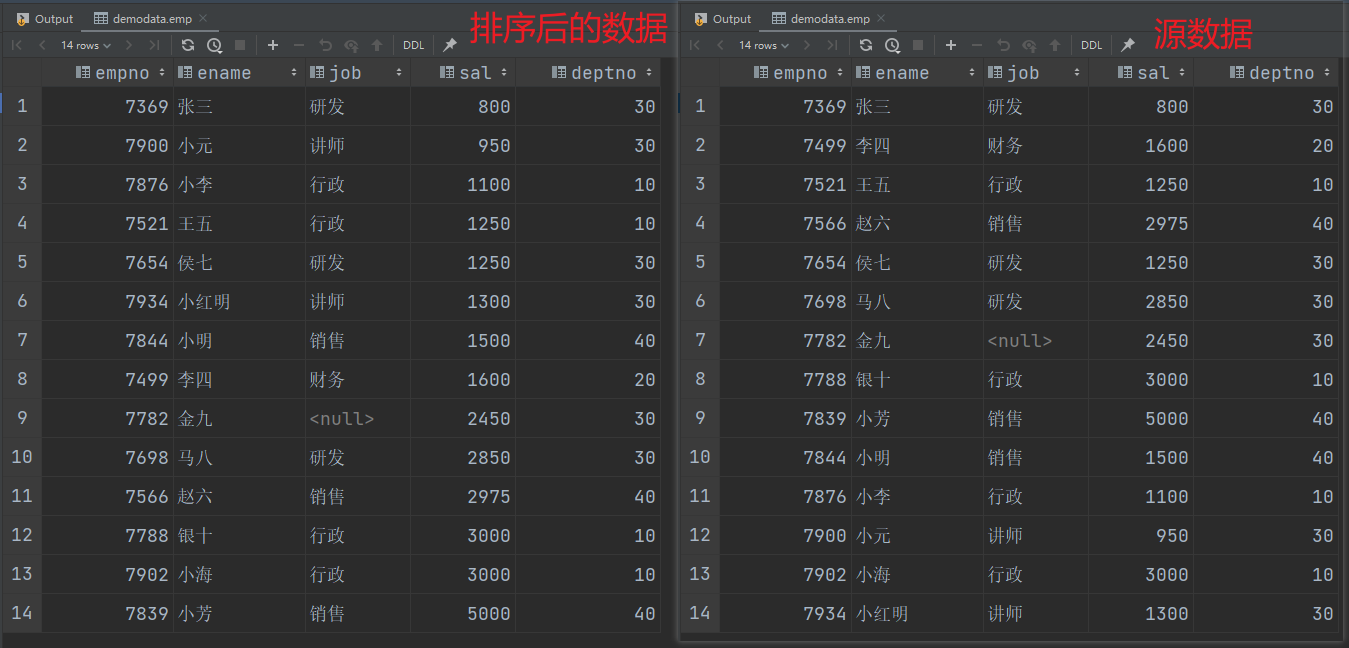
(1)查询员工信息按工资升序排列
select
*
from emp
order by sal;
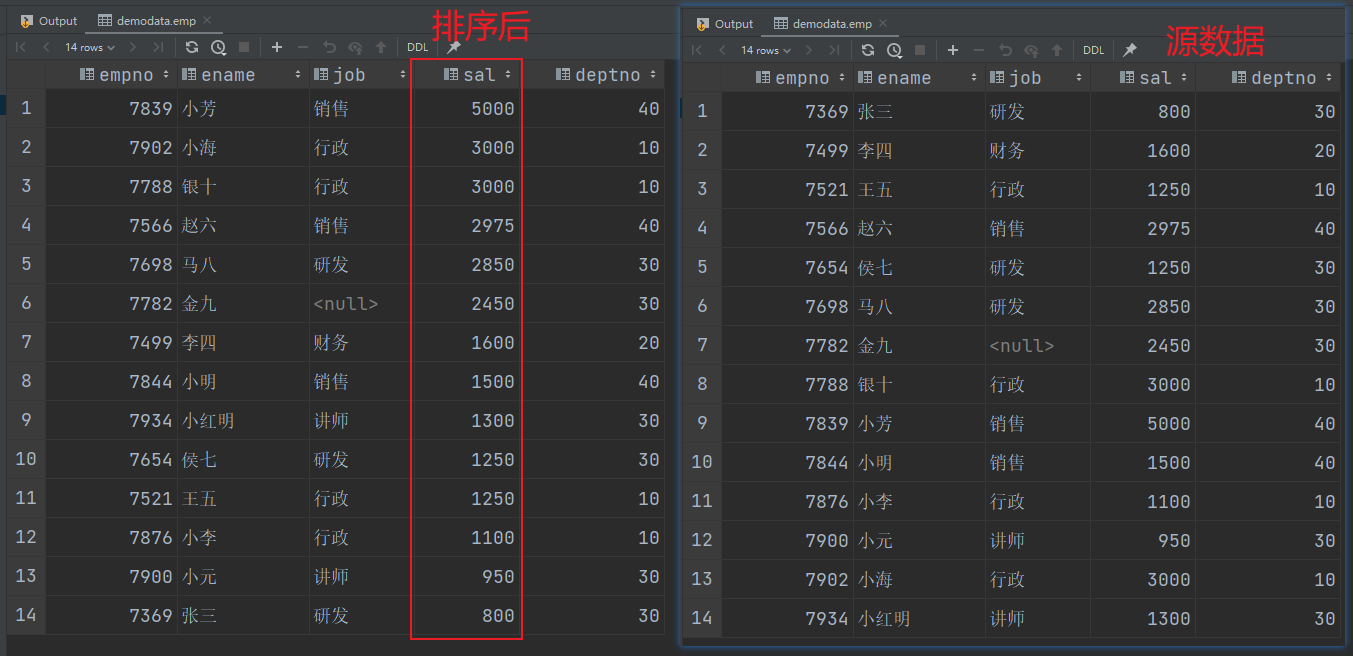
(2)查询员工信息按工资降序排列
select
*
from emp
order by sal desc;
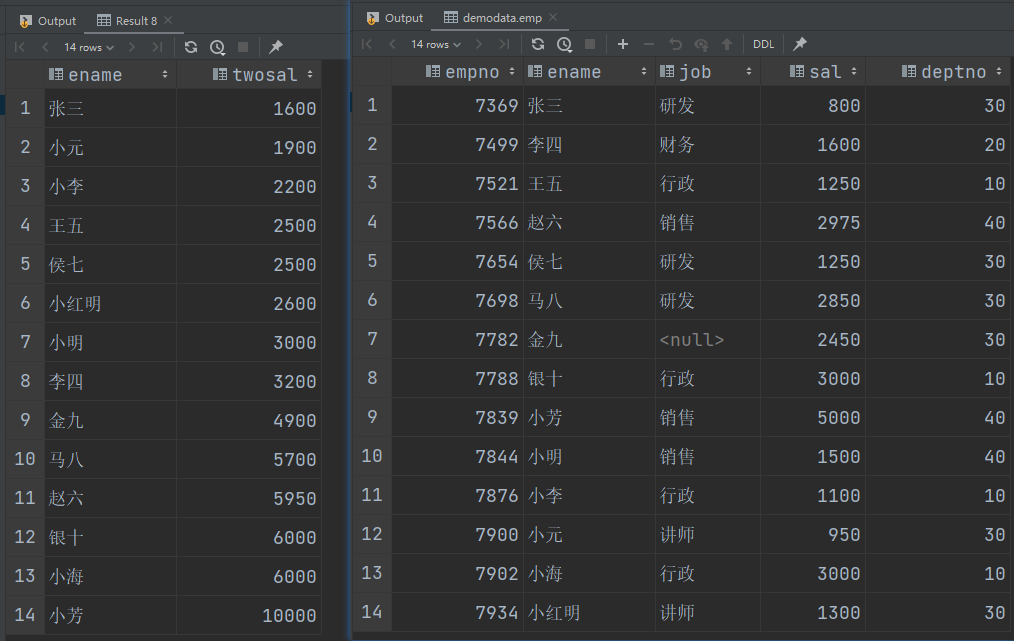
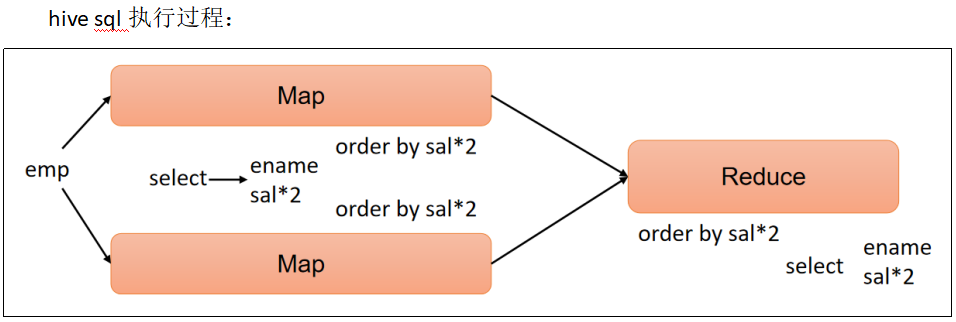
(3)按照员工薪水的2倍排序
select
ename,
sal * 2 twosal
from emp
order by twosal;
