【PostgreSQL内核学习(十九)—— 存储管理(元组操作)】
元组操作
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书以及一些相关参考资料。此外,本文所参考的源码为OpenGauss1.1.0
概述
??对元组的操作包括插入、删除和更新三种基本操作,这三种操作都是把元组当作一个整体进行处理。除些之外,在 heaptuple.cpp(OG 中) 这个文件中还实现了元组内部结构的相关操作,包括元组的构造修改、分解、复制、释放等作。
??一个完整的元组信息将对应一个 HeapTupleData 结构和一个 TupleDesc 结构,在 HeapTupleData中还包含一个 HeapTupleHeaderData 结构。TupleDesc 是关系结构 RelationData 的一部分,也称为元组描述符,它记录了与该元组相关的全部属性模式信息。通过元组描述符可以读取磁盘中存储的无格式数据,并根据元组描述符构造出元组的各个属性值,元组描述符的结构如下所示(路径:src\include\access\tupdesc.h)。
typedef struct tupleDesc {
TableAmType tdTableAmType; /* 表访问器方法的索引,用于访问单个TableAccessorMethods上的方法 */
int natts; /* 元组中属性的数量 */
bool tdisredistable; /* 由redis工具创建的用于数据重分布的临时表 */
Form_pg_attribute* attrs; /* attrs[N]是指向第N+1个属性描述的指针 */
TupleConstr* constr; /* 约束,如果没有则为NULL */
TupInitDefVal* initdefvals; /* 由于添加列而引起的初始化默认值 */
Oid tdtypeid; /* 元组类型的复合类型ID */
int32 tdtypmod; /* 元组类型的typmod */
bool tdhasoid; /* 元组在其标头中是否具有oid属性 */
int tdrefcount; /* 引用计数,如果不计数则为-1 */
} * TupleDesc;
??一个完整的元组信息对应一个 HeapTupleData 与一个 TupleDesc,tupleDesc 包含了关于元组描述的信息,每一行的注释解释了结构体中的每个字段的用途和含义。这个结构体通常用于数据库系统中来描述数据库表中的元组(行)的结构和属性。而 HeapTupleData 是元组在内存中的拷贝,它是磁盘格式的元组读入内存后的存在方式,HeapTupleData 的结构如下所示(路径:src\include\access\htup.h)。
struct HeapTupleData;
typedef HeapTupleData* HeapTuple;
typedef struct HeapTupleData {
uint1 tupTableType = HEAP_TUPLE; /* 元组的表类型,通常为HEAP_TUPLE */
int2 t_bucketId; /* 元组的桶ID */
uint32 t_len; /* t_data数据的长度 */
ItemPointerData t_self; /* SelfItemPointer,指向元组自身的指针 */
Oid t_tableOid; /* 元组所属的表的OID */
TransactionId t_xid_base; /* 事务ID的基数(基础事务ID) */
TransactionId t_multi_base; /* 多事务ID的基数 */
#ifdef PGXC
uint32 t_xc_node_id; /* 元组来自的数据节点ID(仅限于PGXC) */
#endif
HeapTupleHeader t_data; /* 指向元组头和数据的指针 */
} HeapTupleData;
??HeapTupleData 结构体中包含一个 HeapTupleHeaderData 类型的字段 t_data,该字段指向元组的头部信息。这种组合允许数据库系统在需要时访问元组的头部信息和数据,以执行操作,如插入、更新、删除或检索元组。HeapTupleData 结构体定义如下所示(路径:src\include\access\htup.h)。
typedef struct HeapTupleHeaderData {
union {
HeapTupleFields t_heap; /* 堆元组字段(通常用于普通表) */
DatumTupleFields t_datum; /* 数据元组字段(通常用于外部数据表) */
} t_choice;
ItemPointerData t_ctid; /* 当前元组的TID或更新的TID */
/* 以下字段必须与MinimalTupleData匹配! */
uint16 t_infomask2; /* 属性数量 + 各种标志 */
uint16 t_infomask; /* 各种标志位,见下文说明 */
uint8 t_hoff; /* 头部大小,包括位图和填充 */
/* ^ - 23 字节 - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* NULL位图 -- 可变长度 */
/* 后续还有更多数据 */
} HeapTupleHeaderData;
typedef HeapTupleHeaderData* HeapTupleHeader;
??这里书中写到:“在数据结构中并没有出现存储元组实际数据的属性,这是因为 PostgreSQL (OG 可以理解为 PG 的一个分支)通过编程技巧,巧妙地将元组的实际数据存放在 HeapTupleHeaderData 结构后面的空间中。怎么理解呢?让我们来详细解释一下:
- 数据结构的布局:在 PostgreSQL 中,HeapTupleHeaderData 结构用于存储有关元组的元数据信息,比如它的长度、状态信息、时间戳等。这个结构体本身并不包含元组的实际数据(即字段值)。
- 紧密排列的内存布局: PostgreSQL 的设计者采用了一种编程技巧,即在内存中将 HeapTupleHeaderData 结构和元组的实际数据紧密排列在一起。这意味着元组的实际数据紧跟在 HeapTupleHeaderData 结构的内存表示之后。
