Transformer从菜鸟到新手(三)
引言
这是Transformer的第三篇文章,上篇文章中我们了解了多头注意力和位置编码,本文我们继续了解Transformer中剩下的其他组件。
下篇文章会介绍完整的训练过程。
层归一化
层归一化想要解决一个问题,这个问题在Batch Normalization的论文中有详细的描述,即深层网络中内部结点在训练过程中分布的变化(Internal Covariate Shift,ICS,内部协变量偏移)问题。
如果神经网络的输入都保持同一分布,比如高斯分布,那么网络的收敛速度会快得多。但如果不做处理的话,这很难实现。由于低层参数的变化(梯度更新),会导致每层输入的分布也会在训练期间变化。
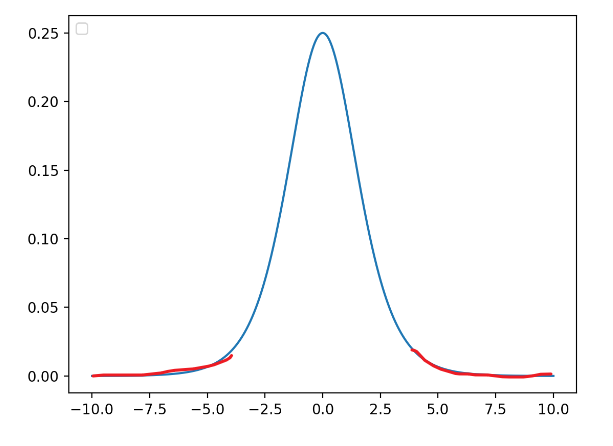
考虑有sigmoid激活函数 z = g ( W u + b ) z=g(Wu+b) z=g(Wu+b)的网络层,其中 u u u是该层的输入; W W W和 b b b是可学习的参数,且 g ( x ) = 1 1 + exp ? ( ? x ) g(x) = \frac{1}{1 +\exp(-x)} g(x)=1+exp(?x)1?。随着 ∣ x ∣ |x| ∣x∣增加, g ′ ( x ) g^\prime (x) g′(x)趋向于 0 0 0。这意味着对于 x = W u + b x = Wu+b x=Wu+b 中除了绝对值较小的维度之外的所有维度,流向 u u u的梯度将消失,导致模型训练缓慢。然而,因为 x x x也被 W , b W,b W,b和所有后续层的参数影响,在训练期间改变这些参数值也可能将 x x x的很多维度移动到非线性上的饱和区域(见下图红线位置),减缓收敛速度。这种影响还会随着网络层数的加深而增强。实际中,该饱和和梯度消失问题通常通过使用ReLU激活单元来解决,并且需要小心地初始化,以及小的学习率,但这也会导致训练过慢。
批归一化首先被提出来通过在深度神经网络中包含额外的归一化阶段来减少训练时间。批归一化通过使用训练数据中每个批次输入的均值和标准差来归一化每个输入。它需要计算累加输入统计量的移动平均值。在具有固定深度的网络中,可以简单地为每个隐藏层单独存储这些统计数据。针对的是同一个批次内所有数据的同一个特征。
然而批归一化并不适用于处理NLP任务的RNN(Transformer)中,循环神经元的累加输入通常会随着序列的长度而变化,而且循环神经元的需要计算的次数是不固定的(与序列长度有关)。
通常在NLP中一个批次内的序列长度各有不同,所以需要进行填充,存在很多填充token。如果使用批归一化,则容易受到长短不一中填充token的影响,造成训练不稳定。而且需要为序列中每个时间步计算和存储单独的统计量,如果测试序列不任何训练序列都要长,那么这也会是一个问题。
而层归一化针对的是批次内的单个序列样本,通过计算单个训练样本中一层的所有神经元(特征)的输入的均值和方差来归一化。没有对批量大小的限制,因此也可以应用到批大小为 1 1 1的在线学习。
批归一化是不同训练数据之间对单个隐藏单元(神经元,特征)的归一化,层归一化是单个训练数据对同一层所有隐藏单元(特征)之间的归一化。对比见下图:
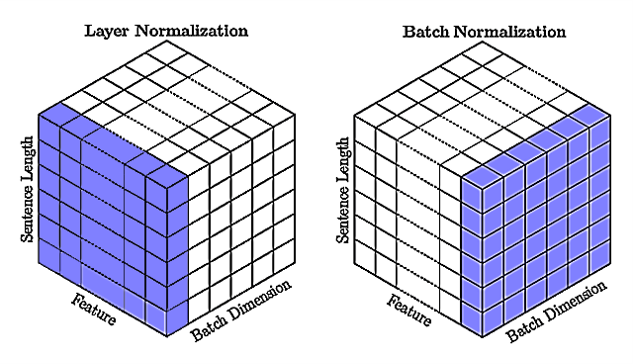
如上图右所示,批归一化针对批次内的所有数据的单个特征(Feature);层归一化针对批次内的单个样本的所有特征,它们都包含所有时间步。
说了这么多,那么具体是如何计算层归一化的呢?
