Python爬虫实战(进阶篇)—8获取TOP电影信息并存入Excel(附完整代码)
2023-12-13 12:56:18
文章目录
专栏导读
🔥🔥本文已收录于《Python基础篇爬虫》
🉑🉑本专栏专门
针对于有爬虫基础准备的一套基础教学,轻松掌握Python爬虫,欢迎各位同学订阅,专栏订阅地址:点我直达
🤞🤞此外如果您已工作,如需利用Python解决办公中常见的问题,欢
迎订阅《Python办公自动化》专栏,订阅地址:点我直达
的
🔺🔺此外《Python30天从入门到熟练》专栏已上线,欢迎大家订阅,订阅地址:点我直达
背景
-
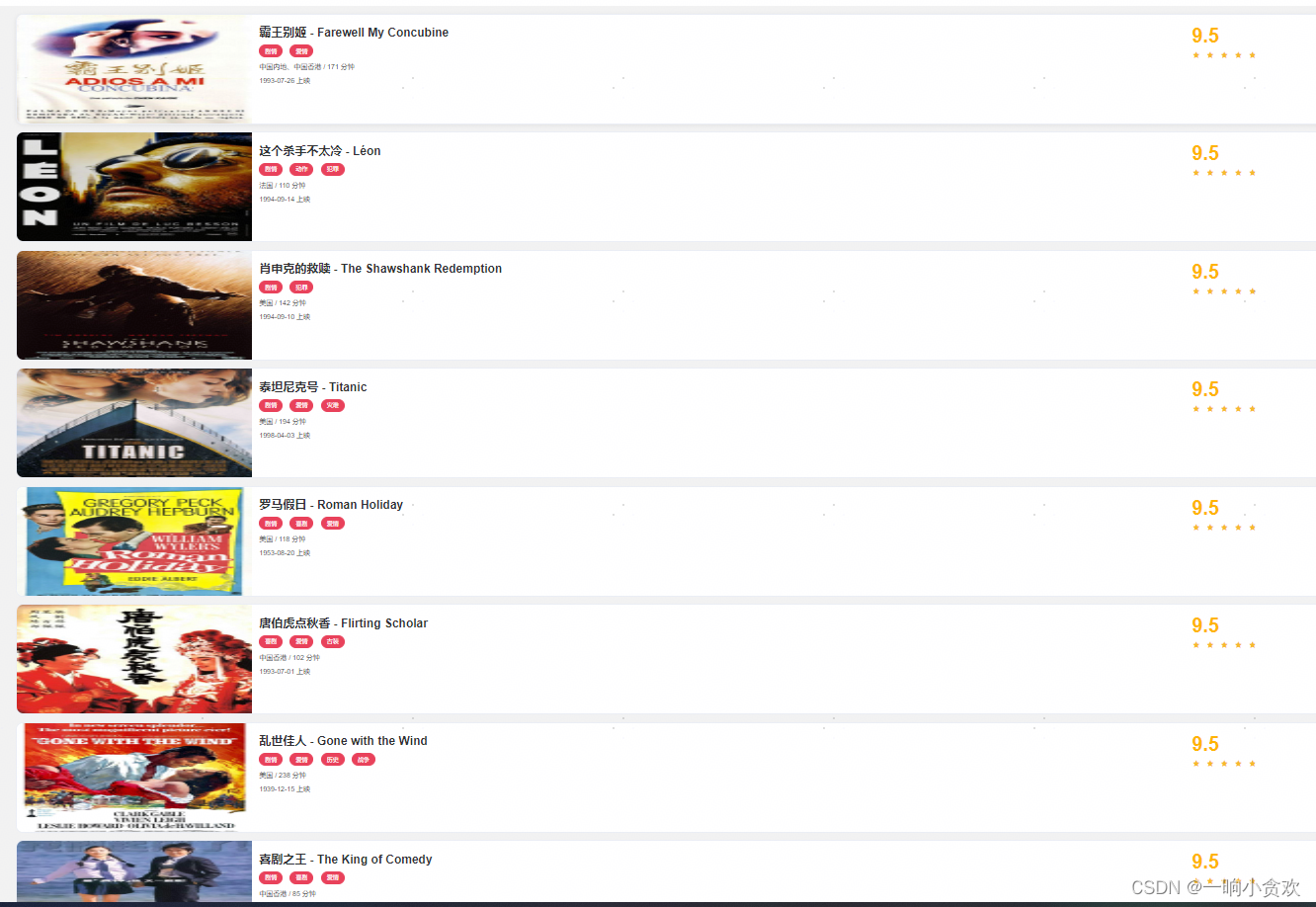
由于我是一个电影爱好者,我想知道有哪些高评分有意义的好电影我想观看他们从中获取一些人生感知,但是我不想去搜索,我想将他们总结下来,存入Excel这样我可以一部一部的看。
1、前期准备
网址
-
网址:https://ssr1.scrape.center/page/1
2、 请求URL\请求参数\请求方法
-
请求URL:https://ssr1.scrape.center/page/1
-
请请求参数:无
-
请求方法:GET
3、代码测试
-
代码
url = 'https://ssr1.scrape.center/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,headers=headers)
print(res_data.text)
请求成功
4、清洗数据
标题分析
-
所有的标题都在一个h2标签里,class属性为:class="m-b-sm"

利用库【lxml】+【xpath】提取
-
代码
