用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
之前写了一篇文章介绍基于 LangChain 和 ChatGLM 打造自有知识库问答系统,最近该项目更新了0.2新版本,这个版本与之前的版本差别很大,底层的架构发生了很大的变化。
该项目最早是基于 ChatGLM 这个 LLM(大语言模型)来搭建的,但后来集成的 LLM 越来越多, 我估计项目团队也借此机会将项目名称改成了Langchain-Chatchat。版本更新之后,项目的部署方式也发生了变化,之前的部署方式已经不适用了,这里我将介绍一下新版本的部署方式。
机器配置
项目的部署需要一台 GPU 服务器,不管是云服务器还是本地服务器都可以,但是需要注意的是,服务器至少需要16G 的显存,太低的话项目会运行不起来。
关于云 GPU 服务器的选择可以参考我之前的文章这里不再赘述。
我选择的是在 AutoDL 服务器上部署。
通俗易懂讲解大模型系列
- 用通俗易懂的方式讲解大模型:使用 Docker 部署大模型的训练环境
- 用通俗易懂的方式讲解大模型:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
- 用通俗易懂的方式讲解大模型:Llama2 部署讲解及试用方式
- 用通俗易懂的方式讲解大模型:LangChain 知识库检索常见问题及解决方案
- 用通俗易懂的方式讲解大模型:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
- 用通俗易懂的方式讲解大模型:代码大模型盘点及优劣分析
- 用通俗易懂的方式讲解大模型:Prompt 提示词在开发中的使用
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

项目更新内容
Langchain-Chatchat 项目的更新内容可以参考这里[3],主要有以下几点:
使用 FastChat 提供开源 LLM 模型的 API
FastChat[4]是一个用于训练和评估遵循指令 LLM 的框架,可以将 LLM 部署为带有标准应用程序编程接口(API)的软件服务。
这个改动带来的最大变化就是,原来是部署 1 个服务(WebUI),现在需要部署 3 个服务,分别是 LLM API 服务、 Langchain Chatchat 本身的 API 服务和 WebUI 服务,这样的好处是可以将原先的内部服务都解耦出来,用户可以选择不同的服务来构建自己的应用。比如你的项目只需要用到 LLM,那么你只需要部署 LLM API 服务就可以了;或者是你想用自己的前端服务,那么你只需要部署 2 个 API 服务,然后自己写一个前端服务就可以。
接口参数根据 OpenAI API 接口形式接入
接口参数根据 OpenAI API 接口形式接入,让请求参数更加合理。比如以前对话 API 中的对话历史参数是一个二维数组,跟我们熟悉的 OpenAI API 参数差别很大,可以看下面的例子:
# 原 Langchain ChatGLM 的对话历史参数
history: [["你好", "你好,有什么可以帮到你"], ["1 加 1 等于几", "2"]]
# OpenAI 的对话历史参数
messages: [{ "role": "user", "content": "你好" }, { "role": "assistant", "content": "你好,有什么可以帮到你" }]
# 新版 Langchain Chatchat 的对话历史参数
history: [{ "role": "user", "content": "你好" }, { "role": "assistant", "content": "你好,有什么可以帮到你" }]
可以看到原来的参数形式是一个二维数组,每轮对话都会放到一个子数组中,包含用户和 AI 的对话信息,而 OpenAI 的参数形式是一个对象数组,每个对象包含对话的角色和对话的内容,这样的数据结构程序会更容易处理,新版的参数形式改成了 OpenAI 的这种形式,虽然字段名有些不一样。
使用 Streamlit 提供 WebUI 服务