- 没有显式指针: 在 HeapTupleHeaderData 结构中,通常不会有一个显式的指针来指向元组的数据部分。相反,数据紧随元组头部结构存储。这意味着一旦你有了指向 HeapTupleHeaderData 的指针,你可以通过计算偏移量来访问实际的数据。
- 优势: 这种方法的优势在于效率和简洁性。它减少了额外的指针解引用和内存分配,从而提高了数据访问的效率。同时,这种布局也使得数据的存储更加紧凑,减少了内存占用。
- 访问数据: 为了访问元组的实际数据,程序通常会基于 HeapTupleHeaderData 结构的大小和其他元数据计算出数据开始的确切位置。这种方法在数据库系统中相对常见,因为它允许灵活地处理不同大小和格式的数据。
??内存布局看起来可能像这样:
+------------------+------------------+
| HeapTupleHeader | Tuple Data |
| (24 bytes) | (14 bytes) |
+------------------+------------------+
| Metadata... | id (4 bytes) |
| (status, length, | name (10 bytes) |
| timestamps...) | |
+------------------+------------------+
??在这个布局中,HeapTupleHeaderData 结构占据前 24 个字节,紧接着是实际的数据:先是 4 字节的 id,然后是 10 字节的 name。
插入元组
heap_form_tuple 函数
??在插入元组之前,我们首先要根据元组内数据和描述符等信息初始化 HeapTuple 结构,函数 heap_form_tuple 实现了这一功能。函数源码如下所示:(路径:src\gausskernel\storage\access\common\heaptuple.cpp)
/*
* heap_form_tuple
* 构造一个元组,基于给定的 values[] 和 isnull[] 数组,
* 这些数组的长度由 tupleDescriptor->natts 指示
*
* 结果在当前内存上下文中分配。
*/
HeapTuple heap_form_tuple(TupleDesc tupleDescriptor, Datum *values, bool *isnull) {
HeapTuple tuple; /* 返回的元组 */
HeapTupleHeader td; /* 元组数据的头部 */
Size len, data_len;
int hoff;
bool hasnull = false;
Form_pg_attribute *att = tupleDescriptor->attrs;
int numberOfAttributes = tupleDescriptor->natts;
int i;
/* 检查属性数量是否超过最大限制 */
if (numberOfAttributes > MaxTupleAttributeNumber) {
ereport(ERROR, (errcode(ERRCODE_TOO_MANY_COLUMNS), errmsg("number of columns (%d) exceeds limit (%d)",
numberOfAttributes, MaxTupleAttributeNumber)));
}
/* 检查空值和嵌入式元组;展开嵌入式元组中的任何压缩属性。 */
for (i = 0; i < numberOfAttributes; i++) {
if (isnull[i]) {
hasnull = true;
} else if (att[i]->attlen == -1 && att[i]->attalign == 'd' && att[i]->attndims == 0 &&
!VARATT_IS_EXTENDED(DatumGetPointer(values[i]))) {
values[i] = toast_flatten_tuple_attribute(values[i], att[i]->atttypid, att[i]->atttypmod);
}
}
/* 确定所需的总空间 */
len = offsetof(HeapTupleHeaderData, t_bits);
if (hasnull) {
len += BITMAPLEN(numberOfAttributes);
}
if (tupleDescriptor->tdhasoid) {
len += sizeof(Oid);
}
hoff = len = MAXALIGN(len); /* 安全地对齐用户数据 */
data_len = heap_compute_data_size(tupleDescriptor, values, isnull);
len += data_len;
/* 分配并清零所需空间。注意,元组主体和 HeapTupleData 管理结构在一个块中分配。 */
tuple = (HeapTuple)heaptup_alloc(HEAPTUPLESIZE + len);
tuple->t_data = td = (HeapTupleHeader)((char *)tuple + HEAPTUPLESIZE);
/* 填写信息。即使这个元组可能永远不会成为 Datum,也填写 Datum 字段。 */
tuple->t_len = len;
ItemPointerSetInvalid(&(tuple->t_self));
tuple->t_tableOid = InvalidOid;
tuple->t_bucketId = InvalidBktId;
HeapTupleSetZeroBase(tuple);
#ifdef PGXC
tuple->t_xc_node_id = 0;
#endif
HeapTupleHeaderSetDatumLength(td, len);
HeapTupleHeaderSetTypeId(td, tupleDescriptor->tdtypeid);
HeapTupleHeaderSetTypMod(td, tupleDescriptor->tdtypmod);
HeapTupleHeaderSetNatts(td, numberOfAttributes);
td->t_hoff = hoff;
/* 如果有 OID,则设置信息掩码 */
if (tupleDescriptor->tdhasoid) {
td->t_infomask = HEAP_HASOID;
}
/* 填充元组 */
