一次 CPU 占用率过高的问题排查 (不断创建线程和线程上下文频繁切换)
1 背景

如图是生产中系统的架构图
- 主服务会在核心表数据变更后, 将变更记录的数据推送到 MQ
- 下游有不同的业务系统, 订阅了对应的 MQ 消息
而本人负责的服务 A 在消费消息时, 有以下的特点
- 上游推送的数据有不同的业务类型和不同的状态值
- 不同的业务类型的数据只有在达到某个指定状态前, 才需要处理
比如某条记录有个业务类型, 取值为 A, B, C, 同时有 1 个状态值 X, Y, Z, 当业务类型为 A 的记录, 只有在 Y 状态, 才需要处理。
这个特点决定了上游推送的消息, 在服务 A 是暂时不关心的 (但是这些消息对于其他的业务系统, 却是关心的, 所以上游不会停止推送), 消费这些消息很浪费服务 A 的资源 (上游的数据变更推送每日的数据量在亿级别, 高峰 QPS 可达到 2000 以上),
为了不影响调用服务 A 的其他服务和用户的正常使用, 决定主服务和服务 A 中间加多一个过滤服务, 将原本服务 A 的过滤逻辑迁移到这个服务中, 新的架构图如下:
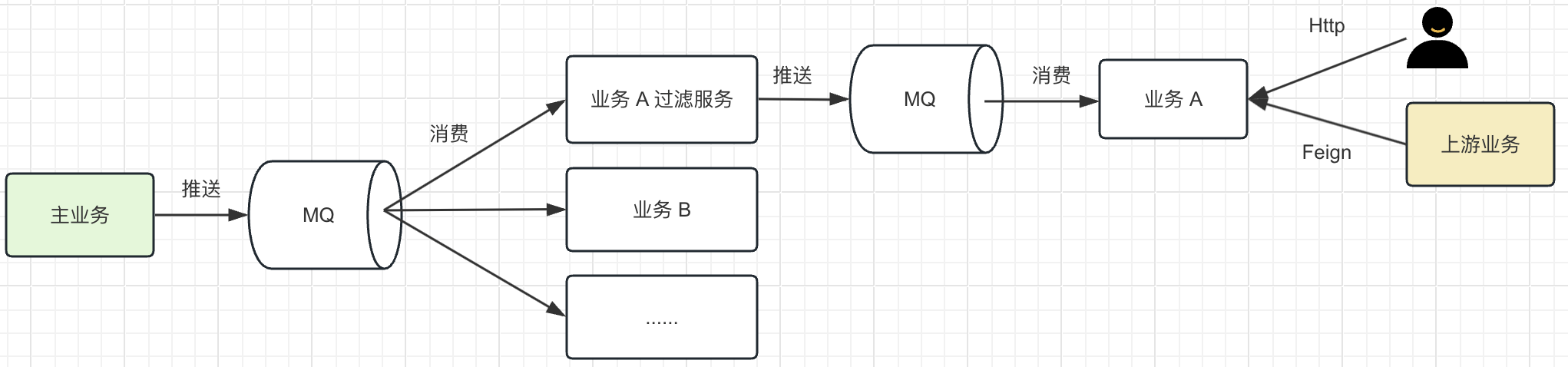
由过滤服务直接对接到主服务的 MQ 消息, 对消息进行过滤服务条件的在通过 MQ 推送给下游的服务 A。
经过改造后, 过滤服务部署到生产, 但是每次部署上去后, 没过多久, 就频繁的提示 CPU 占用率过高的告警, 不得不进行排查。
2 结论
按照惯例, 先把结论整理一下, 经过排查, 后面导致 CPU 占用率过高的原因, 有 2 个
- 没有经过任何配置, 通过 SpringBoot 的 @Async 进行异步, 导致应用一直在创建线程, 销毁线程
- 高频的打印日志, 日志内部有个锁, 导致线程频繁地进行上下文切换, 消耗 CPU 资源
3 过程
3.1 告警
过滤服务预发验收没问题后, 逐步切流量进入过滤服务, 但是在流量切完, 几分钟后, 触发告警 xxx 服务 CPU 超过警戒线, 当前 CPU xxx。
打开 Grafana 进行查看, 发现几个实例 CPU 都在 150% 以上, 看起来不是某个特例触发了什么 bug。
3.2 异常线程发现
- 先获取一下当前 Java 程序的进程 Id
jps -l
- 查看应用当前的线程栈信息
jstack 上一步获取到的进程 Id
通过观察基本线程都是 RUNNABLE, 初步看不出是什么问题。
- 多次导出线程栈信息, 进行比较
jstack 上一步获取到的进程 Id >> stack-1.txt
将当前应用的线程栈信息导出到 stack-1.txt 文件, 然后隔几秒, 再导出一次到 stack-2.txt, 重复 3 次。
此时本地有 3 个线程栈信息 stack-1.txt, stack-2.txt, stack-3.txt, 对三个文件的堆栈信息进行对比分析。
stack-1 文件内容
"SimpleAsyncTaskExecutor-1" #182 daemon prio=5 os_prio=31 tid=0x00007f93aeaa0000 nid=0x1b203 runnable [0x0000000314bbd000]
省略
"MqConsumer-1" #104 daemon prio=5 os_prio=31 tid=0x00007f93b12c6800 nid=0xf203 runnable [0x000000030fcd4000]
省略
"Reference Handler" #2 daemon prio=10 os_prio=31 tid=0x00007f939e80b800 nid=0x4723 in Object.wait() [0x000000030a6c7000]
省略
"VM Thread" os_prio=31 tid=0x00007f93ae020800 nid=0x4803 runnable
"GC task thread#0 (ParallelGC)" os_prio=31 tid=0x00007f93b0809000 nid=0x524f runnable
省略
通过第一个文件 stack-1.txt 整体的线程可以分为 3 组
- SimpleAsyncTaskExecutor-x SpringBoot 异步处理任务的线程
- MqConsumer-x 消费 MQ 消息的线程
- 其他
查看第二个文件 stack-2.txt, 发现以 SimpleAsyncTaskExecutor 开头的线程有好几个消失了, 但是多了几个新的以 SimpleAsyncTaskExecutor 开头的线程, 就是编号不一致。
通过堆栈信息, 发现他们是使用 @Async 注解的异步处理方法, 怀疑是不是一直在创建线程处理任务, 任务处理完成就释放。
- 在对应的方法处, 打一个断点, 启动项目, 调用这个方法

