异步优势演员-评论家算法 A3C
异步优势演员-评论家算法 A3C
?
异步优势演员-评论家算法 A3C
A3C 在 A2C 基础上,增加了并行训练(异步)来提高效率。
网络结构
A2C:
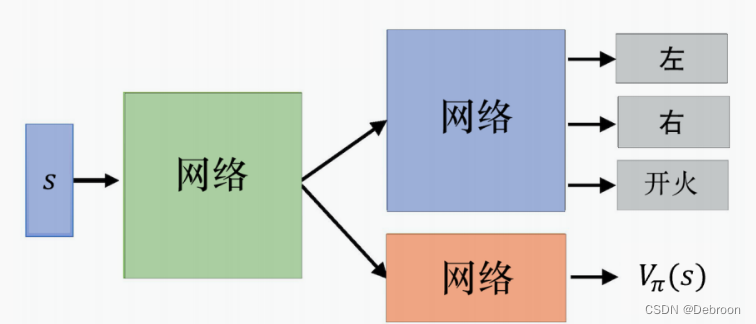
A3C:

在这两张图之间,第 2 张图增加了以下几个关键部分:
-
全局网络(Global Network):这表明有一个中央网络(可能在服务器上运行),它维护着策略(Policy π(s))和价值(V(s))函数。这是模型的核心部分,其训练了共享的策略和价值函数。
-
多个工作者(Workers):图中展示了多个工作者(Worker 1, Worker 2, …, Worker n),每个工作者都有自己的网络副本。这些工作者可以并行地在不同的环境实例中探索和学习。
-
并行环境:与每个工作者相连的是不同的环境实例(Environment 1, Environment 2, …, Environment n)。这意味着每个工作者都可以在自己的环境副本中独立地进行学习,这增加了样本的多样性并加快了训练过程。
-
异步更新:工作者在自己的环境中收集经验后,会异步地将这些经验反馈给全局网络。这通常涉及到梯度或参数更新。
第一张图是一个单一智能体的演员-评论家架构,没有显示出并行处理或异步更新的特征。
第二张图在第一张图的基础上增加了并行化和分布式计算的概念,这是现代强化学习算法中用于加速训练和提高稳定性的常见技术。
A3C 核心是,通过多个智能体(或称为“工作者”)在不同的环境副本中同时运行来加速学习过程。
并行步骤
A3C 算法的流程:
-
初始化全局网络:
- 首先,创建一个全局网络,它有两个主要部分:演员(Actor)和评论家(Critic)。
- 演员部分负责输出动作的概率分布。
- 评论家部分负责评估采取某个动作的期望回报。
-
启动多个工作者:
- 同时启动多个工作者(智能体),每个工作者都有自己的网络副本,这些副本的初始权重来自全局网络。
- 每个工作者都在自己的环境副本中运行,这些环境互不干扰。
-
工作者独立探索:
- 每个工作者根据自己的网络副本和当前状态来选择动作,并观察结果和奖励。
- 工作者会继续这个过程,直到达到一定的时间步数或者终止条件(例如,完成任务或任务失败)。
-
计算梯度并更新全局网络:
- 工作者使用其经验(状态、动作、奖励等)来计算梯度。这些梯度用于改进其网络副本。
- 然后,这些梯度被发送到全局网络,并用于更新全局网络的权重。
-
同步工作者网络:
- 更新全局网络后,工作者将全局网络的新权重复制到自己的网络副本中。
- 这样,所有工作者都可以从全局网络学到的新知识中受益。
-
重复探索和学习过程:
- 工作者再次开始在其环境中探索,并重复上述过程。
- 这个过程会不断重复,工作者不断探索、学习并更新全局网络。
-
终止条件:
- 当全局网络达到一定的性能标准,或者经过足够多的更新周期后,算法可以停止。
- 此时,全局网络已经足够好,可以用来做决策或进一步的任务。
A3C 算法的关键优势在于并行性和异步更新。
多个工作者同时探索不同的策略和环境,可以更快地覆盖更广泛的状态空间,而不必等待其他工作者完成。
异步更新意味着全局网络不断地接收来自多个源的梯度信息,这可以导致更快的学习和更稳定的收敛。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!