heap_fill_tuple(tupleDescriptor, values, isnull, (char *)td + hoff, data_len, &td->t_infomask,
(hasnull ? td->t_bits : NULL));
return tuple; /* 返回构造的元组 */
}
??heap_form_tuple 函数的主要目的是创建一个新的堆元组(HeapTuple)。它接受一个元组描述符(TupleDesc),这个描述符定义了元组的结构(即它有多少个属性,每个属性的类型是什么等),以及两个数组:values(存储每个属性的值)和 isnull(标记对应的值是否为 NULL)。
??函数首先检查属性的数量是否超过了所允许的最大属性数量。接着,它遍历所有属性,检查是否有 NULL 值,并处理可能需要展开的压缩(toasted)属性。计算所需的总空间,并根据是否有 NULL 值或 OID 来调整空间大小。接下来,它会分配足够的内存来存放新的元组,并设置元组头部信息,包括类型、长度、属性数量等。最后,它调用 heap_fill_tuple 函数来填充元组的实际数据,并返回这个新构造的元组。
heap_fill_tuple 函数
??heap_fill_tuple 函数负责将数据从 values 和 isnull 数组中加载到元组的数据部分,并设置 null 位图(如果有的话)以及反映元组数据内容的 infomask 位。函数源码如下所示:(路径:src\gausskernel\storage\access\common\heaptuple.cpp)
/* heap_fill_tuple 函数定义 */
/* 从 values/isnull 数组加载元组的数据部分 */
/* 我们还填充 null 位图(如果有的话)并设置反映元组数据内容的 infomask 位 */
/* 注意:现在要求调用者事先将数据区域清零 */
/*
* TupleDesc tupleDesc: 描述元组结构的信息,包括属性数量和每个属性的类型。
* Datum *values: 包含每个属性的值的数组,用于填充元组。
* const bool *isnull: 指示相应 values 数组中每个值是否为 NULL 的布尔数组。
* char *data: 指向待填充元组数据部分的内存位置。
* Size data_size: 指定 data 指向的内存区域的大小,确保数据填充不越界。
* uint16 *infomask: 存储元组的附加信息和特性(如 NULL 状态、字段宽度)的位掩码。
* bits8 *bit: 用于表示元组中每个属性是否为 NULL 的位图。
*/
void heap_fill_tuple(TupleDesc tupleDesc, Datum *values, const bool *isnull, char *data, Size data_size,
uint16 *infomask, bits8 *bit) {
bits8 *bitP = NULL; /* 用于处理 null 位图的指针 */
uint32 bitmask; /* 位掩码 */
int i; /* 循环计数器 */
int numberOfAttributes = tupleDesc->natts; /* 属性数量 */
Form_pg_attribute *att = tupleDesc->attrs; /* 属性描述符数组 */
errno_t rc = EOK; /* 错误代码 */
char *begin = data; /* 数据开始的位置 */
#ifdef USE_ASSERT_CHECKING
char *start = data; /* 开始位置,用于断言检查 */
#endif
/* 初始化 null 位图处理 */
if (bit != NULL) {
bitP = &bit[-1];
bitmask = HIGHBIT;
} else {
/* 保持编译器安静 */
bitP = NULL;
bitmask = 0;
}
/* 清除 infomask 中相关的位 */
*infomask &= ~(HEAP_HASNULL | HEAP_HASVARWIDTH | HEAP_HASEXTERNAL);
/* 遍历所有属性,处理每个属性的数据 */
for (i = 0; i < numberOfAttributes; i++) {
Size data_length; /* 数据长度 */
Size remain_length = data_size - (size_t)(data - begin); /* 剩余长度 */
/* 处理 null 位图 */
if (bit != NULL) {
if (bitmask != HIGHBIT) {
bitmask <<= 1;
} else {
bitP += 1;
*bitP = 0x0;
bitmask = 1;
}
if (isnull[i]) {
*infomask |= HEAP_HASNULL;
continue;
}
*bitP |= bitmask;
}
/*
* XXX 我们直接在指针值上使用 att_align 宏,而不是在偏移量上。
* 这是一种 hack。
*/
if (att[i]->attbyval) {
/* 按值传递 */
/* 如果属性是按值传递的,即属性值直接存储在元组中,而不是通过指针引用 */
/* 使用属性的对齐规则调整 data 指针的位置 */
data = (char *)att_align_nominal(data, att[i]->attalign);
/* 将属性值按值存储在 data 指向的位置 */
store_att_byval(data, values[i], att[i]->attlen);
data_length = att[i]->attlen;
} else if (att[i]->attlen == -1) {
/* 可变长度 */
Pointer val = DatumGetPointer(values[i]);
*infomask |= HEAP_HASVARWIDTH;
if (VARATT_IS_EXTERNAL(val)) {
/* 外部存储,不需要对齐 */
*infomask |= HEAP_HASEXTERNAL;
data_length = VARSIZE_EXTERNAL(val);
rc = memcpy_s(data, remain_length, val, data_length);