y
=
x
?
E
[
x
]
Var
[
x
]
+
?
?
γ
+
β
(18)
\pmb y = \frac{\pmb x -E[\pmb x]}{\sqrt{\text{Var}[\pmb x] + \epsilon}} \cdot \pmb\gamma + \pmb\beta \tag {18}
y=Var[x]+??x?E[x]??γ+β(18)
x
\pmb x
x是归一化层的输入;
y
\pmb y
y是归一化层的输出(归一化的结果);
γ \pmb \gamma γ和 β \pmb \beta β是为归一化层每个神经元(特征)分配的一个自适应的缩放和平移参数。这些参数和原始模型一起学习,可以恢复网络的表示。通过设置 γ ( k ) = Var [ x ( k ) ] \gamma^{(k)} = \sqrt{\text{Var}[\pmb x^{(k)}]} γ(k)=Var[x(k)]?和 β ( k ) = E [ x ( k ) ] \beta^{(k)}=E[\pmb x^{(k)}] β(k)=E[x(k)],可以会输入恢复成原来的激活值,如果模型认为有必要的话;
? \epsilon ?是一个很小的值,防止除零。
class LayerNorm(nn.Module):
def __init__(self, features: int, eps: float = 1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x (Tensor): (batch_size, seq_length, d_model)
Returns:
Tensor: (batch_size, seq_length, d_model)
"""
mean = x.mean(-1, keepdims=True)
std = x.std(-1, keepdims=True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
残差连接
残差连接(residual connection,skip residual,也称为残差块)其实很简单,如下图所示:
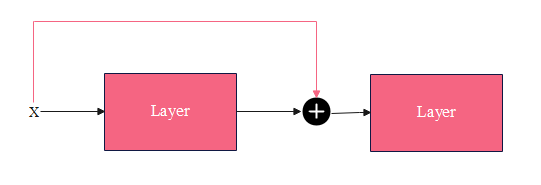
x
\pmb x
x为网络层的输入,该网络层包含非线性激活函数,记为
F
(
x
)
F(\pmb x)
F(x),用公式描述的话就是:
y
=
x
+
F
(
x
)
(19)
\pmb y = \pmb x + F(\pmb x) \tag{19}
y=x+F(x)(19)
y
\pmb y
y是该网络层的输出,它作为第二个网络层的输入。有点像LSTM中的门控思想,输入
x
\pmb x
x没有被遗忘。
一般网络层数越深,模型的表达能力越强,性能也就越好。但随着网络的加深,也带来了很多问题,比如梯度消失、梯度爆炸。
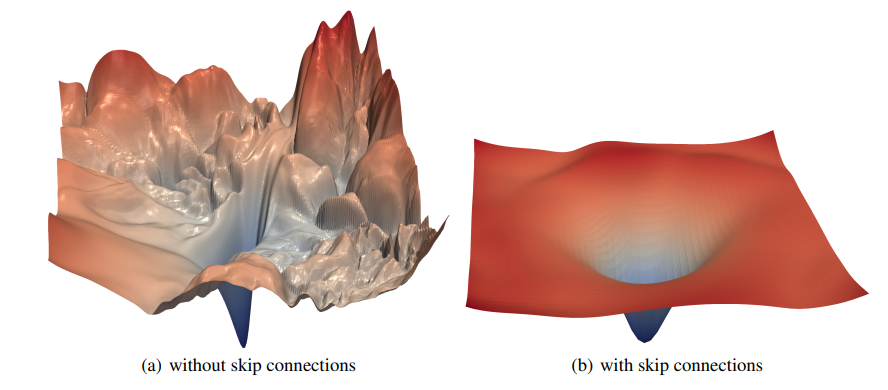
可以看出来,增加了残差连接后,损失平面更加平滑,没有那么多局部极小值。直观地看,有了残差连接了, x \pmb x x的信息可以直接传递到下一层,哪怕中间 F ( x ) F(\pmb x) F(x)是一个非常深的网络,只要它能学到将自己的梯度设成很小,不影响 x \pmb x x梯度的传递即可。
还有一些研究(Residual networks behave like ensembles of relatively shallow networks)表明,深层的残差网络可以看成是不同浅层网络的集成。
残差连接实现起来非常简单,就是公式 ( 19 ) (19) (19)的代码化:
x = x + layer(x)
位置感知前馈网络
Position-wise Feed Forward(FFN),逐位置的前馈网络,其实就是一个全连接前馈网络。目的是为了增加非线性,增强模型的表示能力。
它一个简单的两层全连接神经网络,不是将整个嵌入序列处理成单个向量,而是独立地处理每个位置的嵌入。所以称为position-wise前馈网络层。也可以看为核大小为1的一维卷积。
目的是把输入投影到特定的空间,再投影回输入维度。
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1) -> None:
"""
Args:
d_model (int): dimension of embeddings
d_ff (int): dimension of feed-forward network
dropout (float, optional): dropout ratio. Defaults to 0.1.