import requests
from lxml import etree
url = 'https://ssr1.scrape.center/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,headers=headers)
tree = etree.HTML(res_data.text)
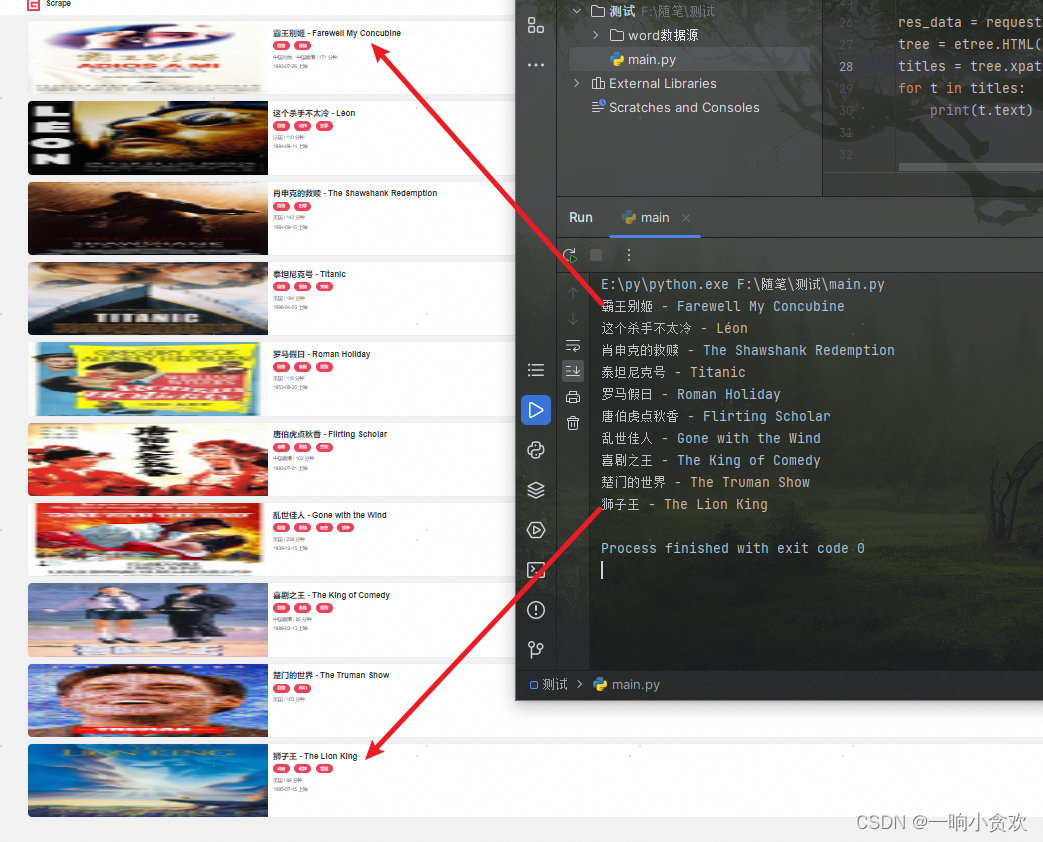
titles = tree.xpath('//h2[@class="m-b-sm"]')
for t in titles:
print(t.text)
提取成功!
提取【电影分类】、【上映地点】、【时长】、【上映时间】、【评分】
-
【电影分类】在classs属性为: class="el-button category el-button--primary el-button--mini"下的span标签里

-
但是如果你直接利用xpath获取的话如:【 //button[@class="el-button category el-button--primary el-button--mini"]//span】,这样会出问题,问题就是它会将所有的分类都输出出来,这样就会导致不知道每一部电影自己的分类,所以我们还要继续往上找标签,如下图
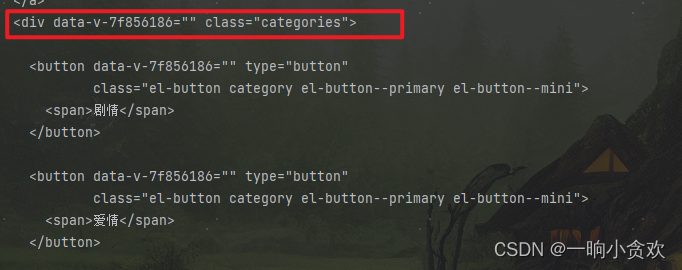
-
我们需要找到每一部电影的【 data-v-7f856186="" class="categories"】,然后利用每一页电影的数量去定位每一个该标签下的 class="el-button category el-button--primary el-button--mini"下的span标签,这样我们就完美的解决问题,代码如下