securec_check(rc, "\0", "\0");
} else if (VARATT_IS_SHORT(val)) {
/* 短变长,不需要对齐 */
data_length = VARSIZE_SHORT(val);
rc = memcpy_s(data, remain_length, val, data_length);
securec_check(rc, "\0", "\0");
} else if (VARLENA_ATT_IS_PACKABLE(att[i]) && VARATT_CAN_MAKE_SHORT(val)) {
/* 转换为短变长,不需要对齐 */
data_length = VARATT_CONVERTED_SHORT_SIZE(val);
SET_VARSIZE_SHORT(data, data_length);
if (data_length > 1) {
rc = memcpy_s(data + 1, remain_length - 1, VARDATA(val), data_length - 1);
securec_check(rc, "\0", "\0");
}
} else {
/* 完整的 4 字节头部变长 */
data = (char *)att_align_nominal(data, att[i]->attalign);
data_length = VARSIZE(val);
rc = memcpy_s(data, remain_length, val, data_length);
securec_check(rc, "\0", "\0");
}
} else if (att[i]->attlen == -2) {
/* C 字符串,不需要对齐 */
*infomask |= HEAP_HASVARWIDTH;
Assert(att[i]->attalign == 'c');
data_length = strlen(DatumGetCString(values[i])) + 1;
rc = memcpy_s(data, remain_length, DatumGetPointer(values[i]), data_length);
securec_check(rc, "\0", "\0");
} else {
/* 固定长度,按引用传递 */
data = (char *)att_align_nominal(data, att[i]->attalign);
Assert(att[i]->attlen > 0);
data_length = att[i]->attlen;
rc = memcpy_s(data, remain_length, DatumGetPointer(values[i]), data_length);
securec_check(rc, "\0", "\0");
}
/* 更新数据指针 */
data += data_length;
}
/* 断言检查:确保写入的数据长度与预期一致 */
Assert((size_t)(data - start) == data_size);
}
??heap_fill_tuple 函数用于填充 HeapTuple 数据结构。这个过程包括以下几个关键步骤:
- 处理 Null 值: 函数通过一个位图(如果提供了 bit 参数)来标记哪些属性是 NULL。这是通过移动位掩码和更新位图来实现的。
- 设置 Infomask: 根据元组数据的特性(如是否有 NULL 值,是否有可变宽度属性等),设置 infomask 位。
- 数据复制: 对于每个非 NULL 属性,函数根据其类型(按值传递、可变长度、固定长度等)将数据从 values 数组复制到元组的数据区域。这涉及到适当的内存对齐和安全的内存复制。
- 长度和类型处理: 根据属性的类型(如普通数据、可变长度数据、C 字符串等),计算每个属性的数据长度,并将其复制到正确的位置。
heap_insert 函数
??当完成了元组数据在内存中的构成后,下一步就可以准备向表中插入元组了。插人元组的函数接口为 heap_insert,其流程如下图所示。
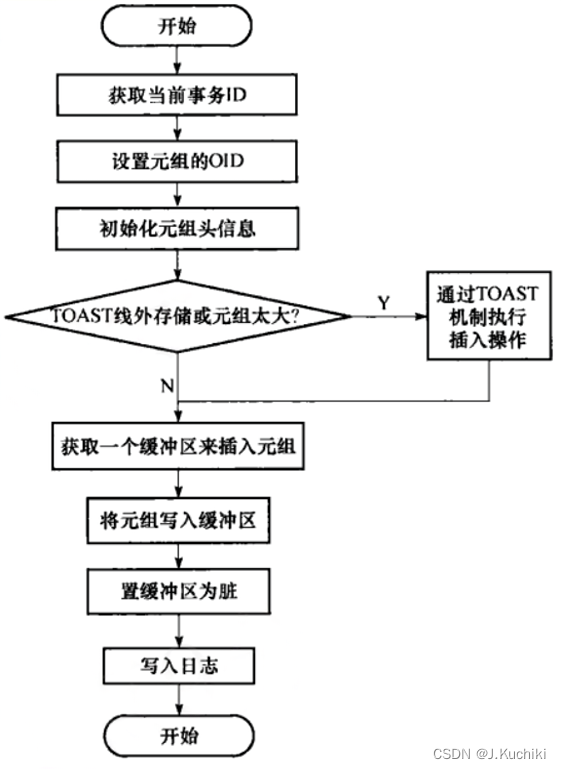
??heap_insert 函数的主要作用是将一个元组插入到数据库的一个表(即关系)中。此函数执行以下关键步骤:
- 准备要插入的元组,包括为元组分配 OID(对象标识符),必要时对元组进行压缩。
- 检查与其他事务的潜在冲突,特别是在可串行化事务中。
- 在适当的位置(即缓冲区)找到存储元组的空间。
- 在开始修改缓冲区前,进入关键操作区段,确保此过程不会因为错误而中断。
- 将元组实际插入到表中,并更新相关的可见性信息。
- 如果启用了 WAL(写前日志),则记录必要的日志信息。
- 在完成所有更改后,结束关键操作区段,释放资源。
- 更新缓存失效信息和统计数据。
- 返回新插入元组的 OID。
??heap_insert 函数源码如下所示:(路径:src\gausskernel\storage\access\heap\heapam.cpp)
/* PostgreSQL 中的 heap_insert 函数定义,用于将元组插入到堆中 */
Oid heap_insert(Relation relation, HeapTuple tup, CommandId cid, int options, BulkInsertState bistate) {
/* 获取当前事务的 ID */
TransactionId xid = GetCurrentTransactionId();
/* 准备用于后续操作的各种变量 */
HeapTuple heaptup; /* 准备插入的实际堆元组 */
Buffer buffer; /* 数据缓冲区 */
Buffer vmbuffer = InvalidBuffer; /* 可见性地图的缓冲区,初始设为无效 */
bool all_visible_cleared = false; /* 标记页面的所有可见性是否被清除 */
BlockNumber rel_end_block = InvalidBlockNumber; /* 记录关系的末尾块号 */
/* 准备元组以供插入,包括填充元组头,分配 OID,必要时对元组进行压缩(TOAST)处理 */
heaptup = heap_prepare_insert(relation, tup, cid, options);
/* 检查是否处于引导处理模式,并确认插入的元组是否符合预期 */