"""
super().__init__()
self.ff1 = nn.Linear(d_model, d_ff)
self.ff2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x (Tensor): (batch_size, seq_length, d_model) output from attention
Returns:
Tensor: (batch_size, seq_length, d_model)
"""
return self.ff2(self.dropout(F.relu(self.ff1(x))))
至此,Transformer模型的每个组件都实现好了,只剩下编码器和解码器。下面我们像搭积木一样,通过以上的组件来实现编码器和解码器。
编码器
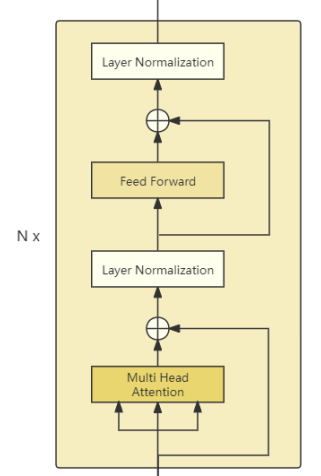
如图所示,编码器(Encoder)由N个编码器块(Encoder Block)堆叠而成,我们依次实现。
class EncoderBlock(nn.Module):
def __init__(
self,
d_model: int,
n_heads: int,
d_ff: int,
dropout: float,
norm_first: bool = False,
) -> None:
"""
Args:
d_model (int): dimension of embeddings
n_heads (int): number of heads
d_ff (int): dimension of inner feed-forward network
dropout (float): dropout ratio
norm_first (bool): if True, layer norm is done prior to attention and feedforward operations(Pre-Norm).
Otherwise it's done after(Post-Norm). Default to False.
"""
super().__init__()
self.norm_first = norm_first
self.attention = MultiHeadAttention(d_model, n_heads, dropout)
self.norm1 = LayerNorm(d_model)
self.ff = PositionWiseFeedForward(d_model, d_ff, dropout)
self.norm2 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
# self attention sub layer
def _sa_sub_layer(
self, x: Tensor, attn_mask: Tensor, keep_attentions: bool
) -> Tensor:
x = self.attention(x, x, x, attn_mask, keep_attentions)
return self.dropout1(x)
def _ff_sub_layer(self, x: Tensor) -> Tensor:
x = self.ff(x)
return self.dropout2(x)
def forward(
self, src: Tensor, src_mask: Tensor = None, keep_attentions: bool = False
) -> Tuple[Tensor, Tensor]:
"""
Args:
src (Tensor): (batch_size, seq_length, d_model)
src_mask (Tensor, optional): (batch_size, 1, seq_length)
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: (batch_size, seq_length, d_model) output of encoder block
"""
# pass througth multi-head attention
# src (batch_size, seq_length, d_model)
# attn_score (batch_size, n_heads, seq_length, k_length)
x = src
if self.norm_first:
x = x + self._sa_sub_layer(self.norm1(x), src_mask, keep_attentions)
