【Spark精讲】SparkSQL的RBO与CBO
Spark SQL核心:Catalyst

????????Spark SQL的核心是Catalyst查询编译器,它将用户程序中的SQL/Dataset/DataFrame经过一系列操作,最终转化为Spark系统中执行的RDD。
Catalyst组成部分
- Parser :用Antlr将SQL/Dataset/DataFrame转化成一棵未经解析的树,生成 Unresolved Logical Plan
- Analyzer:Analyzer 结合 Catalog 信息对Parser中生成的树进行解析,生成 Resolved Logical Plan
- Optimizer:对解析完的逻辑计划进行树结构的优化,以获得更高的执行效率,生成 Optimized Logical Plan
- 谓词下推(Predicate Pushdown):PushdownPredicate 是最常见的用于减少参与计算的数据量的方法,将过滤操作下推到join之前进行
- 常量合并(Constant Folding):比如, x+(1+2) ?-> x+3
- 列值裁剪(Column Pruning):对列进行裁减,只留下需要的列
- Planner:Planner将Optimized Logical Plan 转换成多个 Physical Plan
- CostModel:CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan
- Spark 以 DAG 的方法执行上述 Physical Plan,在执行 DAG 的过程中,Adaptive Execution 根据运行时信息动态调整执行计划从而提高执行效率
?SQL优化器:RBO、CBO
????????SQL语句转化为具体执行计划是由SQL查询编译器决定的,同一个SQL语句可以转化成多种物理执行计划,如何指导编译器选择效率最高的执行计划,这就是优化器的主要作用。传统数据库(例如Oracle)的优化器有两种:
- 基于规则的优化器(Rule-Based Optimization,RBO)
- 基于代价的优化器(Cost-Based Optimization,CBO)
2.1 RBO(Rule-Based Optimization)
????????RBO: Rule-Based Optimization也即“基于规则的优化器”,该优化器按照硬编码在数据库中的一系列规则来决定SQL的执行计划。只要按照这个规则去写SQL语句,无论数据表中的内容怎样、数据分布如何,都不会影响到执行计划。
? ? ? ? 基于规则优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用BroadcastHashJoin ?还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化(CBO)就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种代价最小的方案 。
2.2 CBO(Cost-Based Optimization)
????????CBO: Cost-Based Optimization也即“基于代价的优化器”,该优化器通过根据优化规则对关系表达式进行转换,生成多个执行计划,然后CBO会通过根据统计信息(Statistics)和代价模型(Cost Model)计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。CBO依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。
? ? ? ? CBO 原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。其核心在于评估一个给定的物理执行计划的代价。物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合。
? ? ? ? 每个执行节点的代价分为两个部分:
- 该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
? ? ? ? 要计算每个执行节点的代价,CBO需要解决两个问题:
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
CBO面临的挑战
??????在Spark1.0中所有的Catalyst Optimizer都是基于规则 (rule) 优化的。为了产生比较好的查询规 则,优化器需要理解数据的特性,于是在Spark2.0中引入了基于代价的优化器 (cost-based optimizer),也就是所谓的CBO。然而,CBO也无法解决很多问题,比如:
- 数据统计信息普遍缺失,统计信息的收集代价较高;
- 储存计算分离的架构使得收集到的统计信息可能不再准确;
- Spark部署在某一单一的硬件架构上,cost很难被估计;
- Spark的UDF(User-defined Function)简单易用,种类繁多,但是对于CBO来说是个黑盒子,无法估计其cost;
总而言之,由于种种限制,Spark的优化器无法产生最好的Plan。
也许你会想:Spark为什么不解决这个问题呢?这里有很多挑战,比如:?
- 统计信息的缺失,统计信息的不准确,那么就是默认依据文件大小来预估表的大小,但是文件 往往是压缩的,尤其是列存储格式,比如parquet 和 ORC,而Spark是基于行处理,如果数据连续重复,file size可能和真实的行存储的真实大小,差别非常之大。这也是为何提高 autoBroadcastJoinThreshold,即使不是太大也可能会导致out of memory;?
- Filter复杂、UDFs的使用都会使Spark无法准确估计Join输入数据量的大小。当你的queryplan异常大和复杂的时候,这点尤其明显;
- 其中,Spark3.0中基于运行期的统计信息,将Sort Merge Join 转换为Broadcast Hash Join。
基于RBO优化
left join case
var appSql: String =
"""
|select
| *
|from
| tab_spark_test as t1
|left join tab_spark_test_2 as t2
|on t1.id = t2.id
|and t1.id > 5+5
""".stripMargin
sparkSession.sql("use default;")
sparkSession.sql(appSql).explain(mode = "extended")执行计划?
