使用 GPT4V+AI Agent 做自动 UI 测试的探索
一、背景
从 Web 诞生之日起,UI 自动化就成了测试的难点,到现在近 30 年,一直没有有效的手段解决Web UI测试的问题,尽管发展了很多的 webdriver 驱动,图片 diff 驱动的工具,但是这些工具的投入产出比一直被质疑,自动化率越多维护成本越高,大部分都做着就放弃了,还有一部分在做与不做间纠结。
本文结合一些开源的项目探索使用GPT 自动做 UI 测试的可能性。
二、方案选型
当前UI 的主要问题:一个是通过 Webdriver 控制浏览器执行,这些工具都需要先查找到对应元素的 Elements,无论是录制的还是自己编写的在面对 UI 变化,元素变化时都需要耗费很大的精力去重新识别,解析 Dom 查找,这个工作乏味且没有效率;另一种是通过图像进行点击,比如 Sikuli 这种工具,主要的问题也是复用性较差,换个分辨率的机器或者图片发生少的改动就不可用。
使用 GPT 做 UI 测试尝试了两种方案:
第一种将 Html 元素投喂给 GPT,主要方法获取 Html代码,对 Html 做初步缩减处理,再做向量化,然后喂给 GPT4 自动生成 Webdriver 驱动脚本,效果一般,而且因为 Html 比较大,Token 的消耗很大。
第二种思路是让 GPT 像人一样思考和测试,比如一个人打开一个网页后,他通过眼睛看到的页面文字或图标,然后用手完成点击和输入的操作,最后通过页面的弹窗或者文字来识别是否有错误,这几个动作通过大脑统一协调。
这里主要介绍第二种.
三、新方案实践
1.新方案简介
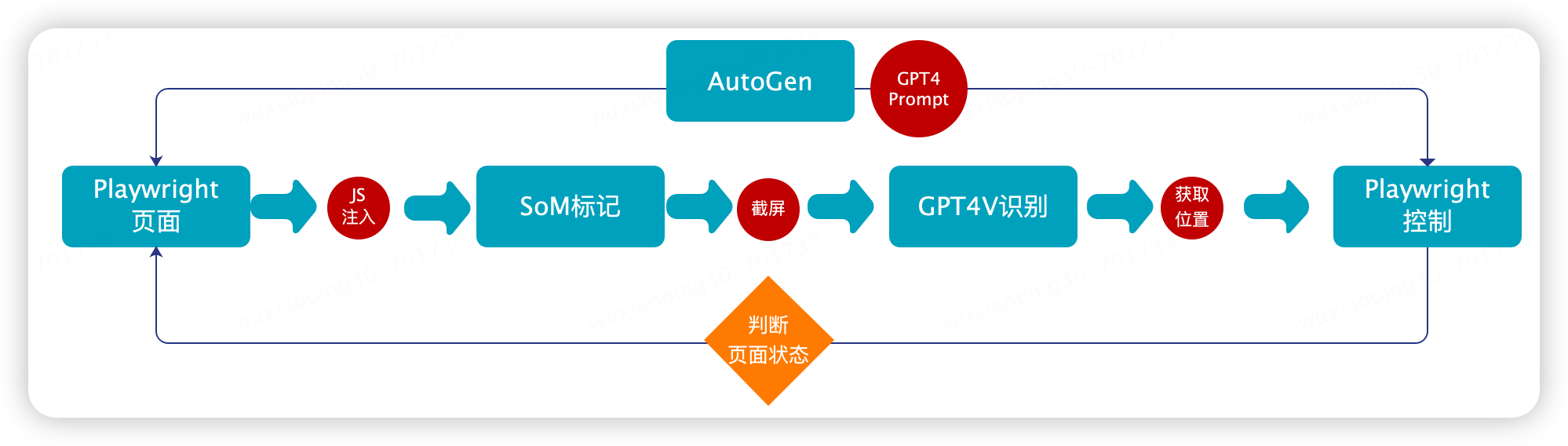
新的方案主要结合 Playwright,SoM视觉标记,GPT4Vison,GPT4,AutoGen来实现。主要的原理
通过 Playwright进行浏览器操作,包括页面图像的获取、浏览器的各种操作,相当于‘‘手’’;
进行SoM 视觉数据标记,因为 GPT4Vison 在进行页面原始识别时并不是很准确,参考微软的论文可以通过视觉标记的手段来辅助 GPT4V 识别,相当于“眼睛”。
通过GPT4+AutoGen 将这些步骤串起来实现协调控制,相当于“大脑”。
2.主要架构
3.实现步骤
3.1 使用 Playwright 注入 JS
browser = playwright.chromium.launch(channel="chrome",headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://oa.jd.com/")
inject_js ="./pagemark.js"
withopen(inject_js,'r')asfile:
content =file.read()
page.evaluate(f"{content}")
3.2 SoM 视觉提示标记
如前文提到的 GPT4V 并不能有效的识别 Web 的元素,所以在使用 GPT4V 之前进行图像标记,图像标记现在有两种方式,一种是通过 AI 识别图片进行标记,这种主要利用在对静态图片图像的识别,对于 Web 页面的标记,我们可以采用注入 JS 修改页面元素的方式来标记。这里通过在浏览器中注入 pagemark.js,利用 Playwright 执行 js 函数来完成页面的标记,该 JS 能够完成标准的coco annotation的标注。
// DOM Labelerlet labels =[];functionunmarkPage(){
for(const label of labels){
document.body.removeChild(label);
}
labels =[];
}
functionmarkPage(){
unmarkPage();
var bodyRect = document.body.getBoundingClientRect();
var items =Array.prototype.slice.call(
document.querySelectorAll('*')
).map(function(element){
var vw = Math.max(document.documentElement.clientWidth ||0, window.innerWidth ||0);
var vh = Math.max(document.documentElement.clientHeight ||0, window.innerHeight ||0);
var rects =[...element.getClientRects()].filter(bb=>{