如图, 这样就能获取整个线程栈信息, 通过线程栈查看。 按照我们怀疑的地方, 找到提交任务的地方, 也就是 org.springframework.aop.interceptor.AsyncExecutionAspectSupport#doSubmit。
发现线程池是有参数传入的, 那么继续往前走, 也就是 org.springframework.aop.interceptor.AsyncExecutionInterceptor#invoke, 在里面获取线程池的方法如下
@Nullable
protected AsyncTaskExecutor determineAsyncExecutor(Method method) {
// 在缓存 Map 中获取异步方法, 执行对应的线程池
// Map<Method, AsyncTaskExecutor> executors
AsyncTaskExecutor executor = (AsyncTaskExecutor)this.executors.get(method);
// 1. 在缓存中获取不到
if (executor == null) {
// 1.1 获取当前方法上面的 @Async 注解里面的 value 值 (可以通过这个指定异步方法执行的线程池)
String qualifier = this.getExecutorQualifier(method);
Executor targetExecutor;
if (StringUtils.hasLength(qualifier)) {
// 1.1.1 从当前的 Spring 容器中获取 @Async 指定名称的线程池
targetExecutor = this.findQualifiedExecutor(this.beanFactory, qualifier);
} else {
// 1.1.2 没有 @Async 或 @Async 没有配置 value 值
// 在声明 AsyncExecutionAspectSupport 时, 可以设置一个默认的线程池, 存放在 defaultExecutor 这个属性
// 一般我们也不会自己主动去声明 AsyncExecutionAspectSupport, 所以这个 defaultExecutor 为空
targetExecutor = this.defaultExecutor;
// 1.1.3 获取不到默认配置的线程池
if (targetExecutor == null) {
synchronized(this.executors) {
if (this.defaultExecutor == null) {
// 1.1.4 通过 getDefaultExecutor 方法获取执行线程池
this.defaultExecutor = this.getDefaultExecutor(this.beanFactory);
}
targetExecutor = this.defaultExecutor;
}
}
}
// 1.2 经过尝试还是获取不到对应的执行线程池
if (targetExecutor == null) {
return null;
}
executor = targetExecutor instanceof AsyncListenableTaskExecutor ? (AsyncListenableTaskExecutor)targetExecutor : new TaskExecutorAdapter(targetExecutor);
// 1.3 保存缓存
this.executors.put(method, executor);
}
// 2. 缓存中获取到, 直接返回
return (AsyncTaskExecutor)executor;
}
protected Executor getDefaultExecutor(@Nullable BeanFactory beanFactory) {
// 调用父类的 getDefaultExecutor 获取线程池
Executor defaultExecutor = super.getDefaultExecutor(beanFactory);
// 父类获取不到线程池, 那么就默认为 SimpleAsyncTaskExecutor
return (Executor)(defaultExecutor != null ? defaultExecutor : new SimpleAsyncTaskExecutor());
}
@Nullable
protected Executor getDefaultExecutor(@Nullable BeanFactory beanFactory) {
if (beanFactory != null) {
try {
