3.1 CUDA Thread Organization
在第2章中,数据并行计算,我们学会了编写一个简单的CUDA C程序,该程序启动内核和线程网格,以对一维数组中的元素进行操作。内核指定每个线程执行的C语句。当我们发动如此大规模的执行活动时,我们需要控制这些活动,以实现预期的结果、效率和速度。在本章中,我们将研究并行执行控制所涉及的重要概念。我们将首先学习线程索引和块索引如何促进多维数组的处理。随后,我们将探索灵活资源分配的概念和占用的概念。然后,我们将进入线程调度、延迟容忍度和同步。掌握这些概念的CUDA程序员完全有能力编写和理解高性能并行应用程序。
网格中的所有CUDA线程执行相同的内核函数;它们依靠坐标来区分彼此,并确定要处理的适当数据部分。这些线程被组织成两级层次结构:网格由一个或多个块组成,每个块由一个或多个线程组成。块中的所有线程共享相同的块索引,这是内核中blockIdx变量的值。每个线程都有一个线程索引,可以作为内核中threadldx变量的值访问。当线程执行内核函数时,对blockldx和threadldx变量的引用返回线程的坐标。内核启动语句中的执行配置参数指定了网格的尺寸和每个块的尺寸。这些维度是内核函数中变量gridDim和blockDim的值。
层次组织
与CUDA线程类似,许多现实世界的系统是分层组织的。美国电话系统就是一个很好的例子。在顶层,电话系统由“区域”组成,每个区域对应一个地理区域。同一区域内的所有电话线都具有相同的3位数“区号”。电话区域可以比城市大;例如,伊利诺伊州中部的许多县和城市位于同一电话区域内,并共享相同的区号217。在一个区域内,每条电话线都有一个七位数的本地电话号码,这使得每个区域最多可以有大约1000万个号码。
每条电话线可以被视为CUDA线程,区号可以视为blockIdx的值,七位本地号码可以被视为线程-Idx的值。这种分层组织允许系统容纳相当多的电话线,同时保留呼叫同一区域的“位置”。在同一区域拨打电话线时,来电者只需要拨打本地号码。只要我们在当地拨打大部分电话,我们很少需要拨打区号。如果我们偶尔需要拨打另一个地区的电话线,我们拨打1"和区号,然后拨打本地号码。(这就是为什么任何地区的本地号码都不应该以“1”开头的原因)CUDA线程的分层组织也提供了一种局部性形式,将在这里进行研究。
一般来说,网格是块的三维数组,每个块都是线程的三维数组。启动内核时,程序需要指定每个维度的网格和块的大小。通过将未使用维度的大小设置为1,程序员可以使用少于三个维度。网格的确切组织由内核启动语句的执行配置参数(在<<< >>>内)决定。第一个执行配置参数在块数中指定网格的尺寸。第二个指定了线程数中每个块的尺寸。每个这样的参数都是dim3类型,这是一个具有三个无符号整数字段的C结构:x、y和z。这三个字段指定了三维的大小。
计算能力小于2.0的设备支持具有高达二维块数组的网格。
为了说明,以下主机代码可用于启动vecAddkernel() 内核函数,并生成一个由32个块组成的1D网格,每个块由128个线程组成。网格中的线程总数为128*32 = 4096。
dim3 dimGrid(32, 1, 1);
dim3 dimBlock(128, 1, 1);
vecAddKernel<<<dimGrid, dimBlock>>>(…);
请注意,dimBlock和dimGrid是程序员定义的主机代码变量。这些变量可以具有任何合法的C变量名,只要它们是dim3类型,并且内核启动使用适当的名称。例如,以下语句与上述语句相同:
dim3 dog(32, 1, 1);
dim3 cat(128, 1, 1);
vecAddKernel<<<dog, cat>>>(…);
网格和块尺寸也可以从其他变量计算。图2.15中的内核启动可以写成如下:
dim3 dimGrid(ceil(n/256.0), 1, 1);
dim3 dimBlock(256, 1, 1);
vecAddKernel<<<dimGrid, dimBlock>>>(…);
块的数量可能会随着网格的向量大小而变化,以便有足够的线程来覆盖所有矢量元素。在本例中,程序员选择将块大小固定为256。内核启动时变量n的值将决定网格的维度。如果n等于1000,网格将由四个块组成。如果n等于4000,网格将有16个块。在每种情况下,都会有足够的线程来覆盖所有矢量元素。一旦vecAddKernel启动,网格和块尺寸将保持不变,直到整个网格完成执行。
为了方便起见,CUDA C为启动具有一维网格和块的内核提供了一个特殊的快捷方式。算术表达式可以用来指定ID网格和块的配置,而不是dim3变量。在这种情况下,CUDA C编译器只是将算术表达式作为x维度,并假设y和z维度是1。因此,内核启动语句如图2.15所示:
vecAddKernel<<<ceil(n/256.0), 256>>>(…);
熟悉C中结构使用的读者会意识到,这种1D配置的“速记”惯例利用了x字段是dim3结构gridDim(x,y,z)和blockDimlx,y,z)的第一个字段这一事实。此快捷方式允许编译器使用执行配置参数中提供的值方便地初始化gridDim和blockDim的x字段。
在内核函数中,变量gridDim和blockDim的x字段根据执行配置参数的值进行预初始化。如果n等于4000,vectAddkernel内核中对gridDim.x和blockDim.x的引用将分别获得16和256。与主机代码中的dim3变量不同,内核函数中这些变量的名称是CUDA C规范的一部分,不能更改——即内核中的gridDim和blockDim总是反映网格和块的维度。
在CUDA C中,gridDim.x、gridDim.y和gridDim.z的允许值从1到65,530不等。块中的所有线程共享相同的blockIdx.x、blockldx.y和blockldx.z值。在块中,blockldx.x值从0到gridDim.x-1,blockldx.y值从O到gridDim.y-1,blockldx.z值从O到gridDim.z-1。
关于块的配置,每个块都组织成一个三维线程数组。可以通过将blockDim.z设置为1来创建二维块。可以通过将blockDim.y和blockDim.z设置为1来创建一维块,就像vectorAddkernel示例中的情况一样。如前所述,网格中的所有块都具有相同的尺寸和大小。块每个维度的线程数由内核启动时的第二个执行配置参数指定。在内核中,此配置参数可以作为blockDim的x、y和z字段访问。
块的总尺寸限制在1024个线程,只要线程总数不超过1024,就可以灵活地将这些元素分配到三维中。例如,blockDim(512,1,1)、blockDim(8, 16,4)和blockDim(32, 16, 2)是允许的blockDim值,但blockDim(32, 32, 2)是不允许的,因为线程总数将超过1024.