var center_x = bb.left + bb.width /2;
var center_y = bb.top + bb.height /2;
var elAtCenter = document.elementFromPoint(center_x, center_y);
return elAtCenter === element || element.contains(elAtCenter)
}).map(bb=>{
const rect ={
left: Math.max(0, bb.left),
top: Math.max(0, bb.top),
right: Math.min(vw, bb.right),
bottom: Math.min(vh, bb.bottom)
};
return{
...rect,
width: rect.right - rect.left,
height: rect.bottom - rect.top
}
});
var area = rects.reduce((acc, rect)=> acc + rect.width * rect.height,0);
return{
element: element,
include:
(element.tagName ==="INPUT"|| element.tagName ==="TEXTAREA"|| element.tagName ==="SELECT")||
(element.tagName ==="BUTTON"|| element.tagName ==="A"||(element.onclick !=null)|| window.getComputedStyle(element).cursor =="pointer")||
(element.tagName ==="IFRAME"|| element.tagName ==="VIDEO")
,
area,
rects,
text: element.textContent.trim().replace(/\s{2,}/g,' ')
};
}).filter(item=>
item.include &&(item.area >=20)
);
// Only keep inner clickable items
items = items.filter(x=>!items.some(y=> x.element.contains(y.element)&&!(x == y)))
// Function to generate random colors
functiongetRandomColor(){
var letters ='0123456789ABCDEF';
var color ='#';
for(var i =0; i <6; i++){
color += letters[Math.floor(Math.random()*16)];
}
return color;
}
// Lets create a floating border on top of these elements that will always be visible
items.forEach(function(item, index){
item.rects.forEach((bbox)=>{
newElement = document.createElement("div");
var borderColor =getRandomColor();
newElement.style.outline =`2px dashed ${borderColor}`;
newElement.style.position ="fixed";
newElement.style.left = bbox.left +"px";
newElement.style.top = bbox.top +"px";
newElement.style.width = bbox.width +"px";
newElement.style.height = bbox.height +"px";
newElement.style.pointerEvents ="none";
newElement.style.boxSizing ="border-box";
newElement.style.zIndex =2147483647;
// newElement.style.background = `${borderColor}80`;
// Add floating label at the corner
var label = document.createElement("span");