原先是用Gadio来编写 WebUI 页面的,现在改成了Streamlit,Streamlit提供了创建更复杂应用程序的能力,而且它提供了丰富的组件库,并支持自定义组件,可以看到新版的页面更加美观。
项目中默认 LLM 模型改为 CHATGLM2-6B
原来默认用的 LLM 是 ChatGLM-6B,现在改成了 ChatGLM2-6B,ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,增加了更强大的性能,更长的上下文,更高效的推理和更开发的协议。
默认 Embedding 模型改为 M3E-BASE
原来的 Embedding 模型是 GanymedeNil/text2vec-large-chinese[5],现在改成了moka-ai/m3e-base[6],TEXT2VEC 和 M3E-BASE 都支持中文,但 M3E-BASE 对英文的支持更好,文件加载方式与文段划分方式也有调整,后续将重新实现上下文扩充,并增加可选设置。
项目部署
下面我们开始来部署 Langchain-Chatchat 项目。
项目初始化
下载项目代码,同时安装依赖,注意新版的依赖文件有 3 个,一个是 API 服务的依赖文件 requirements_api.txt,一个是 WebUI 服务的依赖文件 requirements_webui.txt,还有一个是整个项目的依赖文件 requirements.txt,因为我们前后端都要部署,所以我们要用整个项目的依赖文件来安装依赖:
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
cd Langchain-Chatchat
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple # 照例加上百度源提高下载速度
如果是第一次运行本项目,需要通过以下命令来初始化知识库:
$ python init_database.py --recreate-vs
模型下载
下载 ChatGLM2-6B 和 M3E-BASE 模型,这两个模型都在 HuggingFace 上,可以直接克隆仓库:
# 开启大文件下载
git lfs install
# 下载 ChatGLM2-6B
git clone https://huggingface.co/THUDM/chatglm2-6b
# 下载 M3E-BASE
git clone https://huggingface.co/moka-ai/m3e-base
项目配置修改
模型下载完成后接着修改配置文件,新版的项目提供了一个配置文件模板model_config.py.example文件,需要将其复制一份并重命名为model_config.py,然后修改里面的配置项:
cd Langchain-Chatchat
cp configs/model_config.py.example configs/model_config.py
然后修改model_config.py文件中的配置项,将模型的路径改成你自己的路径:
embedding_model_dict = {
- "m3e-base": "moka-ai/m3e-base",
+ "m3e-base": "/你的下载路径/m3e-base",
llm_model_dict = {
"chatglm2-6b": {
- "local_model_path": "THUDM/chatglm2-6b",
+ "local_model_path": "/你的下载地址/chatglm2-6b",
LLM API 服务部署
执行以下命令启动 LLM API 服务:
python server/llm_api.py
注意: llm_api.py 中的openai_api_port端口要和configs/model_config.py中 LLM 的服务端口保持一致,否则接口调用会报错。另外如果你是在 AutoDL 的服务器上部署的话,服务器的8888端口会被Juypter服务占用,建议改成其他端口,代码实例如下:
