图像和LiDAR点云的可微分配准
文章:Differentiable Registration of Images and LiDAR Point Clouds with VoxelPoint-to-Pixel Matching
作者:Junsheng Zhou, Baorui Ma, Wenyuan Zhang,Yi Fang,Yu-Shen Liu,Zhizhong Han
编辑:点云PCL
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。侵权或转载联系微信cloudpoint9527。
摘要
不同模态之间的配准,即来自摄像机的2D图像和LiDAR的3D点云之间的配准,是计算机视觉和机器人领域中的关键任务。先前的方法通过匹配神经网络学习到的点和像素模式来估计2D-3D对应关系,并使用 Perspective-n-Points(PnP)在后处理阶段估计刚性变换。然而这些方法在将点和像素鲁棒地映射到共享的潜在空间方面存在困难,因为点和像素具有非常不同的特征,用不同的方式学习模式,而且它们也无法直接在变换上构建监督,因为PnP是不可微分的,导致不稳定的配准结果。为解决这些问题提出通过可微分的概率PnP求解器学习结构化的跨模态潜在空间,以表示像素特征和3D特征。具体而言设计了一个三元网络来学习VoxelPoint-to-Pixel匹配,其中我们使用体素和点来表示3D元素,以通过像素学习跨模态潜在空间。我们基于CNN设计了体素和像素分支,以在表示为网格的体素/像素上执行卷积,并集成了额外的点分支,以在体素化过程中丢失的信息。我们通过在概率PnP求解器上直接施加监督来端到端地训练我们的框架。为了探索跨模态特征的独特模式,我们设计了一种具有自适应权重优化的新型损失来描述跨模态特征。在KITTI和nuScenes数据集上的实验结果显示,与最先进的方法相比,我们的方法取得了显著的改进。代码和模型开源在:https://github.com/junshengzhou/VP2P-Match。
主要贡献
? 提出了一个新颖的框架,通过学习一个结构化的跨模态潜在空间,通过自适应权重优化,通过可微的PnP求解器进行端到端训练,从而学习图像到点云的配准。?
? 提出将3D元素表示为体素和点的组合,以克服点云和像素之间的模态差距,其中设计了一个三元网络来学习体素点到像素的匹配。?
? 通过在KITTI和nuScenes数据集上进行广泛实验,展示了我们在最先进技术上的卓越性能。
内容概述
首先详细介绍了VoxelPoint-to-Pixel匹配的框架,该框架用于学习结构化的跨模态潜在空间。接着提出了一种新颖的损失函数,具有自适应加权优化,用于学习独特的跨模态模式。最后引入了可微分的概率PnP求解器,这推动了我们的端到端学习模式。总体而言,该方法框架如图1所示。
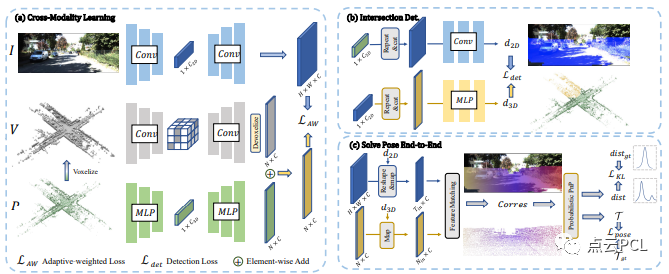
图1:我们方法的概述。给定一对未正确配准的图像I和点云P作为输入,(a) 我们首先对稀疏体素进行操作以生成稀疏体素V,然后应用三元网络从三个模态中提取模式。我们将2D模式表示为像素特征,将3D模式表示为体素和点特征的组合,分别使用自适应加权损失来学习独特的2D-3D跨模态模式。(b) 我们使用跨模态特征融合检测2D/3D空间中的交集区域。(c) 我们根据交集检测的结果去除异常区域,并使用2D-3D特征匹配建立2D-3D对应关系,然后应用概率PnP来预测外参姿势的分布,通过与真值位姿一起进行端到端的监督。
VoxelPoint-to-Pixel匹配框架
-
该框架采用三元网络,包括Voxel、Point和Pixel分支,以获取2D和3D特征。
-
在voxel分支中使用稀疏卷积,以有效捕捉空间模式。
-
引入point分支,受PointNet++启发,用于恢复在voxel化期间丢失的详细3D模式。
-
pixel分支基于卷积U-Net,提取全局2D图像特征。
2D-3D特征匹配
-
将3D元素表示为voxels和points的组合。
-
引入一种新方法,通过将它们映射到共享的潜在空间中,匹配2D和3D特征。
-
VoxelPoint-to-Pixel匹配创建了一个结构化的跨模态潜在空间,提供均匀的特征分布。
用于异常处理的交叉检测:
-
由于图像和LiDAR点云采集方式的不同,存在大量离群值区域,无法找到对应关系。
-
将交叉区域定义为LiDAR点云使用地面实况相机参数的2D投影与参考图像之间的重叠部分。
-
通过检测策略,预测每个2D/3D元素位于交叉区域的概率,有助于在推断2D-3D对应关系之前去除两个模态上的离群区域。