x = x + self._ff_sub_layer(self.norm2(x))
else:
x = self.norm1(x + self._sa_sub_layer(x, src_mask, keep_attentions))
x = self.norm2(x + self._ff_sub_layer(x))
return x
注意层归一化的位置通过参数norm_first控制,默认norm_first=False,这种实现方式称为Post-LN,是Transformer的默认做法。但这种方式很难从零开始训练,把层归一化放到残差块之间,接近输出层的参数的梯度往往较大。然后在那些梯度上使用较大的学习率会使得训练不稳定。通常需要用到学习率预热(warm-up)技巧,在训练开始时学习率需要设成一个极小的值,但是一旦训练好之后的效果要优于Pre-LN的方式。
而如果采用norm_first=True的方式,被称为Pre-LN,它的区别在于对于子层(*_sub_layer)的输入先进行层归一化,再输入到子层中。最后进行残差连接。
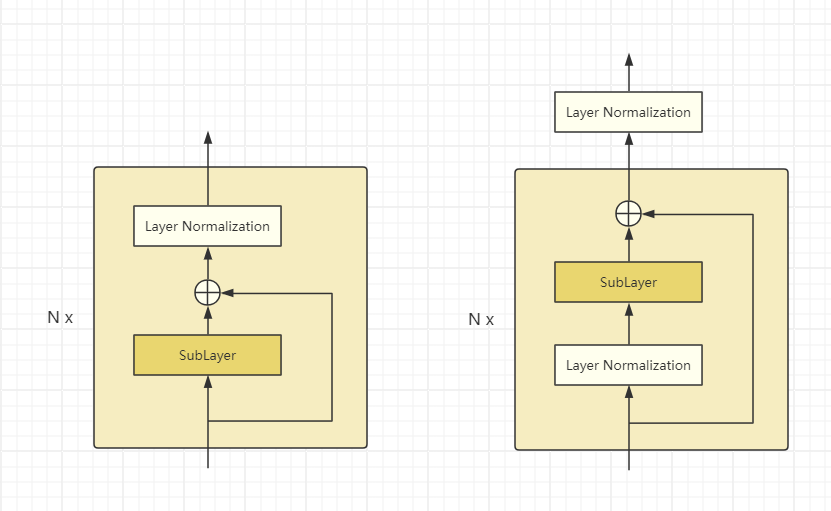
即实际上由上图左变成了图右,注意最后在每个Encoder或Decoder的输出上再接了一个层归一化。
有了编码器块,我们再来实现编码器。
class Encoder(nn.Module):
def __init__(
self,
d_model: int,
n_layers: int,
n_heads: int,
d_ff: int,
dropout: float = 0.1,
norm_first: bool = False,
) -> None:
"""
Args:
d_model (int): dimension of embeddings
n_layers (int): number of encoder blocks
n_heads (int): number of heads
d_ff (int): dimension of inner feed-forward network
dropout (float, optional): dropout ratio. Defaults to 0.1.
"""
super().__init__()
# stack n_layers encoder blocks
self.layers = nn.ModuleList(
[
EncoderBlock(d_model, n_heads, d_ff, dropout, norm_first)
for _ in range(n_layers)
]
)
self.norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(
self, src: Tensor, src_mask: Tensor = None, keep_attentions: bool = False
) -> Tensor:
"""
Args:
src (Tensor): (batch_size, seq_length, d_model)
src_mask (Tensor, optional): (batch_size, 1, seq_length)
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: (batch_size, seq_length, d_model)
"""
x = src
# pass through each layer
for layer in self.layers:
x = layer(x, src_mask, keep_attentions)
return self.norm(x)
这里要注意的是,最后对编码器和输出进行一次层归一化。
至此,我们的编码器完成了,在其forward()中src是词嵌入加上位置编码,那么src_mask是什么?它是用来指示非填充标记的。
我们知道,对于文本序列批数据,一个批次内序列长短不一,因此需要以一个指定的最长序列进行填充,而我们的注意力不需要在这些填充标记上进行。
创建src_mask很简单,假设输入是填充后的批数据:
def make_src_mask(src: Tensor, pad_idx: int = 0) -> Tensor:
"""make mask tensor for source sequences
Args:
src (Tensor): (batch_size, seq_length) raw sequences with padding
pad_idx (int, optional): pad index. Defaults to 0.