// 1. 在当前的 Spring 容器中获取 TaskExecutor 的实例
return (Executor)beanFactory.getBean(TaskExecutor.class);
} catch (NoUniqueBeanDefinitionException var6) {
this.logger.debug("Could not find unique TaskExecutor bean", var6);
// 2. 获取到了多个, 尝试获取名称为 taskExecutor 的 Executor 实例
try {
return (Executor)beanFactory.getBean("taskExecutor", Executor.class);
} catch (NoSuchBeanDefinitionException var4) {
if (this.logger.isInfoEnabled()) {
this.logger.info("More than one TaskExecutor bean found within the context, and none is named 'taskExecutor'. Mark one of them as primary or name it 'taskExecutor' (possibly as an alias) in order to use it for async processing: " + var6.getBeanNamesFound());
}
}
} catch (NoSuchBeanDefinitionException var7) {
this.logger.debug("Could not find default TaskExecutor bean", var7);
try {
// 3. 尝试获取名称为 taskExecutor 的 Executor 实例
return (Executor)beanFactory.getBean("taskExecutor", Executor.class);
} catch (NoSuchBeanDefinitionException var5) {
this.logger.info("No task executor bean found for async processing: no bean of type TaskExecutor and no bean named 'taskExecutor' either");
}
}
}
return null;
}
上面的获取线程池的逻辑概括为
- 从 Spring 容器中获取 TaskExecutor 的实例, 获取到唯一一个, 那么就用这个执行这个异步方法
- 从 Spring 容器中获取 TaskExecutor 的实例有多个或一个都没有, 在从容器中尝试获取 bean 名为 taskExecutor 的 Executor 的实例, 获取到就用这个执行这个异步方法
- 兜底方法, 通过 SimpleAsyncTaskExecutor 这个线程池执行异步方法
- 补充一点, 如果项目没有通过 @EnableAsync 注解启动异步功能的话, @Async 是不会其作用的
在整个 SpringBoot 项目中如果没有创建 TasekExecutor 的实例或名为 taskExecutor 的 Executor 实例, 那么就会用 SimpleAsyncTaskExecutor 执行异步任务 (本文的情况)。
而 里面执行任务的逻辑如下
protected void doExecute(Runnable task) {
// 通过线程工程创建一个线程, 执行任务 (这里 2 处都是通过线程工程创建线程, 区别是一个用用户指定的线程工厂, 一个内置默认的线程工厂)
Thread thread = this.threadFactory != null ? this.threadFactory.newThread(task) : this.createThread(task);
thread.start();
}
到了这里, 大体可以确定问题了
- 每消费一条 MQ 消息的过程中, 都会创建一个线程去处理一部分逻辑
- 上游并发的推送消息, 导致下游一直在创建线程和销毁线程, 消耗大量的 CPU 资源
本地尝试模拟不断创建线程和消耗线程的情况
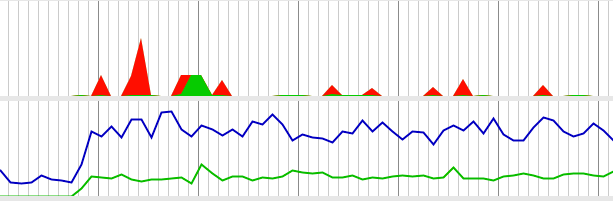
绿色的线条是应用本身的 CPU 情况, 而蓝色的的是整个系统的 CPU 情况, 这个频繁创建和消耗线程的操作消耗了 30% 以上的 CPU。
至于解决方法, 就在上面获取线程池的逻辑里面, 自己定义了一个 TaskExecutor 的线程池, 并交给 Spring 容器即可。
3.3 线程上下文频繁切换发现
