深入了解Snowflake雪花算法:分布式唯一ID生成器

😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志
🎐 个人CSND主页——Micro麦可乐的博客
🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战
🌺《RabbitMQ》本专栏主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识到项目实战
🌸《设计模式》专栏以实际的生活场景为案例进行讲解,让大家对设计模式有一个更清晰的理解
如果文章能够给大家带来一定的帮助!欢迎关注、评论互动~
深入了解Snowflake算法:分布式唯一ID生成器
前言
在分布式系统中,生成唯一ID是一项关键的任务。Snowflake算法是Twitter公司开发的一种分布式唯一ID生成算法,通过对时间、机器ID和序列号的合理组合,保证在分布式环境中生成唯一的64位ID。本文将深入解析Snowflake算法的原理,并附带Java代码示例。
Snowflake算法原理
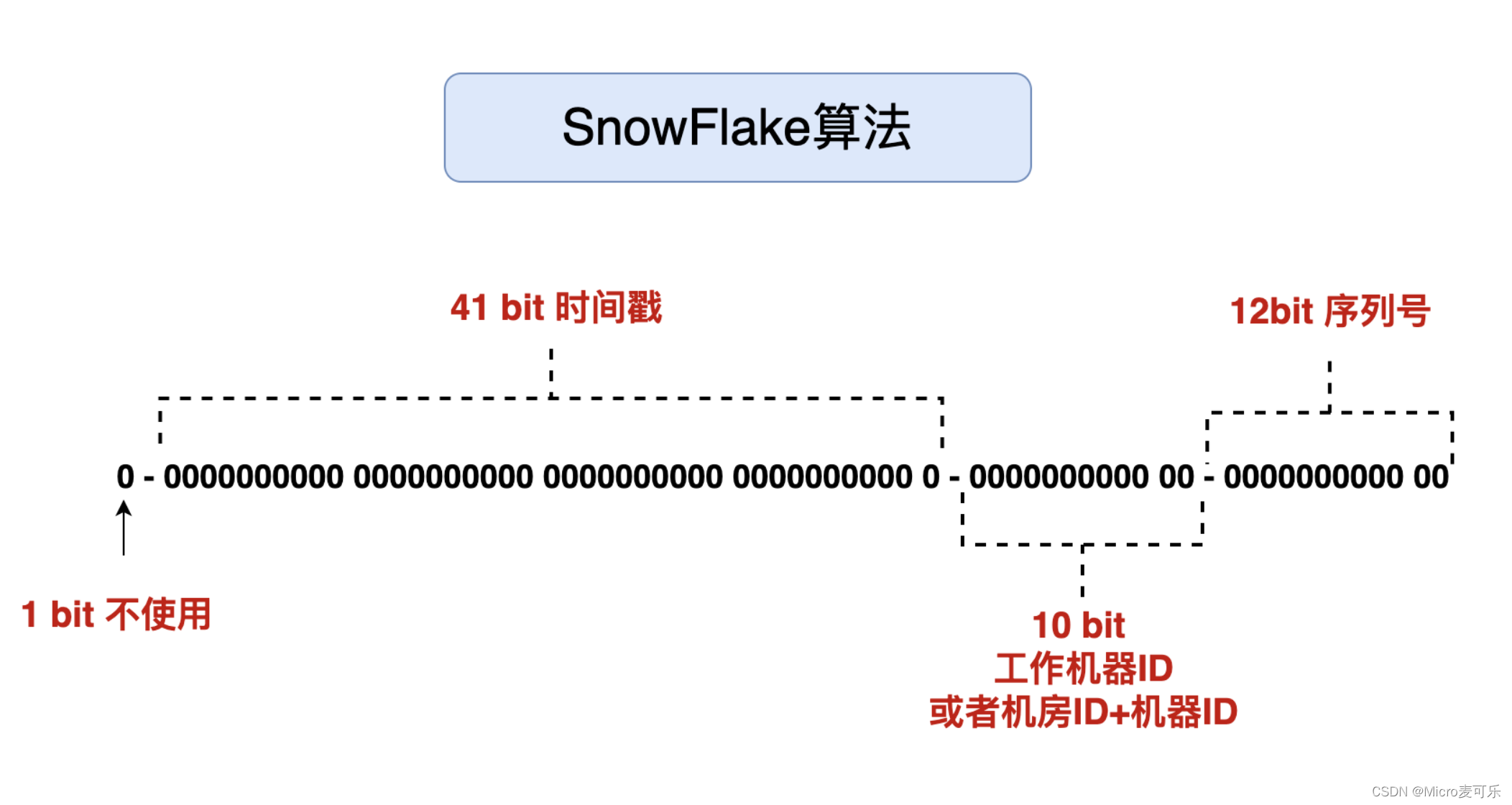
Snowflake算法的生成规则如下:
-
固定值(1位):占用1bit,其值始终是0,可看做是符号位不使用。
-
时间戳部分(41位): 用来记录生成ID的时间戳,精确到毫秒。这意味着Snowflake可以使用69年。
-
机器ID部分(10位): 用来标识机器,可以部署在2^10台机器上。
-
序列号部分(12位): 用来标识同一毫秒内产生的不同ID,支持同一机器同一毫秒内生成4096个ID。
雪花结构如下图
Snowflake算法的优点
Snowflake算法的优点:
-
唯一性: Snowflake算法生成的ID在分布式环境中具有唯一性,通过合理的配置,可以避免ID冲突问题。
-
趋势递增: 由于Snowflake算法使用时间戳作为基础,生成的ID呈趋势递增,便于数据库索引,有利于提高数据库性能。
-
高性能: Snowflake算法的实现简单,性能较高,适用于大规模分布式系统。
-
分布式: Snowflake算法天生支持分布式部署,适用于需要在多个节点生成唯一ID的场景。
-
可定制性: Snowflake算法的位数分配是可以根据实际需求进行调整的,可以根据业务规模进行定制。
Snowflake算法的缺点:
-
依赖系统时钟: Snowflake算法的唯一性依赖于系统时钟的单调递增,如果系统时钟回拨,可能导致生成的ID不唯一。
-
时钟回拨问题: 如果系统发生时钟回拨,可能会导致生成的ID不是趋势递增的,影响数据库性能。
-
有一定的时延: Snowflake算法生成ID时需要依赖当前时间戳,可能会有一定的时延。
-
不适用于短时间内需要大量生成ID的场景: 在短时间内需要大量生成ID的场景下,可能会出现ID的序列号用尽的情况。
-
对机器时钟要求较高: 如果机器之间的时钟差异较大,可能会导致生成的ID不唯一。
在使用Snowflake算法时,需要根据具体业务场景综合考虑其优缺点,确保在分布式环境中生成唯一且趋势递增的ID。
Snowflake算法Java代码实现
以下是一个简单的Java实现示例:
public class SnowflakeIdGenerator {
