深度优先和广度优先
2023-12-30 12:34:01
前言
深度优先和广度优先的区别:
- 搜索方式不同 。深度优先搜索算法不全部保留结点,扩展完的结点从数据库中弹出删去;广度优先搜索算法需存储产生的所有结点。
- 运行速度不同 。深度优先搜索算法有回溯操作,运行速度慢;广度优先搜索算法无回溯操作,运行速度快。
- 占用空间不同 。深度优先搜索算法占用空间少;广度优先搜索算法占用空间大。
- 作用不同。虽然都可以完成树形结构的遍历,但是深度优先一般用于需要先处理最深层级逻辑,广度优先一般用于层层节点展开的处理逻辑;
一、深度和广度的区别
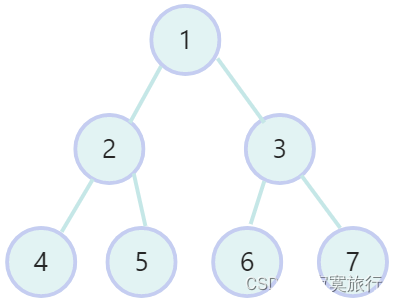
- 深度优先: 1>3>7>6>2>5>4
- 广度优先: 1>2>3>4>5>6>7
二、代码演示
1.准备数据,构造树
代码如下(示例):
public class MainUtil2 {
public static void main(String[] args) throws Exception {
// 获取demo 数据
List<AuthMenuTree> list = getList();
// 变为树
List<AuthMenuTree> res = getChildrenStream(0, list);
System.out.println(JSONUtil.toJsonStr(res));
}
private static List<AuthMenuTree> getChildrenStream(int i, List<AuthMenuTree> list) {
return list.stream().filter(authMenuTree -> authMenuTree.getMenuPid() == i)
.peek(authMenuTree -> authMenuTree.setChildren(getChildrenStream(authMenuTree.getId(), list)))
.collect(Collectors.toList());
}
public static List<AuthMenuTree> getList() {
List<AuthMenuTree> objects = CollectionUtil.newArrayList();
objects.add(new AuthMenuTree(0, 1));
objects.add(new AuthMenuTree(1, 2));
objects.add(new AuthMenuTree(1, 3));
objects.add(new AuthMenuTree(2, 4));
objects.add(new AuthMenuTree(2, 5));
objects.add(new AuthMenuTree(3, 6));
objects.add(new AuthMenuTree(3, 7));
return objects;
}
}
2.深度优先遍历
代码如下(示例):
public static void main(String[] args) throws Exception {
// 获取demo 数据
List<AuthMenuTree> list = getList();
// 变为树
List<AuthMenuTree> res = getChildrenStream(0, list);
List<String> result = new ArrayList<>(res.size());
AuthMenuTree root = res.get(0);
// 深度优先 用栈
Stack<AuthMenuTree> stack = new Stack<>();
AuthMenuTree head;
// 入栈
stack.add(root);
// 出栈
while (!stack.isEmpty() && (head = stack.pop()) != null) {
if (!ObjectUtils.isEmpty(head.getChildren())) {
// 子类入栈
stack.addAll(head.getChildren());
}
// 添加到顺序结果集中
result.add(head.getId().toString());
}
System.out.println(JSONUtil.toJsonStr(result));
}
打印结果: [“1”,“3”,“7”,“6”,“2”,“5”,“4”]
3.广度优先遍历
代码如下(示例):
public static void main(String[] args) throws Exception {
// 获取demo 数据
List<AuthMenuTree> list = getList();
// 变为树
List<AuthMenuTree> res = getChildrenStream(0, list);
List<String> result = new ArrayList<>(res.size());
AuthMenuTree root = res.get(0);
// 广度优先 用队列
Queue<AuthMenuTree> treeQueue = new LinkedList<>();
AuthMenuTree head;
treeQueue.offer(root);
while ((!treeQueue.isEmpty()) && (head = treeQueue.poll()) != null) {
if (!ObjectUtils.isEmpty(head.getChildren())) {
treeQueue.addAll(head.getChildren());
}
result.add(head.getId().toString());
}
System.out.println(JSONUtil.toJsonStr(result));
}
打印结果: [“1”,“2”,“3”,“4”,“5”,“6”,“7”]
总结
深度优先 用栈;广度优先 用队列;
文章来源:https://blog.csdn.net/qq_32419139/article/details/135191649
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!