if (!IsBootstrapProcessingMode() && u_sess->attr.attr_common.IsInplaceUpgrade == false) {
Assert(!(IsProcRelation(relation) && IsSystemObjOid(HeapTupleGetOid(heaptup))));
}
/* 在实际插入之前,检查序列化冲突,以避免可能的回滚 */
CheckForSerializableConflictIn(relation, NULL, InvalidBuffer);
/* 在集群重组期间的特殊处理 */
if (RelationInClusterResizing(relation) && !RelationInClusterResizingReadOnly(relation)) {
options |= HEAP_INSERT_SKIP_FSM;
rel_end_block = RelationGetEndBlock(relation);
}
/* 找到用于插入这个元组的缓冲区,如果页面全部可见,还会锁定所需的可见性图页面 */
buffer = RelationGetBufferForTuple(relation, heaptup->t_len, InvalidBuffer, options, bistate, &vmbuffer, NULL, rel_end_block);
/* 为事务 ID 准备页面 */
(void)heap_page_prepare_for_xid(relation, buffer, xid, false);
HeapTupleCopyBaseFromPage(heaptup, BufferGetPage(buffer));
/* 从这里开始,直到更改被记录,不能有 ERROR 报告 */
START_CRIT_SECTION();
/* 实际将堆元组放入关系中 */
RelationPutHeapTuple(relation, buffer, heaptup, xid);
/* 检查并处理页面的全部可见性 */
if (PageIsAllVisible(BufferGetPage(buffer))) {
all_visible_cleared = true;
PageClearAllVisible(BufferGetPage(buffer));
visibilitymap_clear(relation, ItemPointerGetBlockNumber(&(heaptup->t_self)), vmbuffer);
}
/* 标记缓冲区为脏,准备写回 */
MarkBufferDirty(buffer);
/* WAL 日志相关操作 */
if (!(options & HEAP_INSERT_SKIP_WAL) && RelationNeedsWAL(relation)) {
/* 省略 WAL 日志记录细节 */
/* ... */
}
/* 结束关键操作区段 */
END_CRIT_SECTION();
/* 解锁并释放缓冲区 */
UnlockReleaseBuffer(buffer);
if (vmbuffer != InvalidBuffer) {
ReleaseBuffer(vmbuffer);
}
/* 如果元组可缓存,在事务失败时使其从缓存中失效 */
CacheInvalidateHeapTuple(relation, heaptup, NULL);
/* 更新统计信息 */
pgstat_count_heap_insert(relation, 1);
/* 如果有必要,释放临时元组副本,并更新原始元组的位置信息 */
if (heaptup != tup) {
tup->t_self = heaptup->t_self;
heap_freetuple(heaptup);
}
/* 返回元组的 OID,如果没有 OID 则返回 InvalidOid */
return HeapTupleGetOid(tup);
}
RelationPutHeapTuple 函数
??RelationPutHeapTuple 函数的主要作用是将一个堆元组放置到指定的缓冲区中的某个页面上。这个过程包括以下几个关键步骤:
- 页面获取: 首先从缓冲区中获取目标页面的头部。
- 事务 ID 设置: 为元组数据设置事务 ID。这涉及到判断页面版本,并相应地转换事务 ID。
- 元组添加: 将元组数据添加到页面中。这通过 PageAddItem 函数完成,它会返回元组在页面上的偏移量编号。如果添加失败,则触发 PANIC。
- 位置更新: 更新元组的 t_self 字段,以指向元组实际存储的位置。
- CTID 更新: 在页面上找到新元组的 ItemId 和 Item,然后更新元组头部的 t_ctid 字段,使其指向实际存储位置。
??RelationPutHeapTuple 函数源码如下所示:(路径:src\gausskernel\storage\access\heap\hio.cpp)
/* 在指定页面上放置元组的函数 */
void RelationPutHeapTuple(Relation relation, Buffer buffer, HeapTuple tuple, TransactionId xid) {
Page page_header; /* 页面头部 */
OffsetNumber offnum; /* 偏移量编号 */
ItemId item_id; /* 项目标识符 */
Item item; /* 项目 */
/* 将元组添加到页面中 */
page_header = BufferGetPage(buffer); /* 从缓冲区获取页面 */
/* 设置元组的事务 ID */
tuple->t_data->t_choice.t_heap.t_xmin = NormalTransactionIdToShort(
PageIs8BXidHeapVersion(page_header) ? ((HeapPageHeader)(page_header))->pd_xid_base : 0, xid);
/* 将元组数据添加到页面中,并获取新元组的偏移量 */
offnum = PageAddItem(page_header, (Item)tuple->t_data, tuple->t_len, InvalidOffsetNumber, false, true);
if (offnum == InvalidOffsetNumber)