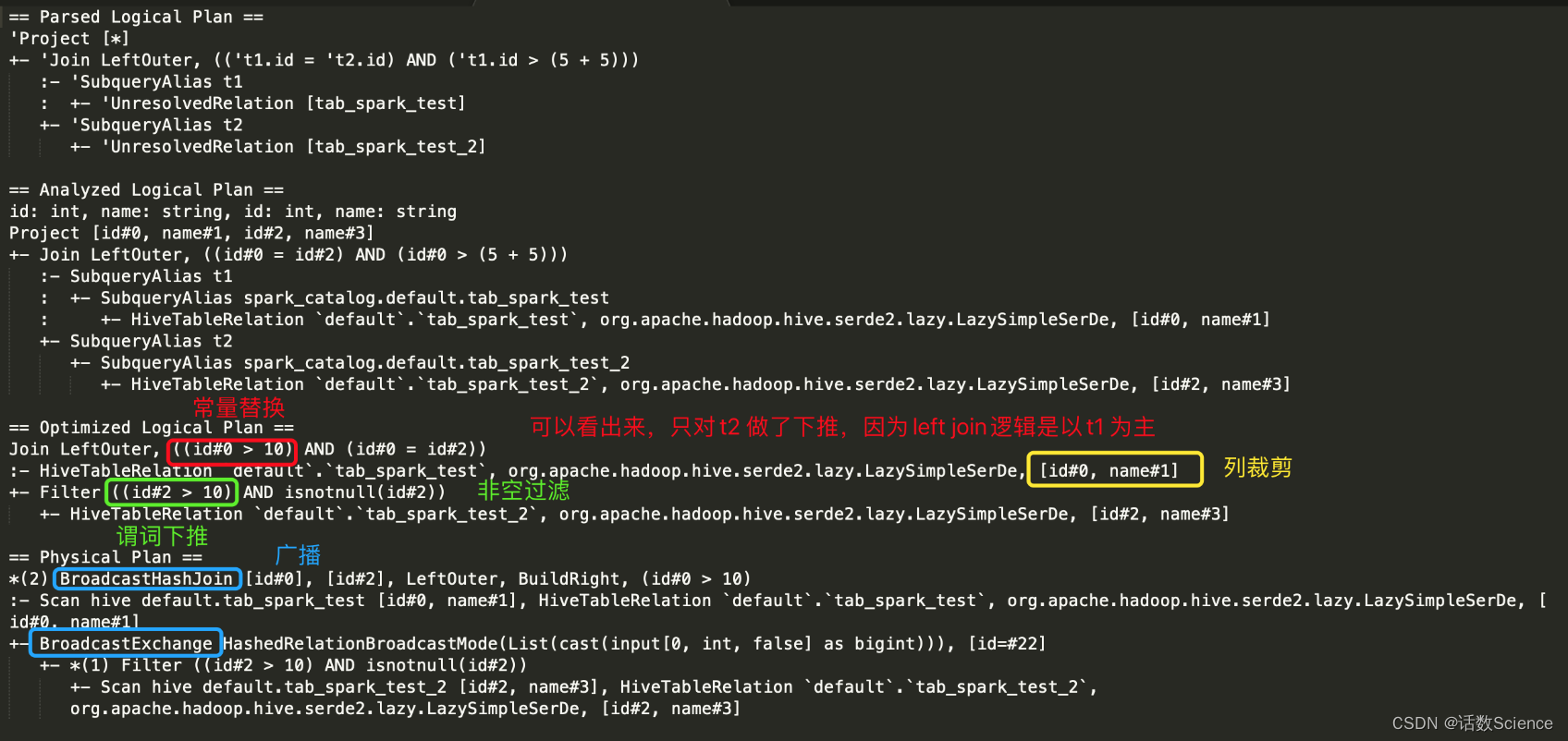
Outer 类型 Join 中的谓词下推
Outer 类型的 Join 操作在实际业务中的应用非常广泛 。 然而,不同于常规的 Join, Outer 类型 Join操作的谓词下推的处理比较复杂,用户在写 SQL语句时非常容易忽略,使得执行结果与自己的本意不符。 下面详细介绍谓词下推的几种处理逻辑。
对于 OuterJoin,假设返回所有行的基表为 Preserved row table,另外一张表为 Null supplying table,例如 t1 left?join t2,则 t1?为 Preserved row table, t2 为 Null supplying table。 如果 Join 条件表达式为“on t1.key = t2.key and t1.key > 1 where t2.key >2”,则“t1.key> 1”叫作“Join 中条件”,“t2.key>2”叫作“Join后条件”。 总结起来, Outer Join语句的谓词下推有 4种情况,如下表所示。
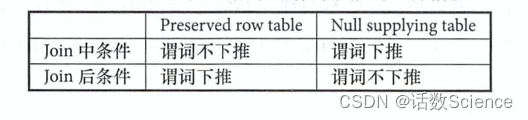
为了方便分析,构造如下数据,假设表 t1?和表 t2 中的数据相同,都只包含两条数据。下面以数据表 t1?和 t2 为例,说明这 4种情况。
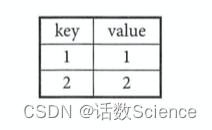
不加任何过滤条件
select t1. key, t1.value, t2.value
from t1 left join t2
on tl.key = t2.keys;| t1.key | t1.value | t2.value |
| 1 | 1 | 1 |
| 2 | 2 | 2 |
(1)?Preserved row table“Join 中条件”不下推
select t1. key, t1.value, t2.value
from t1 left join t2
on t1.key = t2.key
and t1.key > 1;这种情况下,过滤条件不会下推, SQL 最终执行的结果为:
 ?
