基于 Flink CDC 构建 MySQL 的 Streaming ETL to MySQL
简介
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛:
? 数据同步:用于备份,容灾;
? 数据分发:一个数据源分发给多个下游系统;
? 数据采集:面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
? 基于查询的 CDC:
? 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
? 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
? 不保障实时性,基于离线调度存在天然的延迟。
? 基于日志的 CDC:
? 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
? 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
? 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
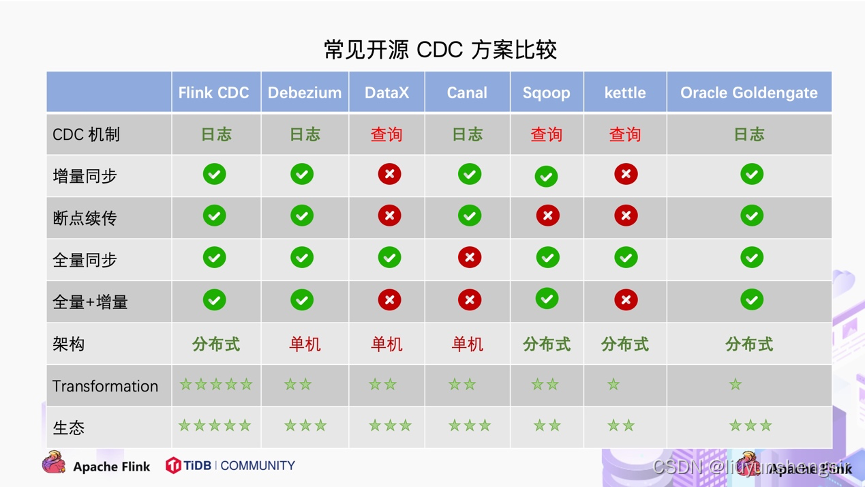
对比常见的开源 CDC 方案,我们可以发现:
? 对比增量同步能力,
? 基于日志的方式,可以很好的做到增量同步;
? 而基于查询的方式是很难做到增量同步的。
? 对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
? 而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
? 从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
? 在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
? 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