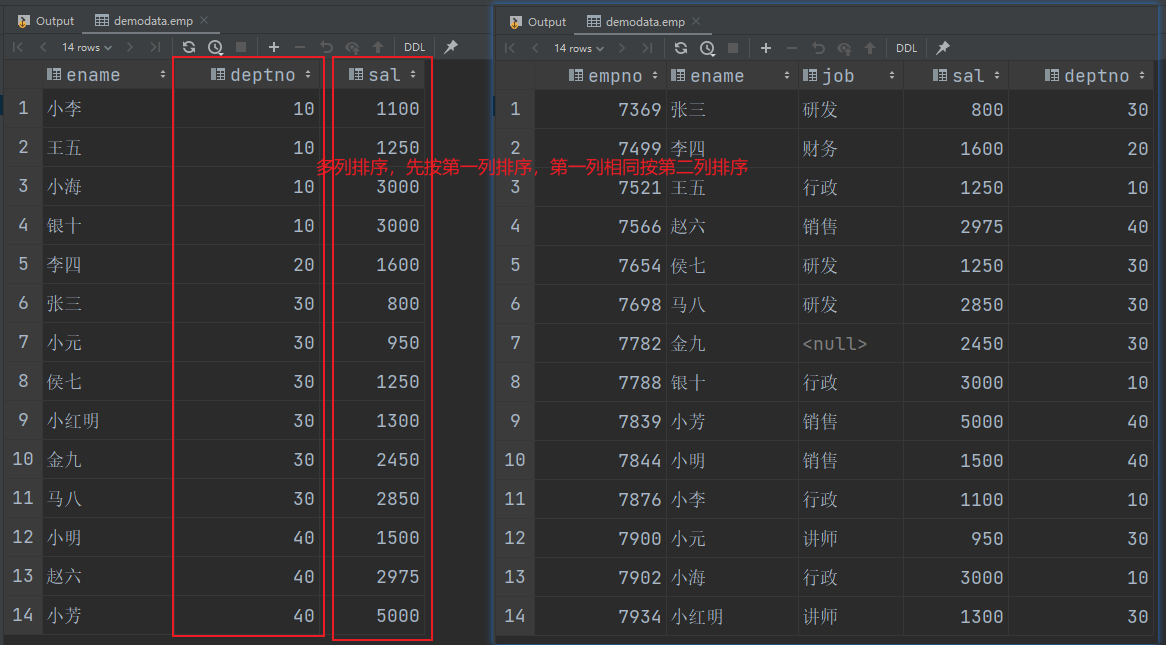
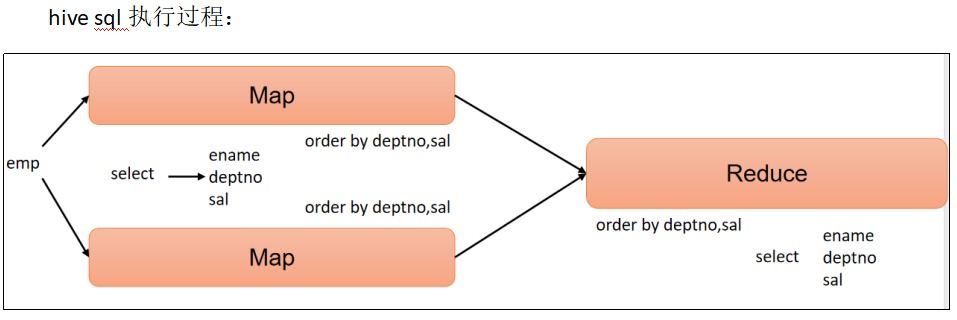
(4) 多个列排序案例实操
按照部门和工资升序排序。
select
ename,
deptno,
sal
from emp
order by deptno, sal;
2 每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用Sort by。
Sort by为每个reduce产生一个排序文件。每个Reduce内部进行排序,对全局结果集来说不是排序。
(1)设置reduce个数
set mapreduce.job.reduces=3;
(2)查看设置reduce个数
set mapreduce.job.reduces;