ereport(PANIC, (errmsg("failed to add tuple to page"))); /* 如果添加失败,触发 PANIC */
/* 更新 tuple->t_self 为实际存储的位置 */
ItemPointerSet(&(tuple->t_self), BufferGetBlockNumber(buffer), offnum);
/* 将存储位置也更新到存储元组的 CTID 中 */
item_id = PageGetItemId(page_header, offnum);
item = PageGetItem(page_header, item_id);
((HeapTupleHeader)item)->t_ctid = tuple->t_self;
}
??在 PostgreSQL 中,实际数据被保存到段文件(堆文件)中,并且每个堆文件的大小为 segsize,其大小一般为 1GB (在编译期间可以更改)。为每个段文件设置大小是为了兼容不同平台最大文件的限制。一个段文件包含多个页面块(页面块大小为blocksize,默认为 8KB),页面块的大小不能太小,太小不能存下一个元组,太大则增加了页面读写失败的概率。这里补充一下数据库中的页面布局,如下图所示:
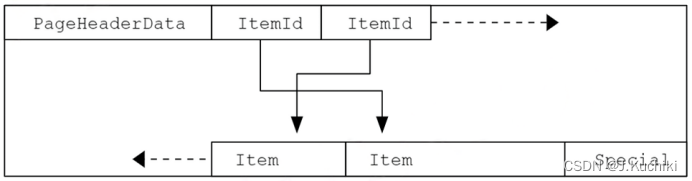
更多的详细信息可以参考 PG 官方手册。
删除元组
heap_delete
??在 PostgreSQL 中,使用标记删除的方式来删除元组,这对于多版本并发控制(Multi-version Concurrency Control,MVCC)是有好处的,其 Undo 和 Redo 速度是相当高速的,因为只需重新设置标记即可。被标记删除的磁盘空间会通过运行 VACUUM(清理数据库命令,通常每天运行一次)收回。删除元组主要调用函数 heap_delete 来实现,函数源码如下所示:(路径:src\gausskernel\storage\access\heap\heapam.cpp)
/* PostgreSQL 中删除堆中元组的函数定义 */
TM_Result heap_delete(Relation relation, ItemPointer tid, CommandId cid,
Snapshot crosscheck, bool wait, TM_FailureData *tmfd, bool allow_delete_self) {
TM_Result result; /* 删除操作的结果 */
TransactionId xid = GetCurrentTransactionId(); /* 获取当前事务 ID */
ItemId lp; /* 页面上的项目标识符 */
HeapTupleData tp; /* 堆元组数据 */
Page page; /* 页面 */
BlockNumber block; /* 块编号 */
Buffer buffer; /* 缓冲区 */
Buffer vmbuffer = InvalidBuffer; /* 可见性映射缓冲区 */
bool have_tuple_lock = false; /* 是否持有元组锁 */
bool is_combo = false; /* 是否是 combo CID */
bool all_visible_cleared = false; /* 页面所有可见性是否被清除 */
OffsetNumber maxoff; /* 页面上的最大偏移量 */
HeapTuple old_key_tuple = NULL; /* 元组的旧键,用于逻辑复制 */
bool old_key_copied = false; /* 是否已复制旧键 */
/* 检查传入的 ItemPointer 是否有效 */
Assert(ItemPointerIsValid(tid));
/* 检查当前线程是否在流模式下运行 */
Assert(!StreamThreadAmI());
/* 获取要删除的元组所在的块编号 */
block = ItemPointerGetBlockNumber(tid);
/* 读取相应的块 */
buffer = ReadBuffer(relation, block);
/* 获取页面 */
page = BufferGetPage(buffer);
/* 在锁定缓冲区之前,如果需要,锁定可见性映射页面 */
if (PageIsAllVisible(page)) {
visibilitymap_pin(relation, block, &vmbuffer);
}
/* 锁定缓冲区以进行独占访问 */
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
/* 如果页面是 4B 版本,则升级页面 */
if (PageIs4BXidVersion(page)) {
(void)heap_page_upgrade(relation, buffer);
}
/* 如果在锁定过程中页面变为全部可见,则需要重新锁定 */
if (vmbuffer == InvalidBuffer && PageIsAllVisible(page)) {
LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
visibilitymap_pin(relation, block, &vmbuffer);
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
}
/* 获取要删除的元组在页面上的位置 */
lp = PageGetItemId(page, ItemPointerGetOffsetNumber(tid));
maxoff = PageGetMaxOffsetNumber(page);
/* 检查元组位置是否有效 */
if (maxoff < ItemPointerGetOffsetNumber(tid) || !ItemIdIsNormal(lp) || !ItemPointerIsValid(tid)) {
ereport(PANIC,
(errmsg("heap_delete: invalid tid %hu, max tid %hu, rnode[%u,%u,%u], block %u", tid->ip_posid, maxoff,
relation->rd_node.spcNode, relation->rd_node.dbNode, relation->rd_node.relNode, block)));
}
/* 设置元组数据 */