通过自定义线程池解决频繁创建线程的问题, 修改好代码后, 重新发布上线, 本以为解决了。
但是没过多久, 告警 xxx 服务 CPU 超过警戒线, 当前 CPU xxx 还是没有消失。
通过
top -Hp 进程 Id
观察, 占用高 CPU 的线程 Id 一直在变化, 不是固定的几个。
再次通过 jstack, 获取线程栈信息, 通过观察, 发现少量的线程是 RUNNABLE 状态, 业务相关的就一个线程在输出日志,
很多线程都是 WAITING 状态, 线程栈都是很一致的在输出日志的地方阻塞住了。
"MqConsumer-2" #178 daemon prio=5 os_prio=31 tid=0x00007f93aea9f800 nid=0x1ac03 waiting on condition [0x00000003147b2000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006c0142820> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at ch.qos.logback.core.OutputStreamAppender.writeBytes(OutputStreamAppender.java:197)
at ch.qos.logback.core.OutputStreamAppender.subAppend(OutputStreamAppender.java:231)
at ch.qos.logback.core.OutputStreamAppender.append(OutputStreamAppender.java:102)
at ch.qos.logback.core.UnsynchronizedAppenderBase.doAppend(UnsynchronizedAppenderBase.java:84)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:51)
at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:270)
at ch.qos.logback.classic.Logger.callAppenders(Logger.java:257)
at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:421)
at ch.qos.logback.classic.Logger.filterAndLog_1(Logger.java:398)
at ch.qos.logback.classic.Logger.info(Logger.java:583)
通过堆栈信息定位到 ch.qos.logback.core.OutputStreamAppender.writeBytes 处
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
// 此处加锁, 会导致线程挂起
lock.lock();
try {
// 日志写入
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();
}
} finally {
lock.unlock();
}
}
到这里已经有个推测了, 线程基本都是阻塞状态, 但是 CPU 很高, 有可能是线程频繁地上下文切换导致的 (日志的打印挺快的, 忽略这操作, 每个线程可以看做是在获取锁,释放锁的过程)。
线程上下文切换导致 CPU 升高的分析, 可以看一下这篇文章。
而根据堆栈信息都是在日志处阻塞的, 应该是上游打印日志太过频繁了 (新上的项目, 为了方便定位问题, 输出了很多日志)。
为了验证这个可能, 删除部分无用的日志, 在几个高频的日志打印处, 加上一个开关
if (logSwitch) {
log.info();
}
然后通过 Apollo 控制这个开发, 重新发布项目到生产。
开关依旧是打开状态, CPU 依旧是在升高, 通过 Apollo 将开关关闭, 停止高频日志的打印, 没过多久日志顺利下降, 验证了猜想。
4 总结
至此, 整个 CPU 占用率高的排查过程就结束了, 后面再对整个过程做个总结
- 通过比较线程栈的信息, 定位到了 @Async 注解的实现中, 通过不断创建线程执行任务的, 这个行为会导致 CPU 消耗资源在重量级对象 Thread 的创建和消毁中
- 第二次通过观察线程栈信息, 定位到大量的线程阻塞在日志输出处, 执行的任务也是在输出日志, 猜测是频繁的日志打印, 导致线程上下文切换, 通过减少日志打印进行验证结论
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!