import requests
from lxml import etree
url = 'https://ssr1.scrape.center/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,headers=headers)
print(res_data.text)
tree = etree.HTML(res_data.text)
# titles = tree.xpath('//h2[@class="m-b-sm"]')
# for t in titles:
# print(t.text)
for i in range(1,11):
types = tree.xpath(f'(//div[@class="categories"])[{i}]//button[@class="el-button category el-button--primary el-button--mini"]//span')
for t in types:
print(t.text)
print('-'*30)

-
【上映地点】
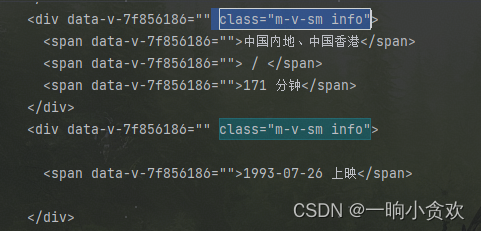
-
这里我们发现 div class属性为: class="m-v-sm info",下面有三个span,且还有一个相同的div
-
第一个span表示上映地点
-
第二个span 是空值 /
-
第三个span是电影时长
-
第四个span是上映时间
注意事项
-
如果我们直接提取上述【div class属性为: class="m-v-sm info",下面的三个span】将会出现一点小问题,问题就是我发现有的电影没有写【上映时间】,那么我们又只能往上找标签,能体现每一页电影数量,从数量(索引)定位每一个电影的三个【span】
解决方案
-
(//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"])[这里就是1-10]//div[@class="m-v-sm info"]//span
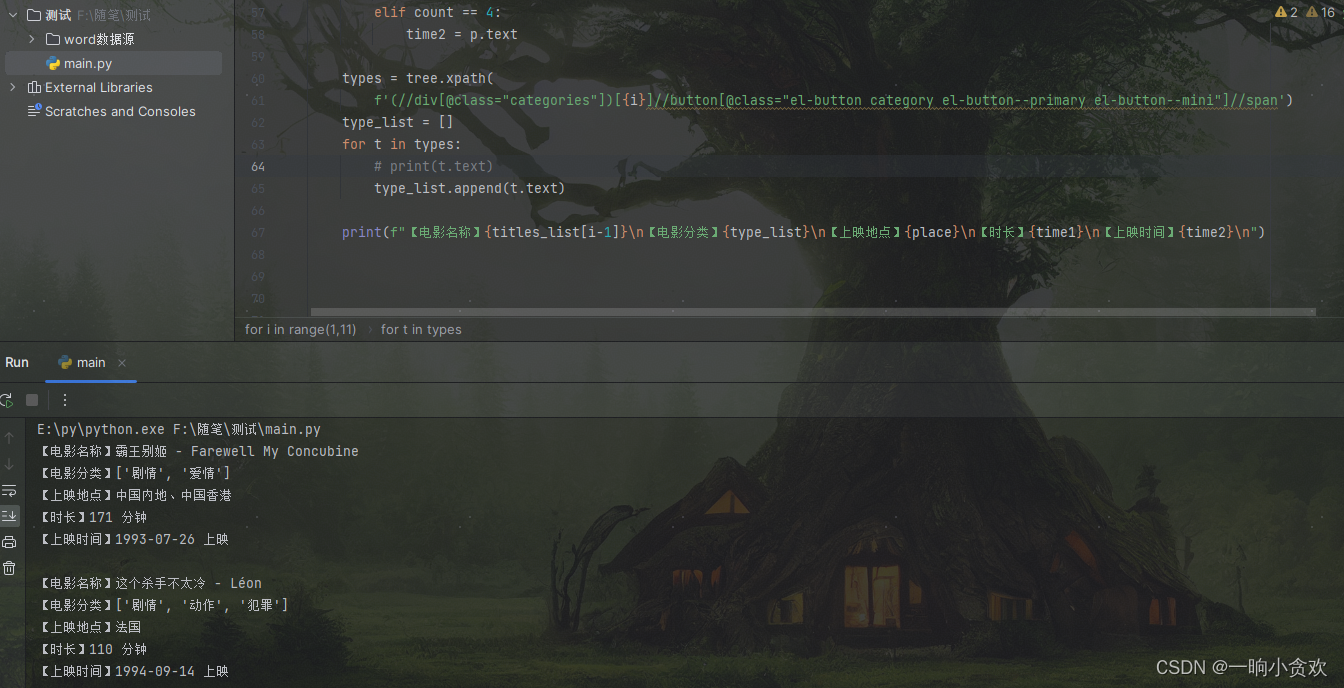
代码
import requests
from lxml import etree
url = 'https://ssr1.scrape.center/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Host': 'ssr1.scrape.center',
'Referer': 'https://ssr1.scrape.center/page/10',
}
res_data = requests.get(url=url,headers=headers)
# print(res_data.text)
tree = etree.HTML(res_data.text)
titles = tree.xpath('//h2[@class="m-b-sm"]')
titles_list = []
for t in titles:
# print(t.text)
titles_list.append(t.text)
for i in range(1,11):