? 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
? 另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
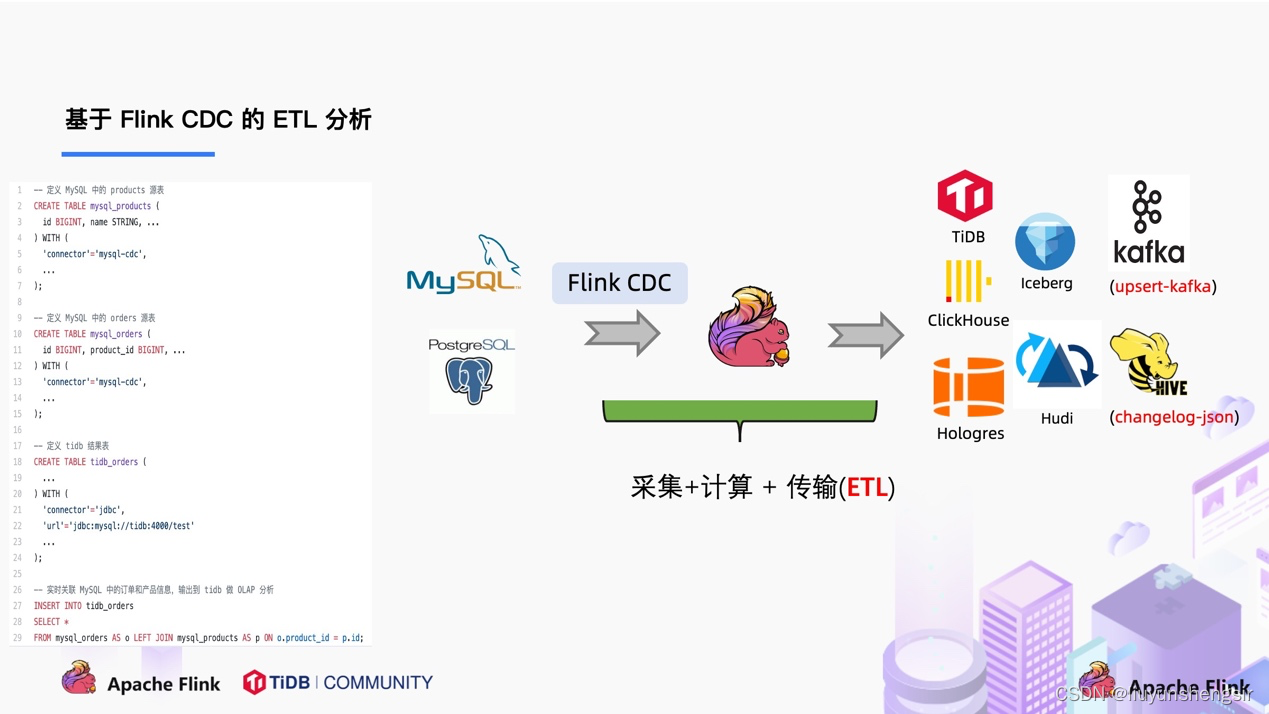
1.安装单机版
下载
yum install -y java-1.8.0-openjdk.x86_64
yum install -y java-1.8.0-openjdk-devel
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz
mkdir -p /opt/flink
tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /opt/flink
下载jar复制到/opt/flink/flink-1.17.2/lib
<!-- https://mvnrepository.com/artifact/com.ververica/flink-sql-connector-mysql-cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.4.2</version>
<scope>provided</scope>
</dependency>
配置
vim /opt/flink/flink-1.17.2/conf/flink-conf.yaml
rest.port: 8081
rest.bind-address: 0.0.0.0
jobmanager.execution.timezone: Asia/Shanghai
启动
/opt/flink/flink-1.17.2/bin/stop-cluster.sh
/opt/flink/flink-1.17.2/bin/start-cluster.sh
访问http://10.6.8.227:8081/
2.创建 两个mysql 数据库
docker run -p 13306:3306 \
-e MYSQL_ROOT_PASSWORD=mysql \
-d mysql
docker run -p 23306:3306 \