?
(2) Preserved row table “Join 后条件”下推
select t1.key, t1.value, t2.value
from t1 left join t2
on t1.key = t2.key
where t1.key > 1;等价于
select
t1.key,
t1.value,
t2.value
from (
select key, value
from t1
where t1.key >1
) t3
left join t2
on t3.key = t2.key;
? ?
?
(3) Null supplying table “Join 中条件”下推
select t1.key, t1.value, t2.value
From t1 left join t2
on t1.key = t2.key
and t2.key > 1;等价于
select t1.key, t1.value, t2.value
from t1 left join
(
select key, value
from t2
where t2.key > 1
) t3
on t1.key = t3.key;?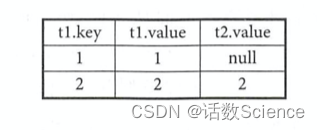
(4) Null supplying table “Join 后条件”不下推
select t1.key, t1.value, t2.value
from t1 left join t2
on t1.key = t2.key
where t2.key >1;

基于CBO优化
CBO 优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
而每个执行节点的代价,分为两个部分:?
1、该执行节点对数据集的影响,即该节点输出数据集的大小与分布;
2、该执行节点操作算子的代价。
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
1、初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;
2、中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
需要先执行特定的 SQL 语句来收集所需的表和列的统计信息。?
--表级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS
--生成列级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列 1,列 2,列 3
--显示统计信息
DESC FORMATTED 表名
--显示列统计信息
DESC FORMATTED 表名 列名s没有执行 ANALYZE状态?
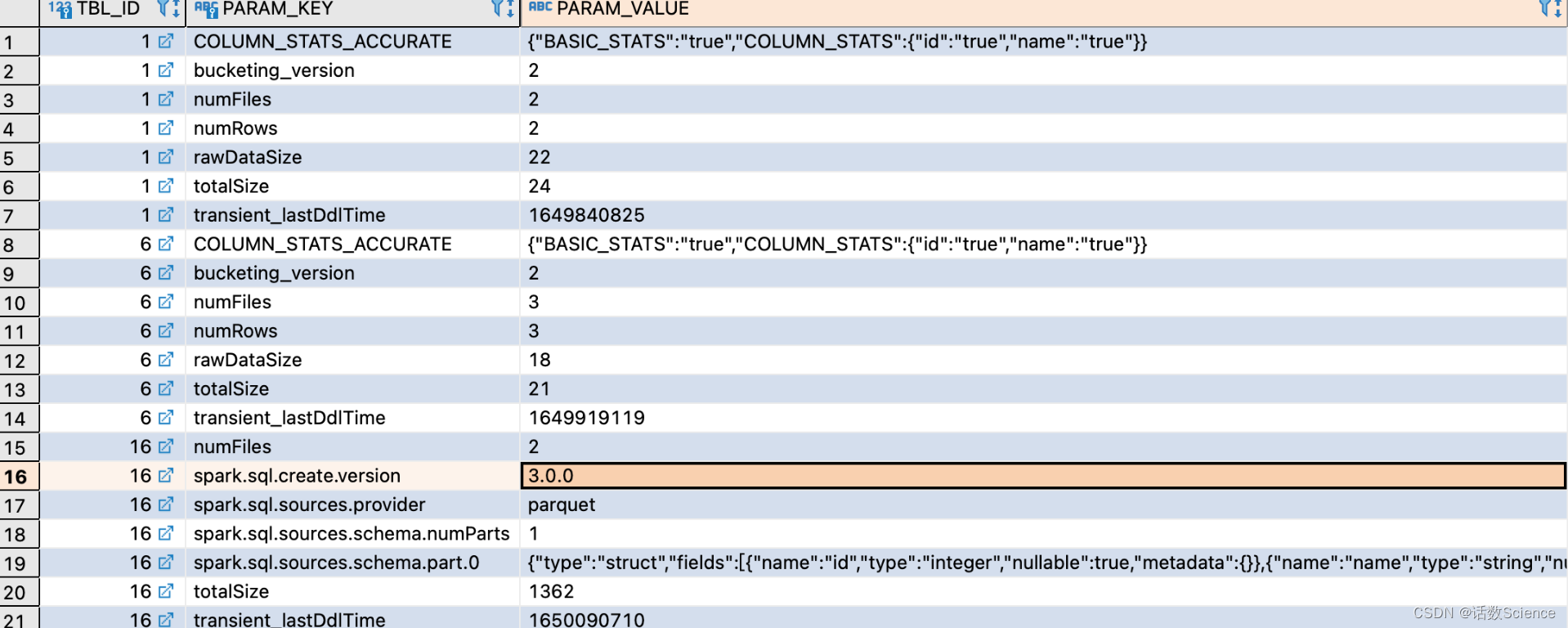
执行 ANALYZE后,发现多了很多spark.sql.statistics信息
 ?