tp.t_tableOid = RelationGetRelid(relation);
tp.t_bucketId = RelationGetBktid(relation);
tp.t_data = (HeapTupleHeader)PageGetItem(page, lp);
tp.t_len = ItemIdGetLength(lp);
tp.t_self = *tid;
HeapTupleCopyBaseFromPage(&tp, page);
tmfd->xmin = HeapTupleHeaderGetXmin(page, tp.t_data);
/* 标签 l1 用于在等待并发事务完成后重试 */
l1:
/* 检查元组是否可以更新 */
result = HeapTupleSatisfiesUpdate(&tp, cid, buffer, allow_delete_self);
/* 根据检查结果进行相应处理 */
/* ...(省略了详细的条件处理代码)... */
/* 如果结果是 TM_Ok,则继续执行删除操作 */
if (result != TM_Ok) {
/* 如果删除不成功,处理失败数据并返回 */
/* ...(省略了详细的错误处理代码)... */
return result;
}
/* 在实际删除之前,检查序列化冲突 */
CheckForSerializableConflictIn(relation, &tp, buffer);
/* 如果需要,将命令 ID 替换为组合 CID */
HeapTupleHeaderAdjustCmax(tp.t_data, &cid, &is_combo, buffer);
/* 为页面准备事务 ID */
(void)heap_page_prepare_for_xid(relation, buffer, xid, false);
/* 从页面复制元组的基本信息 */
HeapTupleCopyBaseFromPage(&tp, page);
/* 在进入关键操作区之前计算副本身份元组 */
/* ...(省略了逻辑复制相关的代码)... */
/* 进入关键操作区 */
START_CRIT_SECTION();
/* 设置页面可修剪标志 */
PageSetPrunable(page, xid);
/* 清除页面的全部可见性标志,并更新可见性映射 */
/* ...(省略了页面可见性处理的代码)... */
/* 更新元组的事务信息 */
/* ...(省略了事务信息更新的代码)... */
/* 结束关键操作区 */
END_CRIT_SECTION();
/* 解锁缓冲区 */
LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
/* 如果元组有外部属性,则删除外部项 */
/* ...(省略了处理 TOAST 数据的代码)... */
/* 使元组在系统缓存中失效 */
CacheInvalidateHeapTuple(relation, &tp, NULL);
/* 释放缓冲区 */
ReleaseBuffer(buffer);
/* 如果持有元组锁,则释放 */
if (have_tuple_lock) {
UnlockTuple(relation, &(tp.t_self), ExclusiveLock);
}
/* 更新统计信息 */
pgstat_count_heap_delete(relation);
/* 如果有旧键副本,则释放 */
if (old_key_tuple != NULL && old_key_copied) {
heap_freetuple(old_key_tuple);
}
/* 返回操作结果 */
return TM_Ok;
}
??heap_delete 函数用于从 PostgreSQL 中的表(即关系)删除一个指定的元组。这个过程包括以下几个关键步骤:
- 读取和锁定页面: 首先读取包含目标元组的页面,并对其进行锁定以进行独占访问。
- 检查元组状态: 检查目标元组的当前状态,确定它是否可以被当前事务删除。
- 处理并发事务: 如果元组被其他事务锁定,可能需要等待并再次检查元组的状态。
- 执行删除操作: 一旦确认可以删除元组,将其在页面上的信息进行更新,标记为删除。
- 写入 WAL 日志: 如果启用了 WAL(写前日志),记录删除操作。
- 处理 TOAST 数据: 如果元组有外部存储(TOAST)数据,也需要相应地处理这些数据。
- 缓存失效和统计信息更新: 更新系统缓存和统计信息以反映删除操作。
- 释放资源: 释放所有占用的资源,包括缓冲区和锁。
更新元组
heap_update
??元组的更新操作实际上是删除和插入操作的结合,即先标记删除旧元组,再插入新元组。元组的更新由函数 heap_update 实现。heap_update 函数源码如下所示:(路径:src\gausskernel\storage\access\heap\heapam.cpp)
/* PostgreSQL 中更新堆中元组的函数定义 */
TM_Result heap_update(Relation relation, Relation parentRelation, ItemPointer otid, HeapTuple newtup,
CommandId cid, Snapshot crosscheck, bool wait, TM_FailureData *tmfd, bool allow_update_self) {
TM_Result result; /* 更新操作的结果 */
TransactionId xid = GetCurrentTransactionId(); /* 获取当前事务 ID */
Bitmapset *hot_attrs = NULL; /* HOT更新的属性 */
Bitmapset *id_attrs = NULL; /* 身份属性 */
ItemId lp; /* 页面上的项目标识符 */
HeapTupleData oldtup; /* 旧的堆元组数据 */
HeapTuple heaptup; /* 新的堆元组 */
HeapTuple old_key_tuple = NULL; /* 旧键元组,用于逻辑复制 */
bool old_key_copied = false; /* 是否已复制旧键 */
Page page, newpage; /* 页面 */
BlockNumber block; /* 块编号 */
Buffer buffer = InvalidBuffer; /* 缓冲区 */