图2:使用点对像素(P2P)和体素点对像素(VP2P)匹配学习的潜在空间的 t-SNE 可视化
自适应加权优化策略
自适应加权优化旨在解决2D和3D任务中的特征匹配问题。通常情况下,传统的对比损失和三元损失等优化方法在处理2D-3D特征匹配时存在问题,提出了一种自适应加权的优化策略,该策略针对一组2D-3D配对样本,通过自适应权重因子对正对和负对进行加权,以更灵活地进行优化。
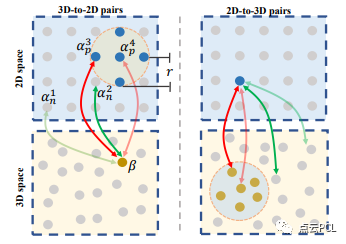
图3:自适应加权优化的说明
可微分 PnP
建立2D-3D的对应关系首先通过交叉区域检测,在两个模态中去除离群区域,然后利用交叉模态潜在空间的最近邻原则进行2D-3D特征匹配。为了建立对应关系,使用 arg max 操作在交叉模态潜在空间中搜索具有最大相似度的点坐标。这一操作是非可微的,但通过 Gumbel 估计器获得梯度以实现端到端训练。概率 PnP 方法将输出解释为概率分布,用于解决非可微的 PnP 问题,通过计算 KL 散度损失最小化预测姿态分布与地面真实姿态分布之间的距离,进行监督。此外,通过基于 Gauss-Newton 算法的迭代 PnP 求解器求解精确的姿态,并计算姿态损失。姿态损失也参与优化,因为 GN 算法的迭代部分是可微分的。
实验
我们在两个广泛使用的基准数据集KITTI和nuScenes上评估我们在图像到点云配准任务上的性能。在两个数据集上,图像和点云是通过2D相机和3D激光雷达同时捕获的。
定量与定性比较实验
定量比较:我们的方法在KITTI和nuScenes数据集上展现出卓越性能,尤其在RTE方面比最新的CorrI2P方法提高了大约4倍。我们的方法通过端到端训练框架,结合概率PnP求解器,能够学习稳健的2D-3D对应关系,实现了更准确的预测,如表1。

视觉比较:图5中的视觉比较显示,我们的方法在不同道路情况下实现了更好的配准精度。与其他方法相比,尤其是在调校困难的情况下,如第1行和第2行,我们的方法能够更准确地解决配准问题,而其他方法(如DeepI2P和CorrI2P)无法正确匹配树木和汽车的投影与图像中相应的像素。

图5:在KITTI数据集下进行的图像到点云配准结果的可视比较
特征匹配的精度
图6展示了特征匹配的可视化,通过计算两个模态上的匹配距离生成双侧误差图。对于2D到3D的匹配,我们在交叉区域的每个2D像素上寻找相似度最大的点,计算投影匹配点与2D像素之间的欧拉距离,结果显示我们的方法在2D到3D和3D到2D匹配中均明显优于CorrI2P。我们的方法在大多数匹配中能够实现小于2像素的轻微错误,表明我们学到的共享潜在空间能够准确区分交叉模态模式,实现准确的特征匹配。在图像和点云边缘处可能存在相对较大的错误,因为在边缘区域完美执行交叉区域检测通常是困难的。

图6:特征匹配误差可视化
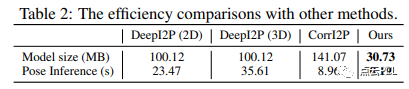
运行效率
与其他方法在NVIDIA RTX 3090 GPU和Intel(R) Xeon(R) E5-2699 CPU上进行了效率比较。在表2中,我们的方法参数更少,性能显著更好。此外我们的方法仅需0.19秒进行网络推断和一个帧的姿态估计,比先前的方法快了大约50倍(或更多)。
消融实验
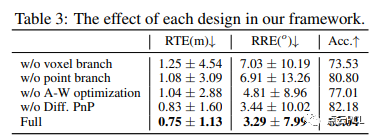
进行了消融研究以验证我们方法中每个设计的有效性以及一些重要参数的影响,报告了在KITTI数据集下RTE/RRE/Acc.的性能。
框架设计验证:我们通过四种变体验证了框架中每个设计的有效性,包括去除体素分支、去除点云分支、替换自适应加权优化损失以及去除可微PnP驱动的端到端监督。结果如表3,显示了全模型在所有变体中表现最佳,证明了每个设计在框架中的有效性。特别是,相较于去掉点云分支,体素分支在框架中扮演更重要的角色,表明体素模态更适合学习图像到点云的配准。
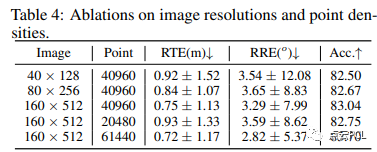
输入分辨率影响:我们进一步研究了输入图像分辨率和点云密度的影响。结果如表4显示,在两个模态上使用更高分辨率会带来更好的效果,因为低分辨率图像可能丢失一些视觉信息,而低密度点云则可能失去详细的几何结构,我们选择在性能和效率之间找到平衡的适当设置。
总结
这项工作提出了一个新颖的框架,通过VoxelPoint-to-Pixel匹配学习图像到点云的配准,其中我们使用一种新颖的自适应加权损失学习结构化的跨模态潜在空间。将3D元素表示为体素和点的组合,以克服点云和像素之间的域差异。此外通过在可微的PnP求解器上直接对预测的姿态分布进行监督,端到端地训练我们的框架,在KITTI和nuScenes数据集上进行的广泛实验证明了我们的卓越性能。
资源
自动驾驶及定位相关分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
自动驾驶中基于激光雷达的车辆道路和人行道实时检测(代码开源)
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
结构化PLP-SLAM:单目、RGB-D和双目相机使用点线面的高效稀疏建图与定位方案
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:dianyunpcl@163.com。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!