private final long twepoch = 1288834974657L; // 起始时间戳,可以根据实际情况调整
private final long workerIdBits = 5L;
private final long dataCenterIdBits = 5L;
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
private final long sequenceBits = 12L;
private final long workerIdShift = sequenceBits;
private final long dataCenterIdShift = sequenceBits + workerIdBits;
private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
private long workerId;
private long dataCenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long dataCenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");
}
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException("Datacenter ID can't be greater than " + maxDataCenterId + " or less than 0");
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) + " milliseconds");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) |
(dataCenterId << dataCenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 示例用法
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);
for (int i = 0; i < 10; i++) {
long id = idGenerator.nextId();
System.out.println("Generated ID: " + id);
}
}
}
Snowflake算法使用注意事项
时间回拨问题
如果系统时间发生回拨,可能会导致生成的ID不唯一。因此,在使用Snowflake算法时要确保系统时间是单调递增的。
机器ID和数据中心ID:
在部署时,要确保不同的机器和数据中心分配不同的ID,避免产生重复的ID。
性能
Snowflake算法依赖于系统时钟,如果系统时钟频繁变动,可能会影响性能。
结语
Snowflake算法是一种简单而高效的分布式唯一ID生成方案,广泛应用于分布式系统中。通过合理配置机器ID和数据中心ID,以及注意时间回拨问题,我们可以确保Snowflake算法生成的ID在分布式环境中的唯一性。在实际应用中,可以根据业务需求进行适当的调整和定制
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!