Buffer newbuf = InvalidBuffer; /* 新缓冲区 */
Buffer vmbuffer = InvalidBuffer; /* 可见性映射缓冲区 */
Buffer vmbuffer_new = InvalidBuffer; /* 新的可见性映射缓冲区 */
bool need_toast = false; /* 是否需要 TOAST 操作 */
bool already_marked = false; /* 是否已标记 */
Size new_tup_size, pagefree; /* 新元组大小和页面可用空间 */
bool have_tuple_lock = false; /* 是否持有元组锁 */
bool is_combo = false; /* 是否是 combo CID */
bool satisfies_hot = false; /* 是否满足 HOT 更新条件 */
bool satisfies_id = false; /* 是否满足身份条件 */
bool use_hot_update = false; /* 是否使用 HOT 更新 */
bool all_visible_cleared = false; /* 页面所有可见性是否被清除 */
bool all_visible_cleared_new = false; /* 新页面所有可见性是否被清除 */
int options = 0; /* 选项 */
bool rel_in_redis = RelationInClusterResizing(relation); /* 关系是否在集群重组中 */
OffsetNumber maxoff; /* 页面上的最大偏移量 */
BlockNumber rel_end_block = InvalidBlockNumber; /* 关系的末端块号 */
Assert(ItemPointerIsValid(otid)); /* 断言检查传入的 otid 是否有效 */
/* 检查当前线程是否在流模式下运行 */
Assert(!StreamThreadAmI());
/* 获取要更新的元组所在的块编号 */
block = ItemPointerGetBlockNumber(otid);
/* 读取相应的块 */
buffer = ReadBuffer(relation, block);
/* 获取页面 */
page = BufferGetPage(buffer);
/* 在锁定缓冲区之前,如果需要,锁定可见性映射页面 */
if (PageIsAllVisible(page)) {
visibilitymap_pin(relation, block, &vmbuffer);
}
/* 锁定缓冲区以进行独占访问 */
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
/* 如果页面是 4B 版本,则升级页面 */
if (PageIs4BXidVersion(page)) {
(void)heap_page_upgrade(relation, buffer);
}
/* 获取要更新的元组在页面上的位置 */
lp = PageGetItemId(page, ItemPointerGetOffsetNumber(otid));
maxoff = PageGetMaxOffsetNumber(page);
/* 检查 otid */
if (maxoff < ItemPointerGetOffsetNumber(otid) || !ItemIdIsNormal(lp) || !ItemPointerIsValid(otid)) {
ereport(PANIC,
(errmsg("heap_update: invalid tid %hu, max tid %hu, rnode[%u,%u,%u], block %u", otid->ip_posid, maxoff,
relation->rd_node.spcNode, relation->rd_node.dbNode, relation->rd_node.relNode, block)));
}
/* 设置旧元组数据 */
oldtup.t_data = (HeapTupleHeader)PageGetItem(page, lp);
oldtup.t_len = ItemIdGetLength(lp);
oldtup.t_self = *otid;
oldtup.t_tableOid = RelationGetRelid(relation);
oldtup.t_bucketId = RelationGetBktid(relation);
HeapSatisfiesHOTUpdate(relation, hot_attrs, id_attrs, &satisfies_hot, &satisfies_id, &oldtup, newtup, page);
tmfd->xmin = HeapTupleHeaderGetXmin(page, oldtup.t_data);
/* 标签 l2 用于在等待并发事务完成后重试 */
l2:
/* ...(剩余部分的详细注释省略)... */
}
??heap_update 函数用于更新表的一个指定元组。这个过程包括以下几个关键步骤:
- 读取和锁定页面: 首先读取包含目标元组的页面,并对其进行锁定以进行独占访问。
- 检查元组状态: 检查目标元组的当前状态,确定它是否可以被当前事务更新。
- 处理并发事务: 如果元组被其他事务锁定,可能需要等待并再次检查元组的状态。
- 执行更新操作: 一旦确认可以更新元组,将其在页面上的信息进行更新,标记为更新。
- 写入 WAL 日志: 如果启用了 WAL(写前日志),记录更新操作。
- 处理 TOAST 数据: 如果元组有外部存储(TOAST)数据,也需要相应地处理这些数据。
- 缓存失效和统计信息更新: 更新系统缓存和统计信息以反映更新操作。
- 释放资源: 释放所有占用的资源,包括缓冲区和锁。
??值得注意的是,PostgreSQL 中进行删除和更新操作时,被删除或修改的元组并不会从物理文件中删除,而是在事务标记中被标记为无效。因此,当进行过大量的删除和更新操作之后,数据库数据文件中由于有大量的无效元组,其尺寸会变得异常庞大,此时需要对数据库进行一定的清理操作,这就需要用到 VACUUM 机制。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!