places = tree.xpath(f'(//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"])[{i}]//div[@class="m-v-sm info"]//span')
place = ''
time1 = ''
time2 = ''
count = 0
for p in places:
count+=1
if count ==1:
place = p.text
elif count == 3:
time1 = p.text
elif count == 4:
time2 = p.text
types = tree.xpath(
f'(//div[@class="categories"])[{i}]//button[@class="el-button category el-button--primary el-button--mini"]//span')
type_list = []
for t in types:
# print(t.text)
type_list.append(t.text)
print(f"【电影名称】{titles_list[i-1]}\n【电影分类】{type_list}\n【上映地点】{place}\n【时长】{time1}\n【上映时间】{time2}\n")
-
【时长】与【上映地点】相同!
-
【上映时间】与【上映地点】相同!
【评分】数据提取(最后一步)
-
截至上一步我们基本上已经完成了代码的90%,还差最后一步的评分!,那我们分析一下评分的元素信息
-
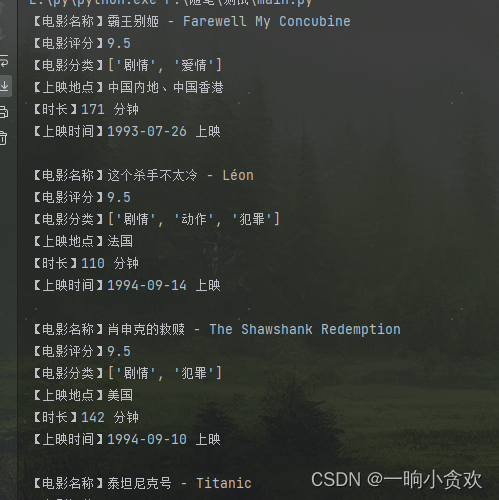
评分很简单,在一个class属性为:class="score m-t-md m-b-n-sm"的p标签里

-
提取成功
完整视频演示