label.textContent = index;
label.style.position ="absolute";
label.style.top ="-19px";
label.style.left ="0px";
label.style.background = borderColor;
label.style.color ="white";
label.style.padding ="2px 4px";
label.style.fontSize ="12px";
label.style.borderRadius ="2px";
newElement.appendChild(label);
document.body.appendChild(newElement);
labels.push(newElement);
console.log(index)
});
})
}
以某系统为例,标注后的效果如下图:
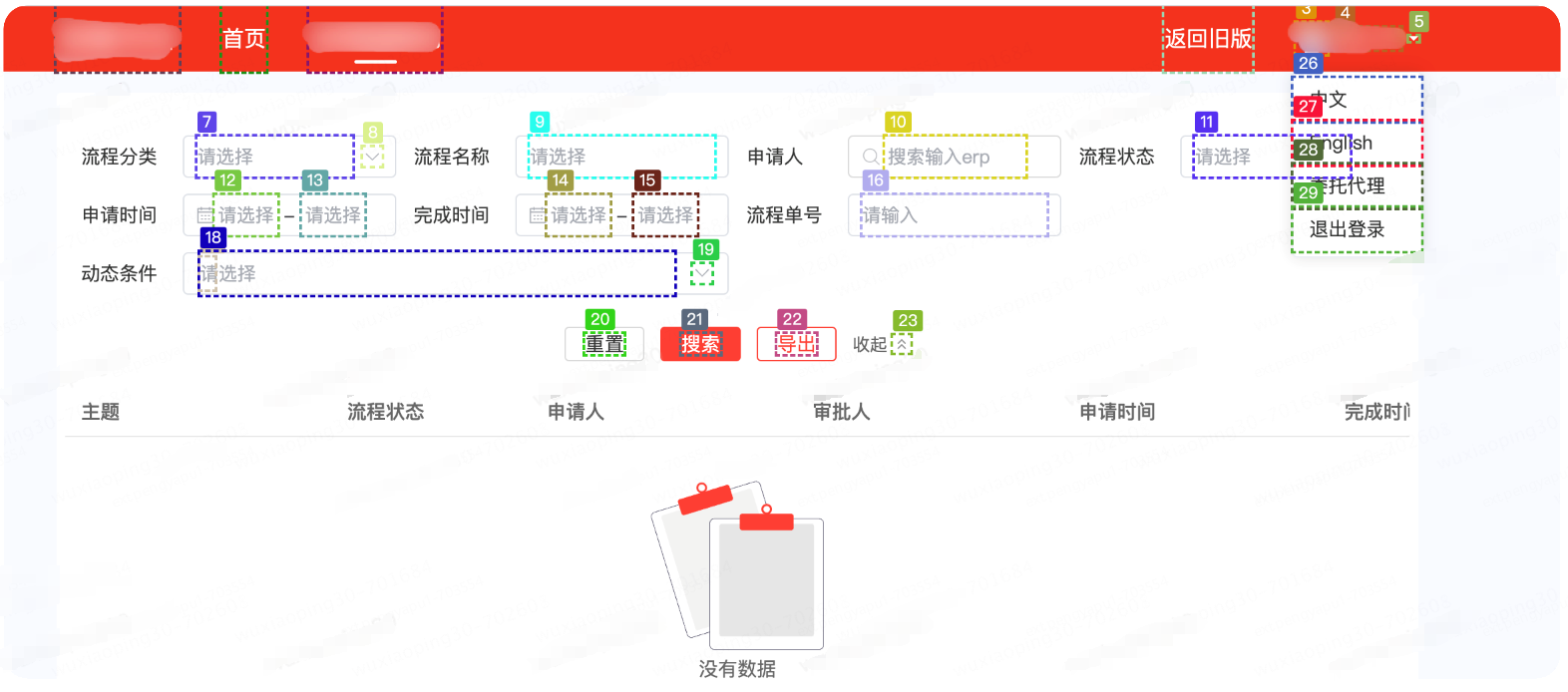
将标记元素的位置编号保存到本地coco.json
{
"1":{"x":"10","y":"40","w":"8","h":"10","center_x":"30","center_y":"13"},
"2":{"x":"20","y":"40","w":"16","h":"10","center_x":"30","center_y":"21"},
"10":{"x":"40","y":"80","w":"16","h":"10","center_x":"80","center_y":"21"}}
其中 center_x, center_y 为元素的中心点坐标
3.3 GPT4V 识别
Prompt
我上传了一张网页截图,页面元素已经使用COCO Annotator进行了数字标记。
请分析这张图片,并识别出网页的用途以及各个标记元素的功能。基于你的分析,请生成一个规划路径来完成以下任务:
- 输入ERP搜索。
- 检查列表是否为空
请使用图片中的数字标记来描述完成任务的具体步骤。
GPT4V Response
这张图片显示的是一个具有多个数字标记的网页截图。根据这些标记,我们可以推测出网页的用途以及各个元素的功能。
为了完成您提出的任务,我们可以按照以下步骤操作:
\n\n1. 使用标记为10的搜索框输入ERP搜索词。这个搜索框的标签显示为“搜索框输入erp”,表明它用于输入搜索词。
\n\n2. 点击标记为17的搜索按钮。这个按钮的标签是“搜索”,表明它用于提交搜索请求。
\n\n3. 检查列表是否为空。这个步骤可能需要查看标记为19的区域,这个区域被标记为“列表内容”,如果这个区域没有显示任何内容或者有提示信息显示列表为空,则说明搜索结果为空。
\n\n以 上步骤基于图片中的数字标记和元素标签来描述完成任务的具体操作。"
提取元素坐标
利用正则表达式从GPT4V 的 response 中提取查询到的元素的 bbox id= 10,17,19, 结合在 SoM 标记中记录的 json 文件,找到编号 10 的元素坐标"10":{"x":"40","y":"80","w":"16","h","10","center_x":"80","center_y":"21"}
class GPT4VRecognize
def get_location(self, query):
coco_json='./coco.json'
withopen(coco_json,'r') as file:
content =file.read()
matches=re.findall(r'\d+',gpt4v_response_content)
num=-1
iflen(matches)>0:
num=matches[0]
data = json.loads(json_str)
center_x = data[num]["center_x"]
center_y = data[num]["center_y"]
return center_x,center_y
3.4 Playwright操作页面
Playwright是一个非常强大的操作浏览器的工具,这里因为前面已经通过 GPT4V 识别了图片,所以我们主要通过 坐标 的方式来控制元素,不再需要解析Dom 来控制,主要的包括,点击,双击,鼠标拖动,输入,截图等:
class Actions:
page=None
__init__(self,url):
global page
browser = playwright.chromium.launch(channel="chrome",headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://oa.jd.com/")