Returns:
Tensor: (batch_size, 1, 1, seq_length)
"""
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask
输出维度变成(batch_size, 1, 1, seq_length)为了与缩放点积注意力分数适配维度。
下面实现解码器。
解码器
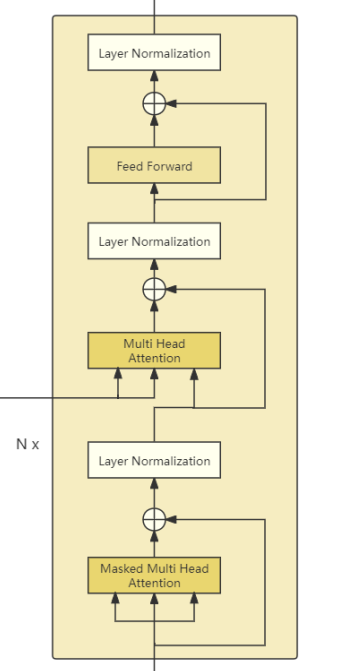
解码器相比编码器要复杂一点,首先,解码器块最下面的多头注意力叫做掩码多头注意力,这里的掩码是为了防止解码器看到目标序列中当前位置的下一个标记,强制模型仅使用现有的标记作为上下文来预测下一个标记。
然后,通过另一个多头注意力,它将编码器的输出作为附加输入——即Key和Value,来自掩码多头注意力的输出作为Query。后面和编码器是一样的,也包含一个前馈网络层。
基于此,我们先来实现解码器块(Decoder Block),再实现解码器(Decoder)。
class DecoderBlock(nn.Module):
def __init__(
self,
d_model: int,
n_heads: int,
d_ff: int,
dropout: float,
norm_first: bool = False,
) -> None:
"""
Args:
d_model (int): dimension of embeddings
n_heads (int): number of heads
d_ff (int): dimension of inner feed-forward network
dropout (float): dropout ratio
norm_first (bool): if True, layer norm is done prior to attention and feedforward operations(Pre-Norm).
Otherwise it's done after(Post-Norm). Default to False.
"""
super().__init__()
self.norm_first = norm_first
# masked multi-head attention
self.masked_attention = MultiHeadAttention(d_model, n_heads, dropout)
self.norm1 = LayerNorm(d_model)
# cross multi-head attention
self.cross_attention = MultiHeadAttention(d_model, n_heads, dropout)
self.norm2 = LayerNorm(d_model)
# position-wise feed-forward network
self.ff = PositionWiseFeedForward(d_model, d_ff, dropout)
self.norm3 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
# self attention sub layer
def _sa_sub_layer(
self, x: Tensor, attn_mask: Tensor, keep_attentions: bool
) -> Tensor:
x = self.masked_attention(x, x, x, attn_mask, keep_attentions)
return self.dropout1(x)
# cross attention sub layer
def _ca_sub_layer(
self, x: Tensor, mem: Tensor, attn_mask: Tensor, keep_attentions: bool
) -> Tensor:
x = self.cross_attention(x, mem, mem, attn_mask, keep_attentions)
return self.dropout2(x)
def _ff_sub_layer(self, x: Tensor) -> Tensor:
x = self.ff(x)
return self.dropout3(x)
def forward(
self,
tgt: Tensor,
memory: Tensor,
tgt_mask: Tensor = None,
memory_mask: Tensor = None,
keep_attentions: bool = False,
) -> Tuple[Tensor, Tensor, Tensor]:
"""
Args:
tgt (Tensor): (batch_size, tgt_seq_length, d_model) the (target) sequence to the decoder block.
memory (Tensor): (batch_size, src_seq_length, d_model) the sequence from the last layer of the encoder.
tgt_mask (Tensor, optional): (batch_size, 1, tgt_seq_length, tgt_seq_length) the mask for the tgt sequence.
memory_mask (Tensor, optional): (batch_size, 1, 1, src_seq_length) the mask for the memory sequence.
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
tgt (Tensor): (batch_size, tgt_seq_length, d_model) output of decoder block
"""
# pass througth masked multi-head attention
# tgt_ (batch_size, tgt_seq_length, d_model)
# masked_attn_score (batch_size, n_heads, tgt_seq_length, tgt_seq_length)
x = tgt
if self.norm_first:
x = x + self._sa_sub_layer(self.norm1(x), tgt_mask, keep_attentions)
x = x + self._ca_sub_layer(
self.norm2(x), memory, memory_mask, keep_attentions
)
x = x + self._ff_sub_layer(self.norm3(x))
else:
x = self.norm1(x + self._sa_sub_layer(x, tgt_mask, keep_attentions))
x = self.norm2(
x + self._ca_sub_layer(x, memory, memory_mask, keep_attentions)
)
x = self.norm3(x + self._ff_sub_layer(x))
return x
依次堆叠解码器块的组件。
class Decoder(nn.Module):
def __init__(
self,
d_model: int,
n_layers: int,
n_heads: int,
d_ff: int,
dropout: float = 0.1,
norm_first: bool = False,
) -> None:
"""
Args:
d_model (int): dimension of embeddings
n_layers (int): number of encoder blocks
n_heads (int): number of heads
d_ff (int): dimension of inner feed-forward network
dropout (float, optional): dropout ratio. Defaults to 0.1.