完整代码+存入Excel
-
存入Excel,需要openpyxl库,没有的同学可以安装一下
-
安装指令:pip install openpyxl
# -*- coding: UTF-8 -*-
'''
@Project :测试
@File :main.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2023/12/12 16:00
'''
import time
import openpyxl
import requests
from lxml import etree
wb = openpyxl.Workbook()
ws = wb.active
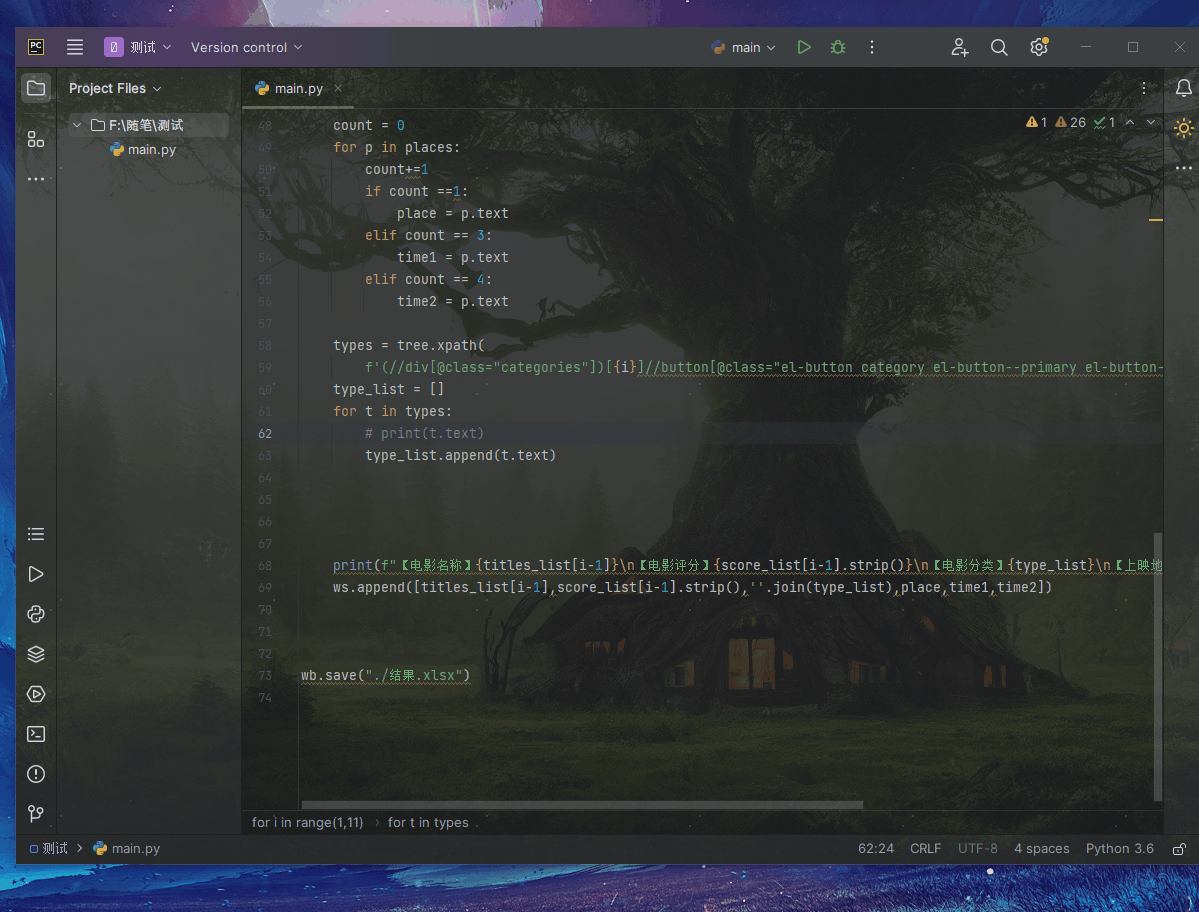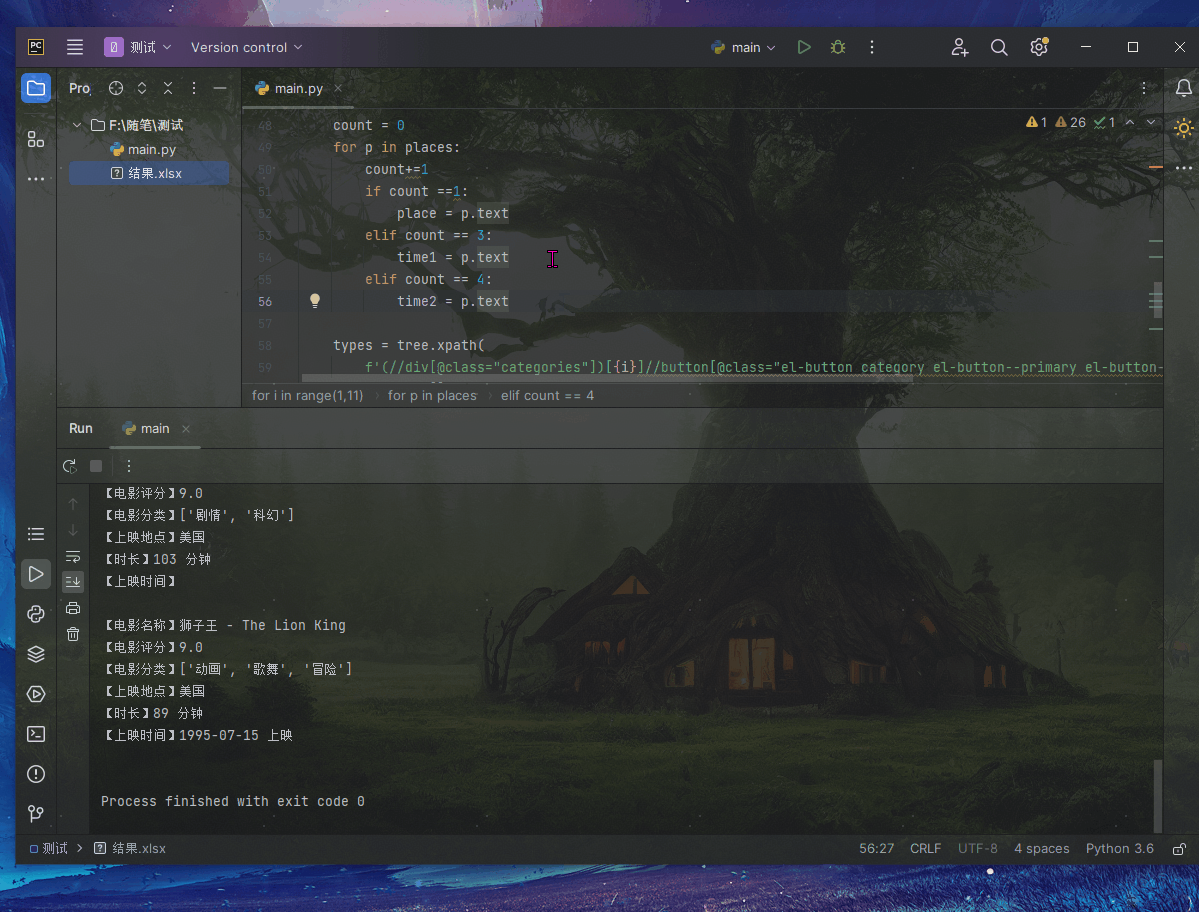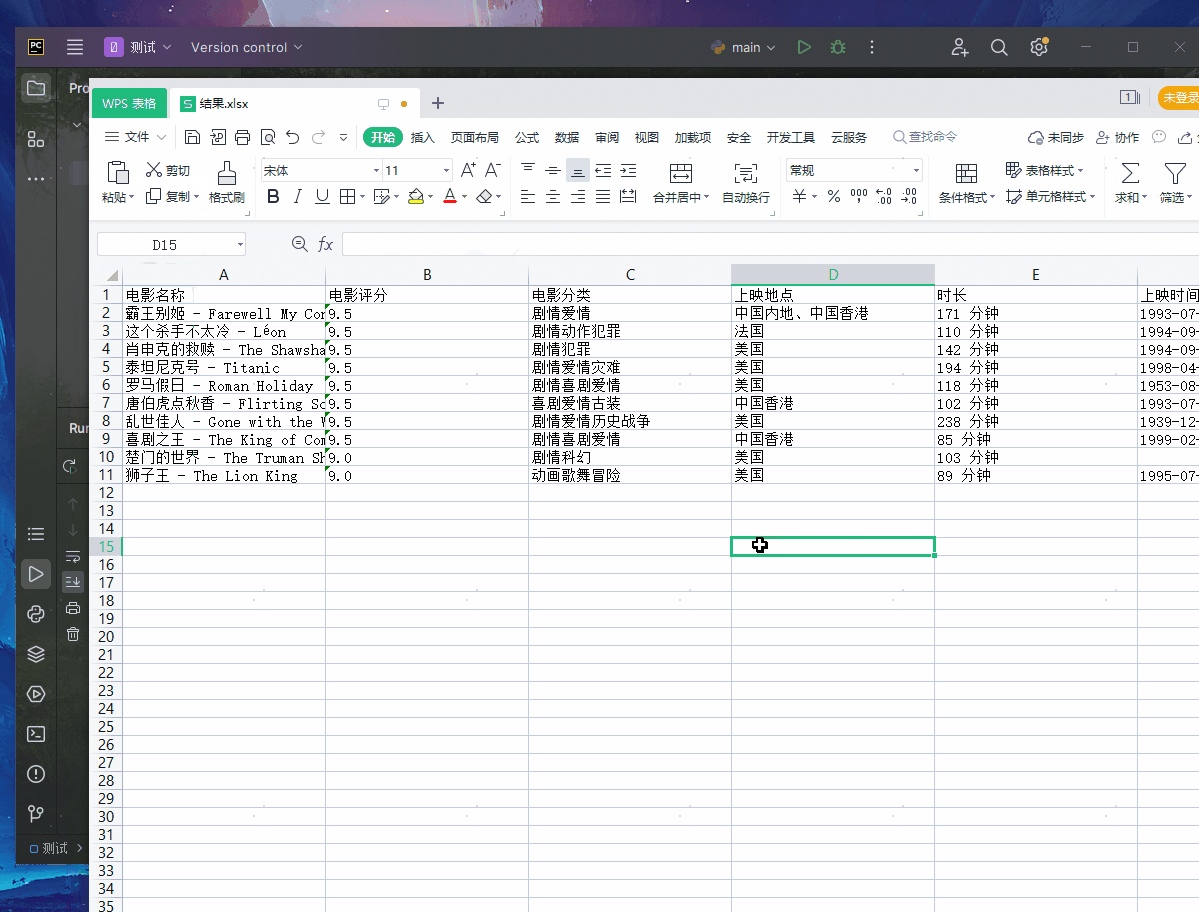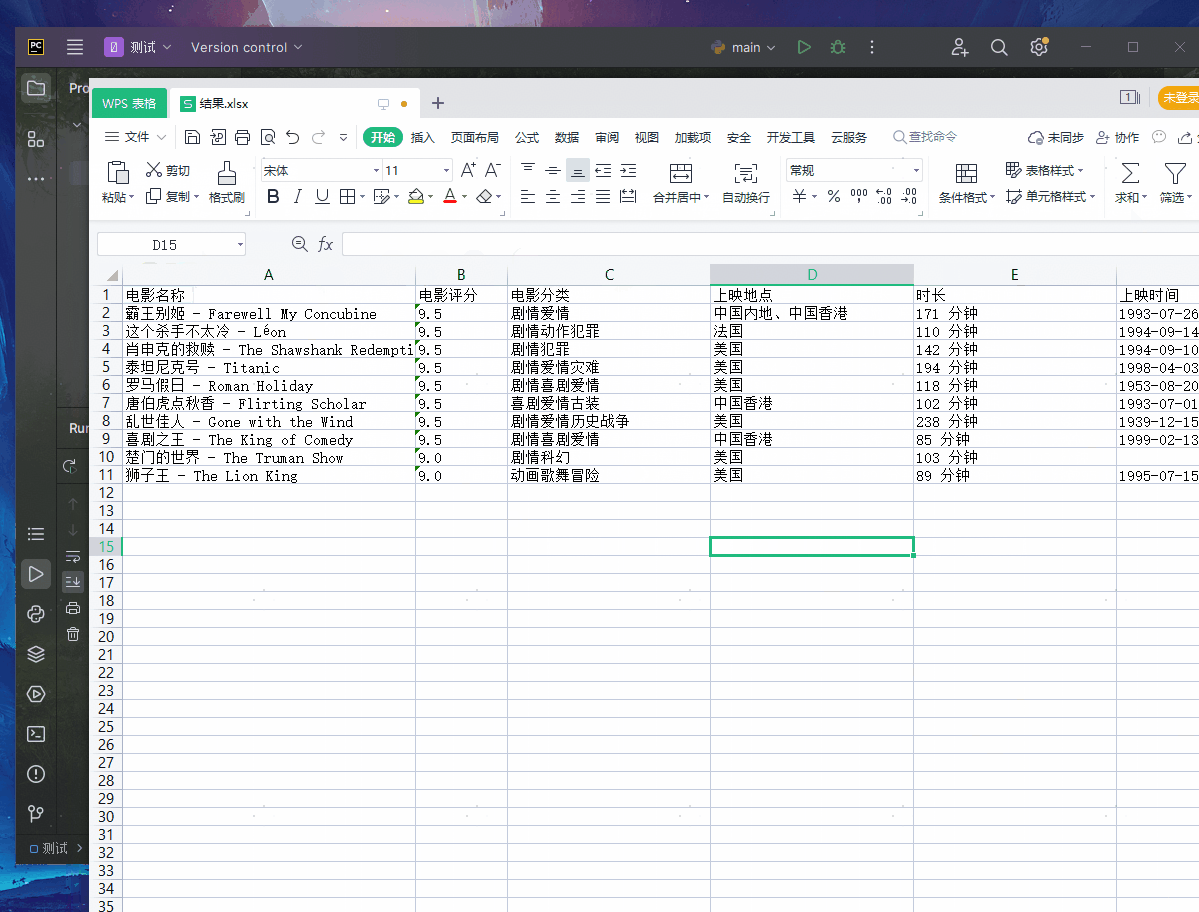
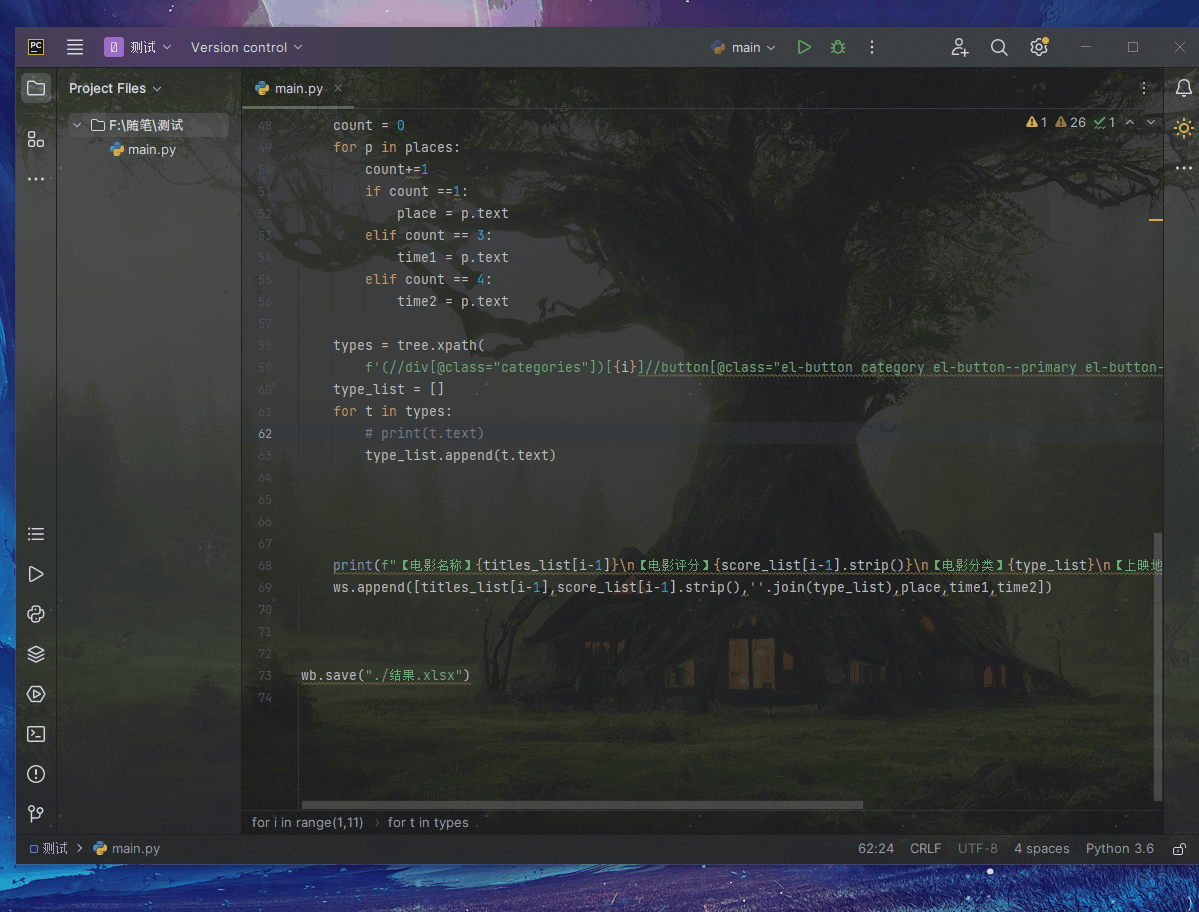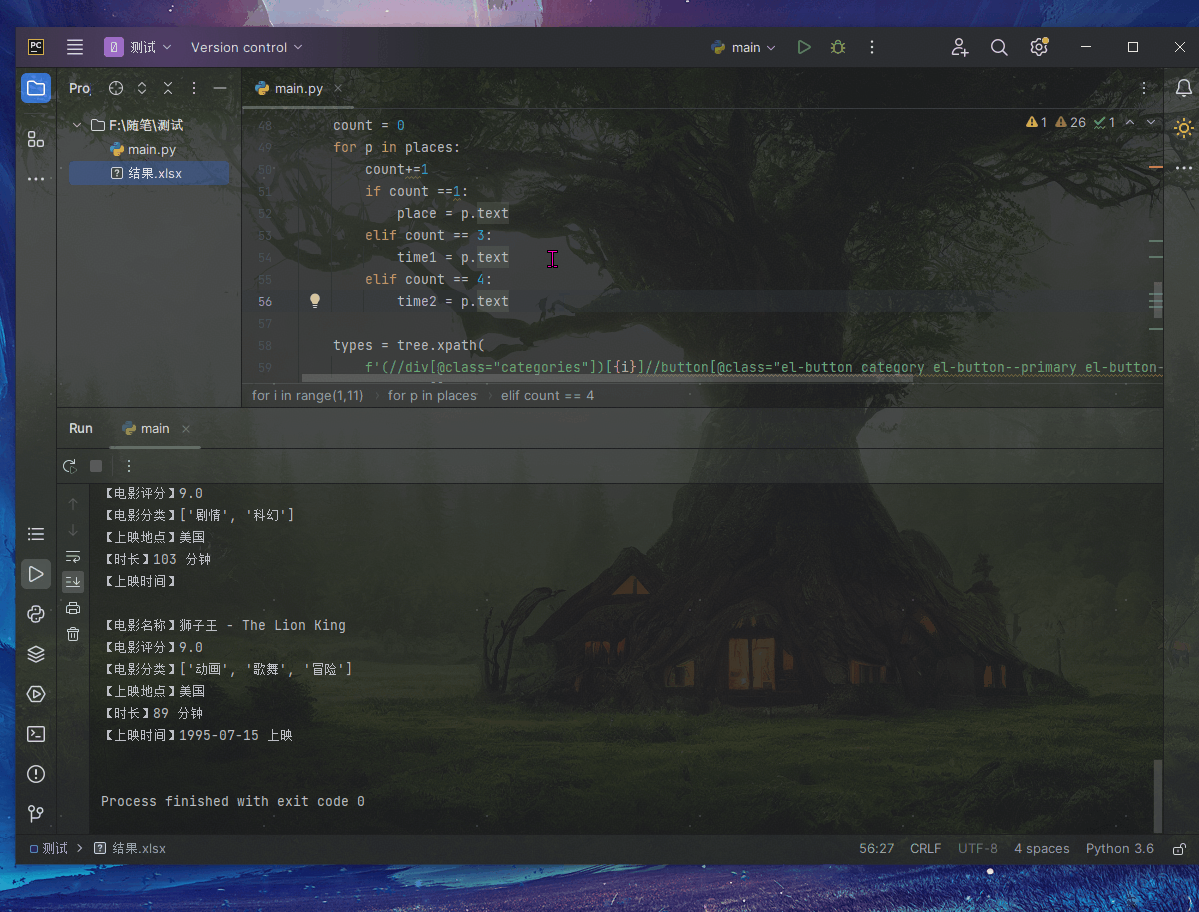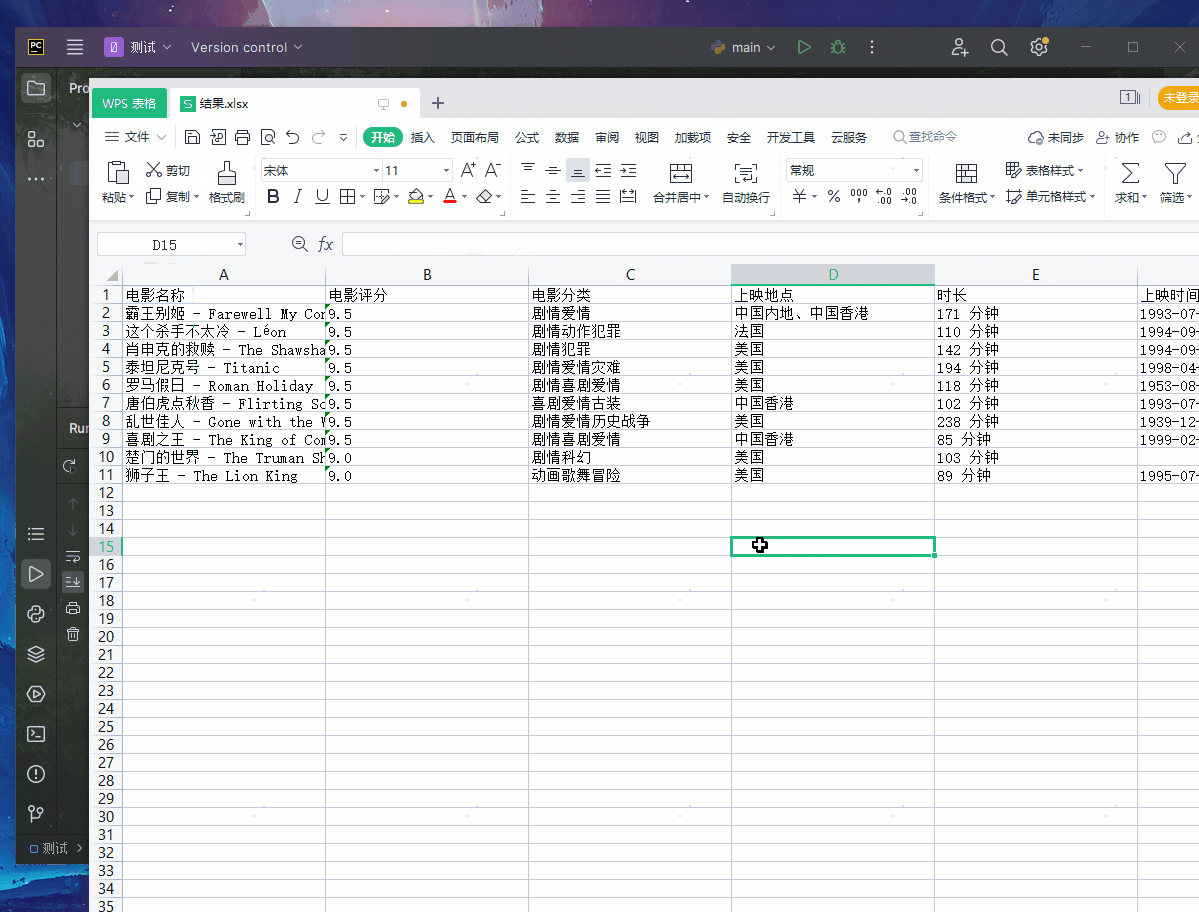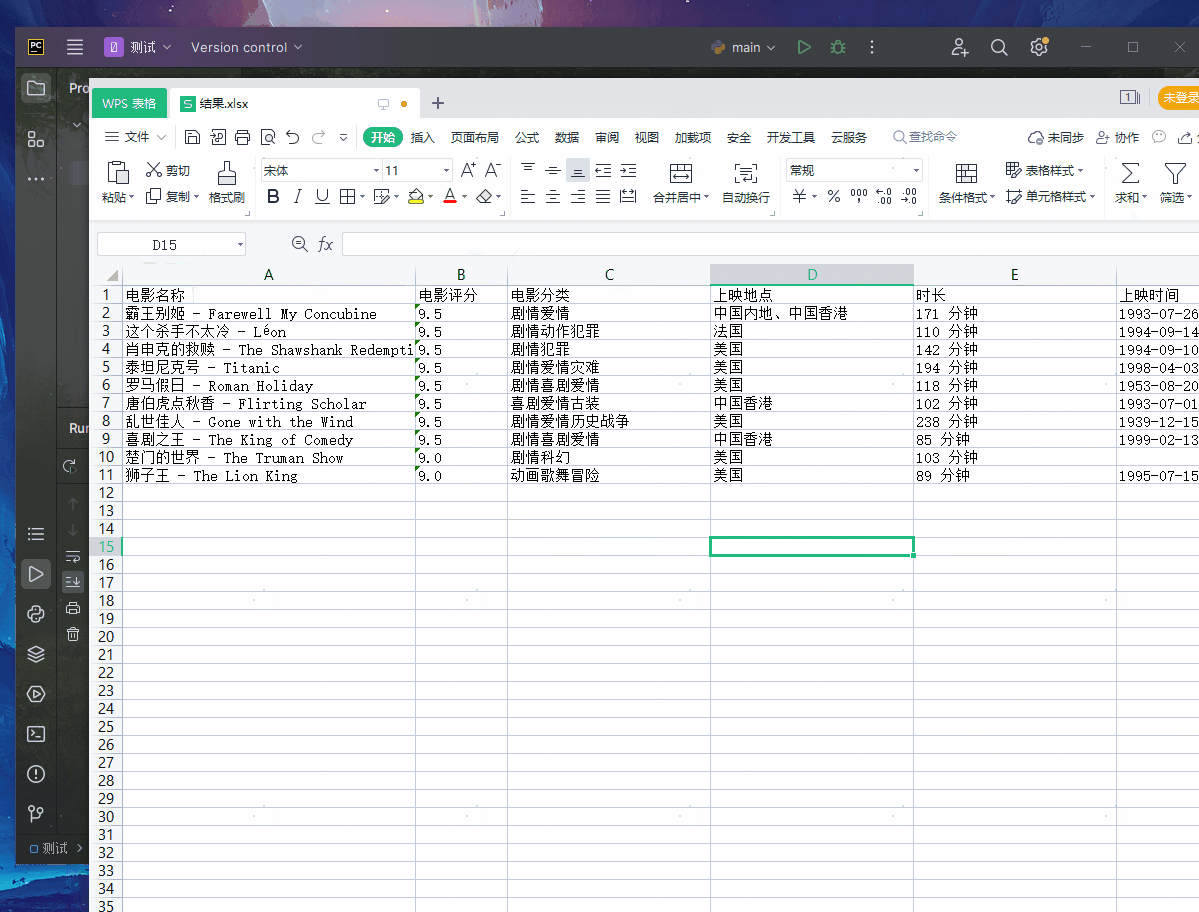
ws.append(['电影名称','电影评分','电影分类','上映地点','时长','上映时间'])
url = 'https://ssr1.scrape.center/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Host': 'ssr1.scrape.center',