-e MYSQL_ROOT_PASSWORD=mysql \
-d mysql
初始化mysql 表结构
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
在源库中插入数据
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
3.CDC 步骤
启动 /opt/flink/flink-1.17.2/bin/sql-client.sh
只能一条语句一条语句的执行
CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '13306',
'username' = 'root',
'password' = 'mysql',
'database-name' = 'mydb',
'table-name' = 'products'
);
CREATE TABLE sink_products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:23306/mydb?serverTimezone=Asia/Shanghai',
'username' = 'root',
'password' = 'mysql',
'table-name' = 'sink_products'
);
insert into sink_products select * from products;
4.验证
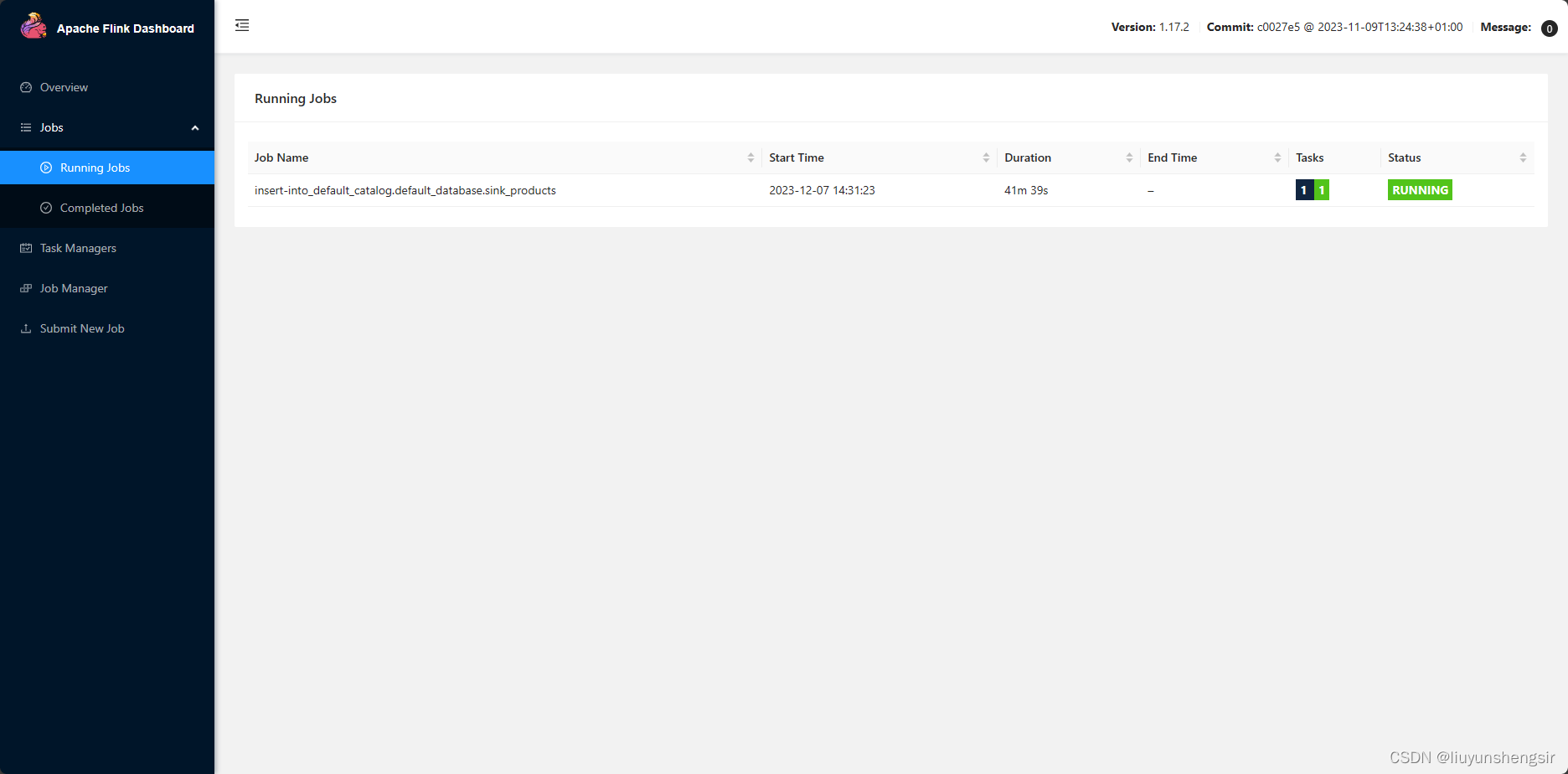
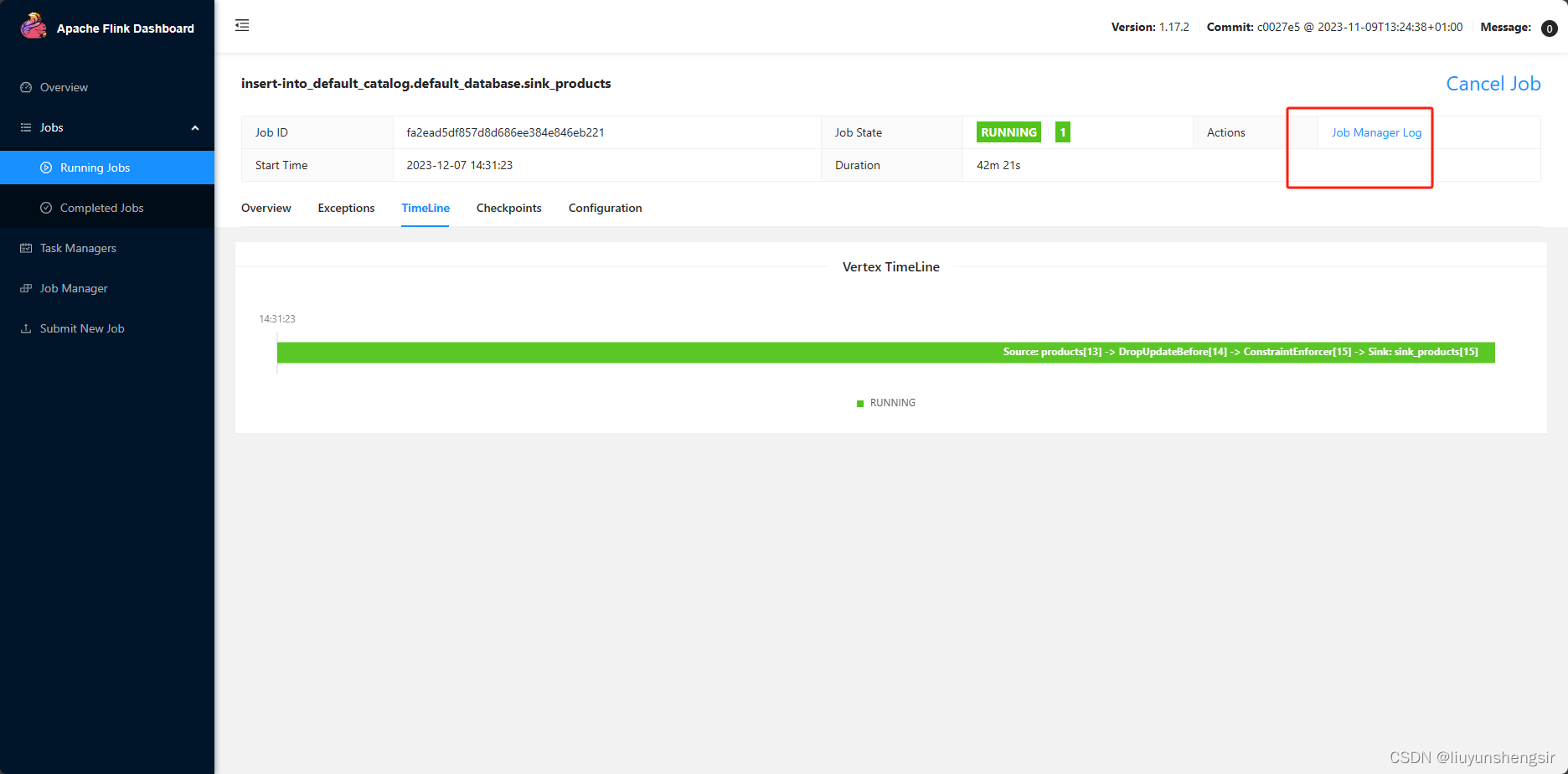

参考文档
http://124.220.104.235/web/chatgpt
https://ververica.github.io/flink-cdc-connectors/master/content/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B/mysql-postgres-tutorial-zh.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!