?
CBO相关参数
通过 "spark.sql.cbo.enabled" 来开启,默认是 false。配置开启 CBO 后,CBO 优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build 侧选择、优化 Join 类型、优化多表 Join 顺序等。
- spark.sql.cbo.enabled
默认false。true?表示打开,false?表示关闭。
要使用该功能,需确保相关表和列的统计信息已经生成。 - spark.sql.cbo.joinReorder.enabled
使用 CBO 来自动调整连续的 inner join 的顺序。
默认false。true:表示打开,false:表示关闭
要使用该功能,需确保相关表和列的统计信息已经生成,且CBO 总开关打开。 - spark.sql.cbo.joinReorder.dp.threshold
使用 CBO 来自动调整连续 inner join 的表的个数阈值。
默认10。
如果超出该阈值,则不会调整 join 顺序。
val CBO_ENABLED =
buildConf("spark.sql.cbo.enabled")
.doc("Enables CBO for estimation of plan statistics when set true.")
.version("2.2.0")
.booleanConf
.createWithDefault(false)
val PLAN_STATS_ENABLED =
buildConf("spark.sql.cbo.planStats.enabled")
.doc("When true, the logical plan will fetch row counts and column statistics from catalog.")
.version("3.0.0")
.booleanConf
.createWithDefault(false)
val JOIN_REORDER_ENABLED =
buildConf("spark.sql.cbo.joinReorder.enabled")
.doc("Enables join reorder in CBO.")
.version("2.2.0")
.booleanConf
.createWithDefault(false)
val JOIN_REORDER_DP_THRESHOLD =
buildConf("spark.sql.cbo.joinReorder.dp.threshold")
.doc("The maximum number of joined nodes allowed in the dynamic programming algorithm.")
.version("2.2.0")
.intConf
.checkValue(number => number > 0, "The maximum number must be a positive integer.")
.createWithDefault(12)
val JOIN_REORDER_CARD_WEIGHT =
buildConf("spark.sql.cbo.joinReorder.card.weight")
.internal()
.doc("The weight of cardinality (number of rows) for plan cost comparison in join reorder: " +
"rows * weight + size * (1 - weight).")
.version("2.2.0")
.doubleConf
.checkValue(weight => weight >= 0 && weight <= 1, "The weight value must be in [0, 1].")
.createWithDefault(0.7)
val JOIN_REORDER_DP_STAR_FILTER =
buildConf("spark.sql.cbo.joinReorder.dp.star.filter")
.doc("Applies star-join filter heuristics to cost based join enumeration.")
.version("2.2.0")
.booleanConf
.createWithDefault(false)
val STARSCHEMA_DETECTION = buildConf("spark.sql.cbo.starSchemaDetection")
.doc("When true, it enables join reordering based on star schema detection. ")
.version("2.2.0")
.booleanConf
.createWithDefault(false)
val STARSCHEMA_FACT_TABLE_RATIO = buildConf("spark.sql.cbo.starJoinFTRatio")
.internal()
.doc("Specifies the upper limit of the ratio between the largest fact tables" +
" for a star join to be considered. ")
.version("2.2.0")
.doubleConf
.createWithDefault(0.9)?使用举例
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("CBO")
.set("spark.sql.cbo.enabled", "true")
.set("spark.sql.cbo.joinReorder.enabled", "true")
.setMaster("local[*]")
val sparkSession: SparkSession = Util.SparkSession2hive(sparkConf)
var appSql: String =
"""
|select
| t1.name,count(1)
|from
| tab_spark_test as t1
|left join tab_spark_test_2 as t2
|on t1.id = t2.id
|group by t1.name
""".stripMargin
sparkSession.sql("use default;")
sparkSession.sql(appSql).show()
while (true) {}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!