# llm_api.py
openai_api_port = 7777 # 如果你是用AutoDL服务器的话,这个端口不要用8888
# configs/model_config.py
"chatglm-6b": {
"local_model_path": "/你的下载地址/chatglm-6b",
"api_base_url": "http://localhost:7777/v1", # 这里的端口要和上面的openai_api_port保持一致
"api_key": "EMPTY"
},
服务启动后,实际会启动 3 个子服务,端口分别是8888(上面我们改成了7777)、20001、20002,其中8888端口的服务是 LLM 的接口服务,里面提供了文本推理、embedding、token 检查等接口,跟 OpenAI 的接口十分相似。其他 2 个端口的服务我理解是对 LLM 服务的一些监控和管理。
如果启动服务后发现调用接口异常,可以在本地通过 curl 命令对8888端口的服务进行测试。
API 服务部署
执行以下命令启动 API 服务:
python server/api.py
这个服务主要提供了 Langchain Chatchat 的功能接口,包括 LLM 问答、知识库问答、知识库管理等接口。同样地,我们也可以通过 curl 命令对该服务进行测试,服务的端口默认是 7861。
WebUI 服务部署
最后是启动 WebUI 服务,执行以下命令启动 WebUI 服务,默认的端口号是8501,可以通过--server.port参数来修改端口:
streamlit run webui.py --server.port 6006
我在启动 WebUI 服务时还遇到一个问题,就是启动服务时报了protobuf这个依赖包版本不对的错误,导致 Web 服务启动失败,后面我将protobuf的版本降级成了3.20.3就可以正常启动了。
启动后可以通过浏览器访问 WebUI 服务,界面如下所示:
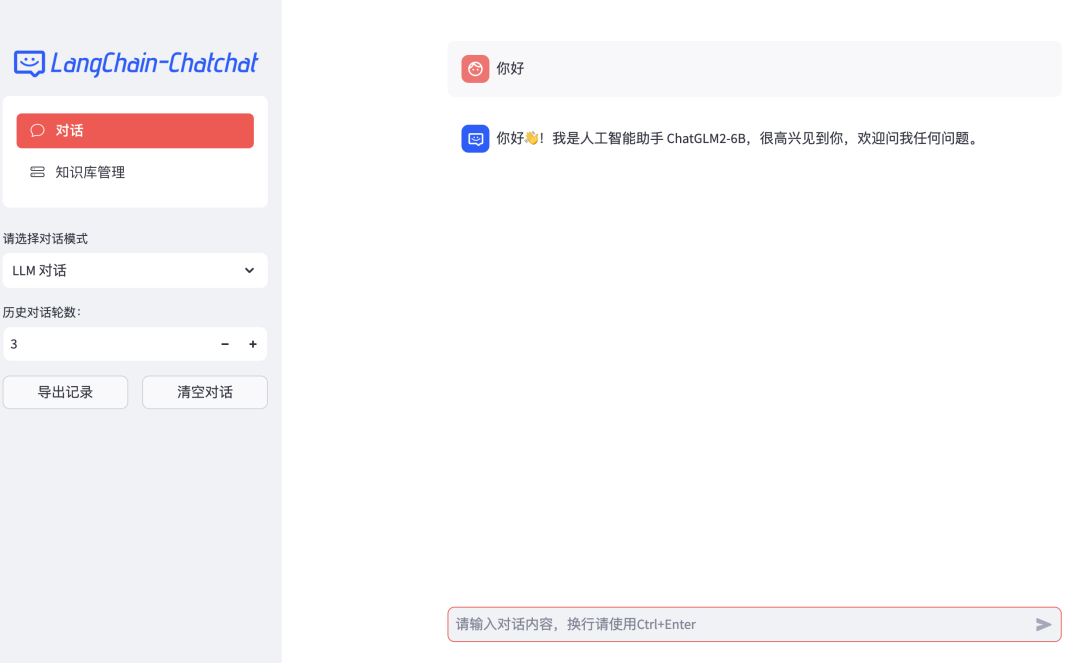
其他未测试的部署方式
因为项目新版本才刚发布,我还没有对所有部署方式进行试用,比如对于 API 服务,除了单独启动服务外,还有一个api_allinone.py的文件,我理解是用来同时启动 LLM API 服务和 API 服务的。还有一个webui_allinone.py的文件,应该是用来同时启动所有服务的。这些功能可以让我们更加方便的部署项目,大家可以自行验证这些部署方式。
由于新版本刚发布,新版本的功能可能存在不少问题,在项目的 issue 区可以看到大量新版本的问题,包括服务启动不起来,或者是启动起来之后 Web 页面没有反应等问题,这些问题应该都是可以解决的,只是需要再给项目团队一些时间。
总结
AI 知识库问答系统是一个很有前景的方向,它是对传统知识库系统的一种升级,相信在未来会有很多垂直领域的公司会用到这个技术。从 Langchain Chatchat 项目的发展过程上来看,项目从原来的一个 demo 级别的项目,逐渐向一个完整的产品迈进,在架构、UI 界面、LLM 集成方面也在不断完善,我相信这是一个未来可期的项目。而对于那些还在用老版本的小伙伴,建议尽快升级到新版本,因为项目团队以后的主要精力都会放在新版本的开发上,老版本的功能可能不会再更新了。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[3] https://github.com/chatchat-space/Langchain-Chatchat/releases/tag/v0.2.0_
[4]FastChat: https://github.com/lm-sys/FastChat
[5]GanymedeNil/text2vec-large-chinese: https://huggingface.co/GanymedeNil/text2vec-large-chinese
[6]moka-ai/m3e-base: https://huggingface.co/moka-ai/m3e-base
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!