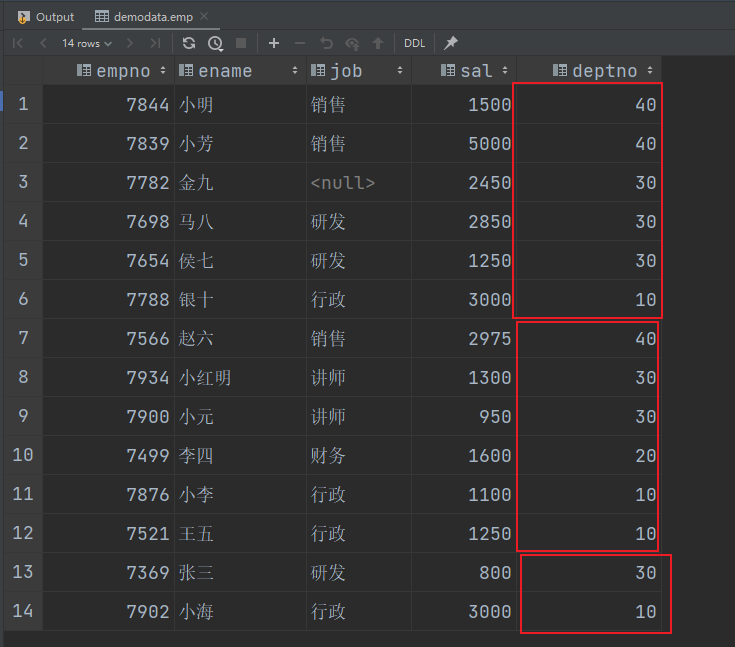
(3)根据部门编号降序查看员工信息
select
*
from emp
sort by deptno desc;
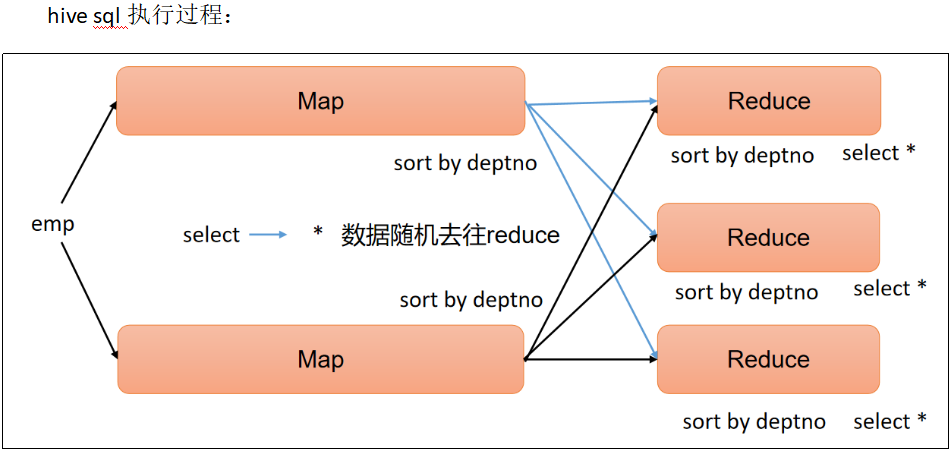
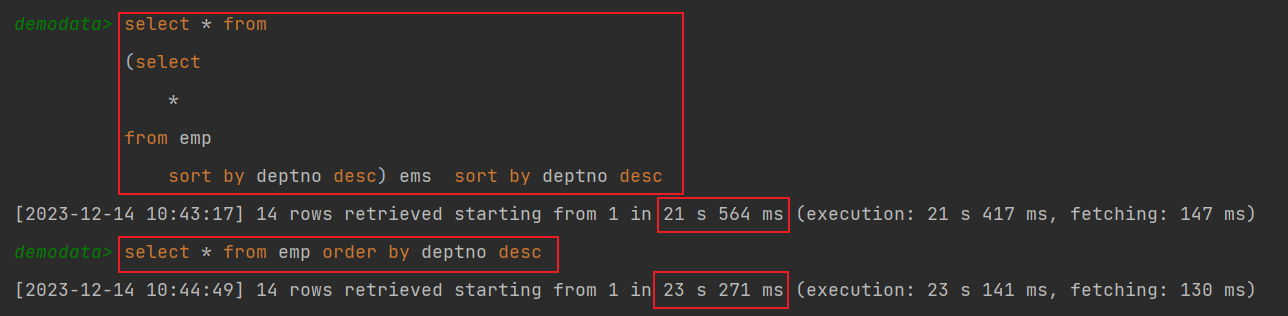
通过两次sort by 排序比一次order by排序执行效率高
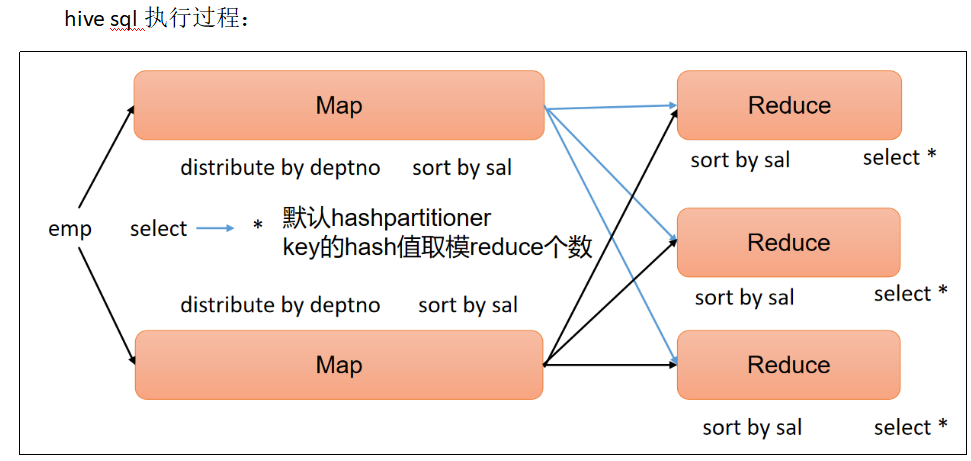
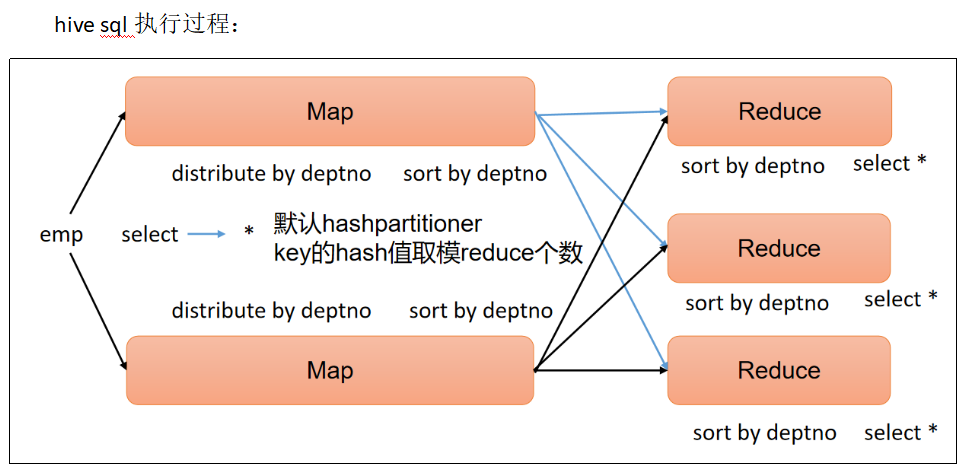
3 分区(Distribute By)
Distribute By:在有些情况下,我们需要控制某个特定行应该到哪个Reducer,通常是为了进行后续的聚集操作。distribute by子句可以做这件事。distribute by类似MapReduce中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
(1)设置reduce个数
set mapreduce.job.reduces=3;
(2)查看设置reduce个数
set mapreduce.job.reduces;
(3) 先按照部门编号分区,再按照员工编号薪资排序
select
*
from emp
distribute by deptno
sort by sal desc;
?distribute by的分区规则是根据分区字段的hash码与reduce的个数进行相除后,余数相同的分到一个区。
?Hive要求distribute by语句要写在sort by语句之前。
?演示完以后mapreduce.job.reduces的值要设置回-1,否则下面分区or分桶表load跑MapReduce的时候会报错。
4 分区排序(Cluster By)
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为asc或者desc。
select
*
from emp
cluster by deptno;
select
*
from emp
distribute by deptno
sort by deptno;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!