'Referer': 'https://ssr1.scrape.center/page/10',
}
res_data = requests.get(url=url,headers=headers)
# print(res_data.text)
tree = etree.HTML(res_data.text)
titles = tree.xpath('//h2[@class="m-b-sm"]')
titles_list = []
for t in titles:
# print(t.text)
titles_list.append(t.text)
score_list = []
scores = tree.xpath(f'//p[@class="score m-t-md m-b-n-sm"]')
for s in scores:
score_list.append(s.text)
for i in range(1,11):
places = tree.xpath(f'(//div[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"])[{i}]//div[@class="m-v-sm info"]//span')
place = ''
time1 = ''
time2 = ''
count = 0
for p in places:
count+=1
if count ==1:
place = p.text
elif count == 3:
time1 = p.text
elif count == 4:
time2 = p.text
types = tree.xpath(
f'(//div[@class="categories"])[{i}]//button[@class="el-button category el-button--primary el-button--mini"]//span')
type_list = []
for t in types:
# print(t.text)
type_list.append(t.text)
print(f"【电影名称】{titles_list[i-1]}\n【电影评分】{score_list[i-1].strip()}\n【电影分类】{type_list}\n【上映地点】{place}\n【时长】{time1}\n【上映时间】{time2}\n")
ws.append([titles_list[i-1],score_list[i-1].strip(),''.join(type_list),place,time1,time2])
wb.save("./结果.xlsx")
总结
-
其实今天的代码前期真的非常简单,越往后写麻烦,麻烦的是数据清洗,就比如:上映地点、电影时长、上映时间都是相同的元素,而且还要分开!
-
不过总算完成了,希望大家一定要多多关注支持一下
-
希望大家多多点赞、多多收藏!!
-
后续会继续更新的!
-
今天知识获取了第一页的内容,后面的大家可以继续获取,还有电影封面大家也可以继续深入,就当作课后作业
文章来源:https://blog.csdn.net/weixin_42636075/article/details/134951745
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!