网格可以具有比其块更高的维度,反之亦然。例如,图 3.1显示了gridDim(2,2,1)与block-Dim(4,2,2)的小玩具网格示例。网格可以使用以下主机代码生成:
dim3 dimGrid(2, 2, 1);
dim3 dimBlock(4, 2, 2);
KernelFunction<<<dimGrid, dimBlock>>>(…);
网格由四个块组成,组织成一个2×2的阵列。图3.1中的每个block被标记为(blockldx.y,blockIdx.x),例如,Block(1,0)有blockIdx.y=1和blockldx.x=0。标签的顺序是,最高维度是第一位的。请注意,此块标记符号是C语句中用于设置配置参数的反向顺序,其中最低维度优先。当我们说明在访问多维数据时将线程坐标映射到数据索引时,这种标记块的反向排序效果会更有效。
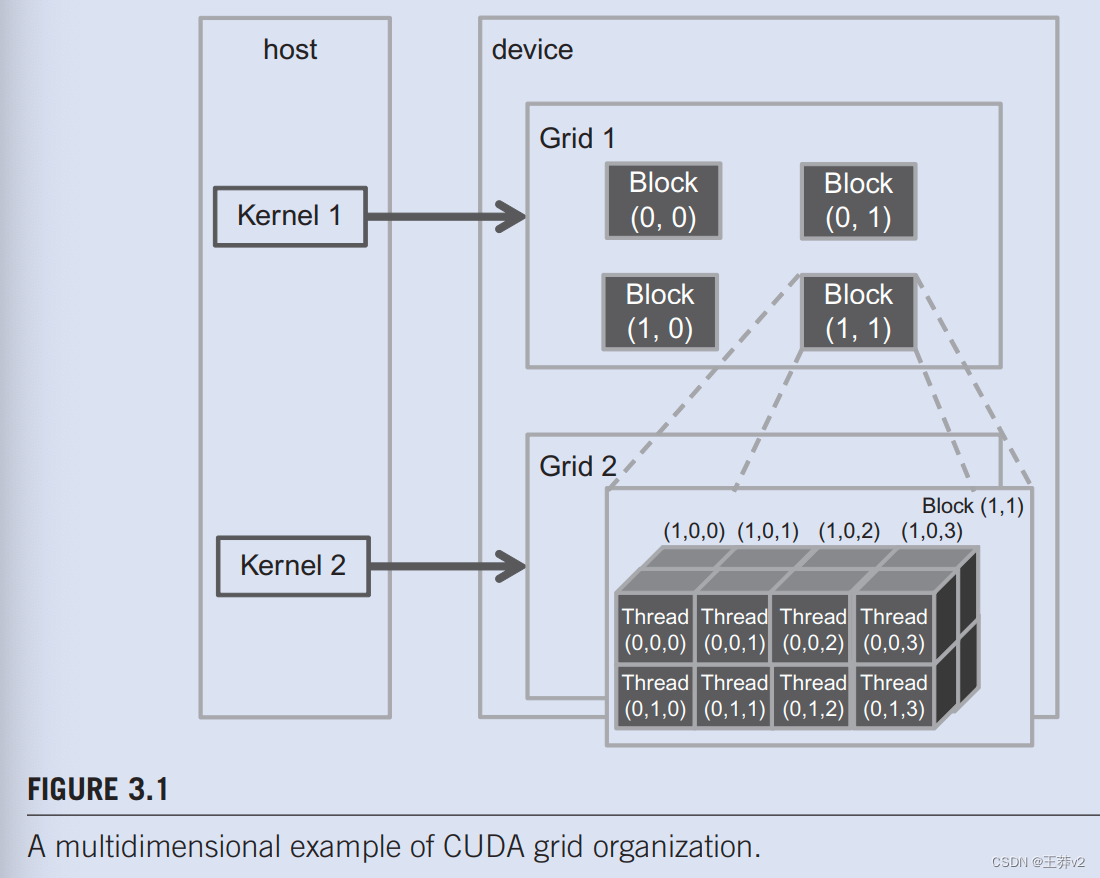
每个threadIdx还由三个字段组成:x坐标threadId.x、y坐标threadldx.y和z坐标threadldx.z。图3.1说明了块中线程的组织。在本例中,每个块被组织成4x2×2的线程数组。网格中的所有块都具有相同的维度;因此,我们只需要展示其中一个。图3.1扩展了Block(1,1)以显示其16个线程。例如,Thread(1,0,2)有threadldx.z=1、threadldx.y=0和threadldx.x=2。这个例子显示了4个块,每个块有16个线程,网格中共有64个线程。我们用这些小数字来保持插图的简单。典型的CUDA网格包含数千到数百万个线程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!