def mouse_move(self,x,y):
page.mouse.move(self,x,y)
def screenshot(self):
page.screenshot()
def mouse_click(self,x,y):
page.mouse.click(self,x,y)
def input_text(self,x,y,text):
page.mouse.click(self,x,y)
page.keyboard.type(text)
def mouse_db_click(self,x,y):
def select_option(self,x,y,option):
......
3.5 使用 AutoGen编排
AutoGen是一个代理工具,它能够代理多个 LLM在不同会话间切换,能够自动的调用预定的函数,并协调这些 LLM 完成任务。
在上面的程序中,实现了:眼睛:通过 GPT4V 来识别元素;手:通过 Playwright 来做各种操作;后面需要通过一个大脑来协调手、眼完成任务,这里通过 GPT4+AutoGen 来实现大脑的协同调度。
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST")
assistant= autogen.AssistantAgent(
name="assistant",
system_message=
"""
You are the orchestrator responsible for completing a task involving the UI window.
Utilize the provided functions to take a screenshot after each action.
Remember to only use the functions you have been given and focus on the task at hand.
""",
llm_config={"config_list": config_list},
)
user_proxy = autogen.UserProxyAgent(
name="brain_proxy",
human_input_mode="NEVER",
code_execution_config={"work_dir":"coding"},
max_consecutive_auto_reply=10,
llm_config={"config_list": config_list},)
action = Actions(url)
gpt4v=GPT4VRecognize()
user_proxy.register_function(
function_map={
"get_location": gpt4v.get_location,
"mouse_move":action.mouse_move,
"screenshot":action.screenshot,
"mouse_click":action.mouse_click,
"mouse_dbclick":action.mouse_dbclick,
"select_option":action.select_option
})
def run(message_ask):
user_proxy.initiate_chat(assistant,message=message_ask)
if __name__ =="__main__":
run("通过 输入erp 'wwww30' 搜索结果,并检查是否返回空列表")
四、问题和后续
1.当前的主要问题
本文主要抛砖引玉,通过一种完全按人类思维进行 UI测试的方式,在实验过程中还有很多问题待解决。
- GPT 在中文语境下识别的不太友好,在实验过程中对中文的 prompt 理解有误,需要不断的优化 prompt,尤其是页面中的中文元素。
- AutoGen 对于处理预定义的动作也会有问题,需要不断调优。
- GPT4V 真的很贵。
2.未来的想法
- 将每次向 GPT4V请求的图像识别做本地化处理,结合现有的一些测试方法,从而减少 Token,缩短执行耗时。
- 面向业务的 GPT需要不断训练,将系统使用手册和一有的 PRD 文档投喂给 GPT,增强 gpt 的系统识别和测试能力。
Python接口自动化测试零基础入门到精通(2023最新版)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!