"""
super().__init__()
# stack n_layers decoder blocks
self.layers = nn.ModuleList(
[
DecoderBlock(d_model, n_heads, d_ff, dropout, norm_first)
for _ in range(n_layers)
]
)
self.norm = LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(
self,
tgt: Tensor,
memory: Tensor,
tgt_mask: Tensor = None,
memory_mask: Tensor = None,
keep_attentions: bool = False,
) -> Tensor:
"""
Args:
tgt (Tensor): (batch_size, tgt_seq_length, d_model) the (target) sequence to the decoder.
memory (Tensor): (batch_size, src_seq_length, d_model) the sequence from the last layer of the encoder.
tgt_mask (Tensor, optional): (batch_size, 1, tgt_seq_length, tgt_seq_length) the mask for the tgt sequence.
memory_mask (Tensor, optional): (batch_size, 1, 1, src_seq_length) the mask for the memory sequence.
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: (batch_size, tgt_seq_length, d_model) model output (logits)
"""
x = tgt
# pass through each layer
for layer in self.layers:
x = layer(x, memory, tgt_mask, memory_mask, keep_attentions)
x = self.norm(x)
return x
前面说在掩码多头注意力的时候,希望解码器只看到当前和之前的输入,而屏蔽未来的输入。那么这个掩码是怎样的呢?
假设目标是将"Nice to meet you"翻译是"很高兴认识你",我们的目标序列已经有了,即"很高兴认识你"。
首先给定<bos>和解码器最后一层的输出给编码器,编码器要预测出"很"这个字符,不管编码器预测出什么,基于teacher force的思想,我们需要让模型看到正确答案,即此时要看到"很",然后希望编码器预测出"高"。虽然描述上感觉有先后顺序,但在Transformer中这是并行计算的,因此训练时必须传入目标序列,强制使用teacher force。
因此只要把目标序列右移就可以当成在训练时解码器的输入。我们可以利用下三角矩阵完美的实现这个掩码。
import torch
seq_length = 7
torch.tril(torch.ones((seq_length, seq_length))).int()
tensor([[1, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)

从上往下看,最后一行的"你"位置可以看到整个序列,而第一行的"“只能看到”"本身,除此之外,还要考虑填充,填充标记也是不需要模型去"注意"的。
def make_tgt_mask(tgt: Tensor, pad_idx: int = 0) -> Tensor:
"""make mask tensor for target sequences
Args:
tgt (Tensor): (batch_size, seq_length) raw sequences with padding
pad_idx (int, optional): pad index. Defaults to 0.
Returns:
Tensor: (batch_size, 1, 1, seq_length)
"""
seq_len = tgt.size()[-1]
# padding mask
# tgt_mask (batch_size, 1, 1, seq_length)
tgt_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2)
# subsequcen mask
# subseq_mask (batch_size, 1, seq_length, seq_length)
subseq_mask = torch.tril(torch.ones((seq_len, seq_len))).bool()
tgt_mask = tgt_mask & subseq_mask
return tgt_mask
实现Transformer
最后,将上面实现编码器、解码器、位置编码和词嵌入等放到一起来完成Transformer模型。
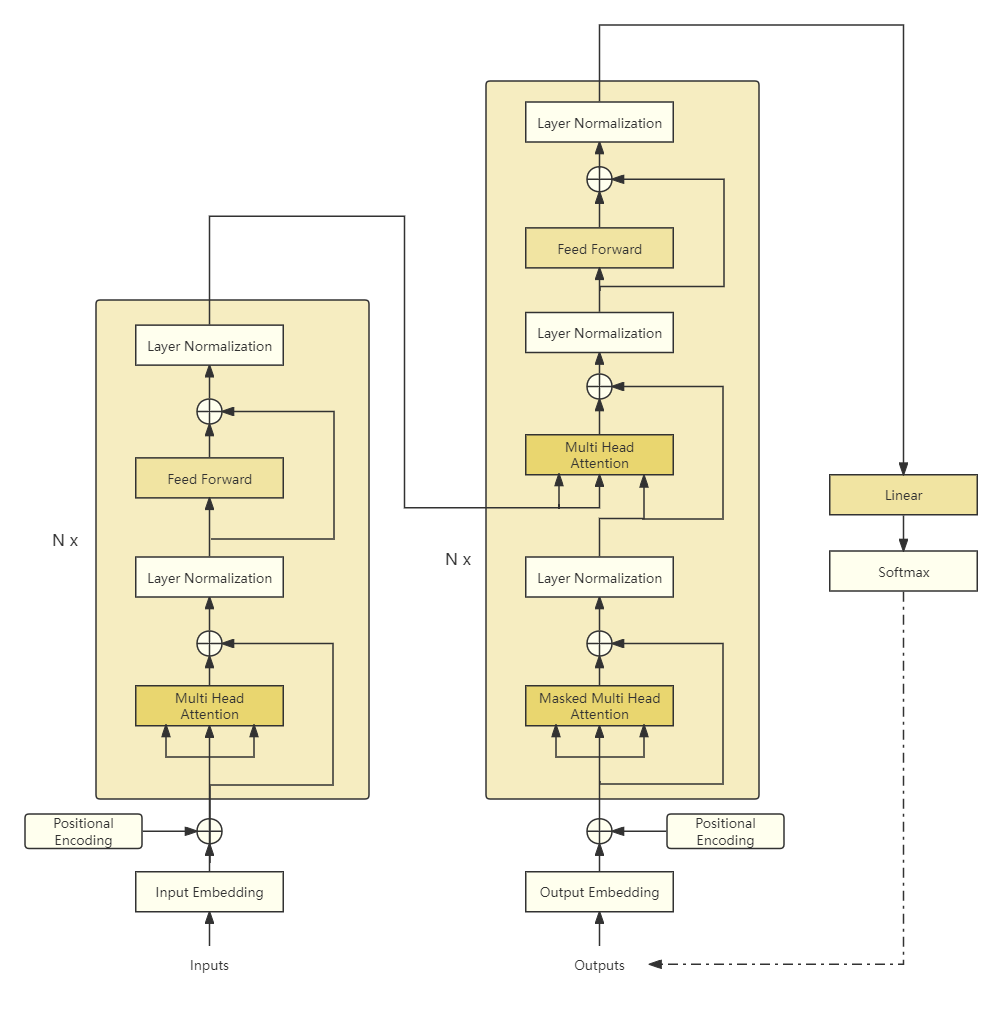
class Transformer(nn.Module):
def __init__(
self,
source_vocab_size: int,
target_vocab_size: int,
d_model: int = 512,
n_heads: int = 8,
num_encoder_layers: int = 6,
num_decoder_layers: int = 6,
d_ff: int = 2048,
dropout: float = 0.1,
max_positions: int = 5000,
pad_idx: int = 0,
norm_first: bool = False,
) -> None:
"""
Args:
source_vocab_size (int): size of the source vocabulary.
target_vocab_size (int): size of the target vocabulary.
d_model (int, optional): dimension of embeddings. Defaults to 512.
n_heads (int, optional): number of heads. Defaults to 8.
num_encoder_layers (int, optional): number of encoder blocks. Defaults to 6.
num_decoder_layers (int, optional): number of decoder blocks. Defaults to 6.
d_ff (int, optional): dimension of inner feed-forward network. Defaults to 2048.
dropout (float, optional): dropout ratio. Defaults to 0.1.
max_positions (int, optional): maximum sequence length for positional encoding. Defaults to 5000.
pad_idx (int, optional): pad index. Defaults to 0.
norm_first (bool): if True, layer norm is done prior to attention and feedforward operations(Pre-Norm).
Otherwise it's done after(Post-Norm). Default to False.
"""
super().__init__()
self.src_embedding = Embedding(source_vocab_size, d_model)
self.tgt_embedding = Embedding(target_vocab_size, d_model)
self.enc_pos = PositionalEncoding(d_model, dropout, max_positions)
self.dec_pos = PositionalEncoding(d_model, dropout, max_positions)
self.encoder = Encoder(
d_model, num_encoder_layers, n_heads, d_ff, dropout, norm_first
)
self.decoder = Decoder(
d_model, num_decoder_layers, n_heads, d_ff, dropout, norm_first
)
self.pad_idx = pad_idx
def encode(
self, src: Tensor, src_mask: Tensor = None, keep_attentions: bool = False
) -> Tensor:
"""
Args:
src (Tensor): (batch_size, src_seq_length) the sequence to the encoder
src_mask (Tensor, optional): (batch_size, 1, src_seq_length) the mask for the sequence
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: (batch_size, seq_length, d_model) encoder output
"""
# src_embed (batch_size, src_seq_length, d_model)
src_embed = self.enc_pos(self.src_embedding(src))
return self.encoder(src_embed, src_mask, keep_attentions)
def decode(
self,
tgt: Tensor,
memory: Tensor,
tgt_mask: Tensor = None,
memory_mask: Tensor = None,
keep_attentions: bool = False,
) -> Tensor:
"""
Args:
tgt (Tensor): (batch_size, tgt_seq_length) the sequence to the decoder.
memory (Tensor): (batch_size, src_seq_length, d_model) the sequence from the last layer of the encoder.
tgt_mask (Tensor, optional): (batch_size, 1, 1, tgt_seq_length) the mask for the target sequence. Defaults to None.
memory_mask (Tensor, optional): (batch_size, 1, 1, src_seq_length) the mask for the memory sequence. Defaults to None.
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: output (batch_size, tgt_seq_length, tgt_vocab_size)
"""
# tgt_embed (batch_size, tgt_seq_length, d_model)
tgt_embed = self.dec_pos(self.tgt_embedding(tgt))
# logits (batch_size, tgt_seq_length, d_model)
logits = self.decoder(tgt_embed, memory, tgt_mask, memory_mask, keep_attentions)
return logits
def forward(
self,
src: Tensor,
tgt: Tensor,
src_mask: Tensor = None,
tgt_mask: Tensor = None,
keep_attentions: bool = False,
) -> Tensor:
"""
Args:
src (Tensor): (batch_size, src_seq_length) the sequence to the encoder
tgt (Tensor): (batch_size, tgt_seq_length) the sequence to the decoder
keep_attentions (bool): whether keep attention weigths or not. Defaults to False.
Returns:
Tensor: (batch_size, tgt_seq_length, tgt_vocab_size)
"""
memory = self.encode(src, src_mask, keep_attentions)
return self.decode(tgt, memory, tgt_mask, src_mask, keep_attentions)
至此,我们整个Transformer模型实现好了,注意最后输出的是logits是隐藏层大小维度的,仿照HugginFace Transformer我们在上面加一个Head,将其转换成目标词表大小维度。
class TranslationHead(nn.Module):
def __init__(self, config: ModelArugment, pad_idx: int, bos_idx: int, eos_idx: int)-> None:
super().__init__()
self.config = config
self.pad_idx = pad_idx
self.bos_idx = bos_idx
self.eos_idx = eos_idx
self.transformer = Transformer(**asdict(config))
self.lm_head = nn.Linear(config.d_model, config.target_vocab_size, bias=False)
self.reset_parameters()
def forward(self, src: Tensor, tgt: Tensor, src_mask: Tensor=None, tgt_mask: Tensor=None, keep_attentions: bool=False) -> Tensor:
if src_mask is None and tgt_mask is None:
src_mask, tgt_mask = self.create_masks(src, tgt, self.pad_idx)
output = self.transformer(src, tgt, src_mask, tgt_mask, keep_attentions)
return self.lm_head(output)
@torch.no_grad()
def translate(self, src: Tensor, src_mask: Tensor=None, max_gen_len: int=60, num_beams:int = 3, keep_attentions: bool=False, generation_mode: str="greedy_search"):
if src_mask is None:
src_mask = self.create_masks(src, pad_idx=self.pad_idx)[0]
generation_mode = generation_mode.lower()
if generation_mode == "greedy_search":
return self._greedy_search(src, src_mask, max_gen_len, keep_attentions)
else:
return self._beam_search(src, src_mask, max_gen_len, num_beams, keep_attentions)
forward主要是用于训练,如果没有传mask,则自己创建。
然后定义一个translate()方法用于推理,接受源序列索引,输出生成的目标序列索引,这里支持贪心搜索解码和束搜索解码两种策略。相关内容请看后续文章。
完整代码
https://github.com/nlp-greyfoss/nlp-in-action-public/tree/master/transformers/transformer
欢迎??
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!