Spark---RDD(Key-Value类型转换算子)
文章目录
1.RDD Key-Value类型
Key-Value类型的算子即对键值对进行操作。
1.1 partitionBy
将数据按照指定的 Partitioner(分区器) 重新进行分区。Spark 默认的分区器为HashPartitioner,Spark除了默认的分区器外,常见的分区器还有:RangePartitioner、Custom Partitioner、SinglePartitioner等。
函数定义:
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
//使用HashPartitioner分区器并设置分区个数为2
val data1: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
data1.partitionBy(new HashPartitioner(2));
data1.collect().foreach(println)

1.2 reduceByKey
可以将数据按照相同的 Key 对 Value 进行聚合
函数定义:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
//将数据按照相同的key对value进行聚合
val data1: RDD[(String, Int)] = sparkRdd.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("a",4),("b",5)))
val data2: RDD[(String, Int)] = data1.reduceByKey((x: Int, y: Int) => {
x + y
})
data2.collect().foreach(println)

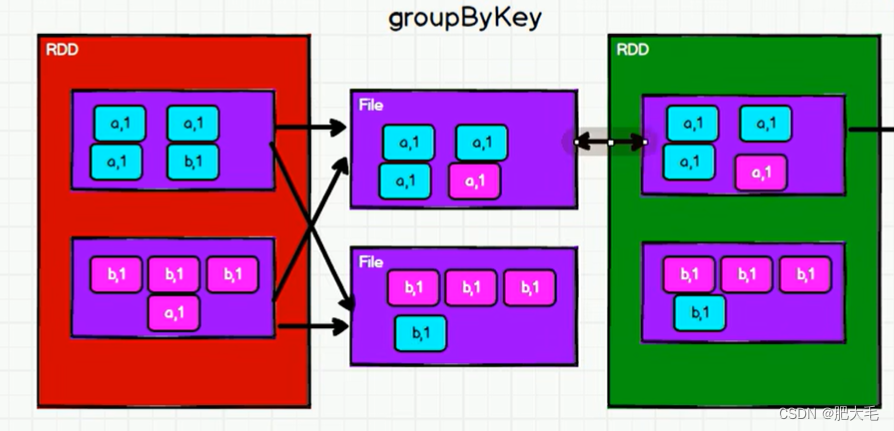
1.3 groupByKey
将数据源的数据根据 key 对 value 进行分组
函数定义:
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
val dataRDD1 = sparkRdd.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("a",4),("b",5)))
val data1 = dataRDD1.groupByKey()
//指定分区个数为2
val data2 = dataRDD1.groupByKey(2)
//指定分区器和分区个数
val data3 = dataRDD1.groupByKey(new HashPartitioner(2))
data1.collect().foreach(println)
println("-------------------->")
data2.collect().foreach(println)
println("-------------------->")
data3.collect().foreach(println)

reduceByKey和groupByKey的区别
从功能的角度来看:reduceByKey包含了分组和聚合功能,而groupByKey只包含了分组功能。
从shuffle的角度来看:为了避免占用过多的内存空间,reduceByKey和groupByKey在执行的过程中,都会执行shuffle操作,将数据打散写入到磁盘的临时文件中,而reduceByKey在进行shuffle前会对数据进行预聚合的操作,致使shuffle的效率得到的提升,因为减少了落盘的数据量。但是groupByKey在shuffle前不会进行预聚合操作。所以,reduceByKey在进行分组的时候,效率相对groupByKey来说较高。
reduceByKey:
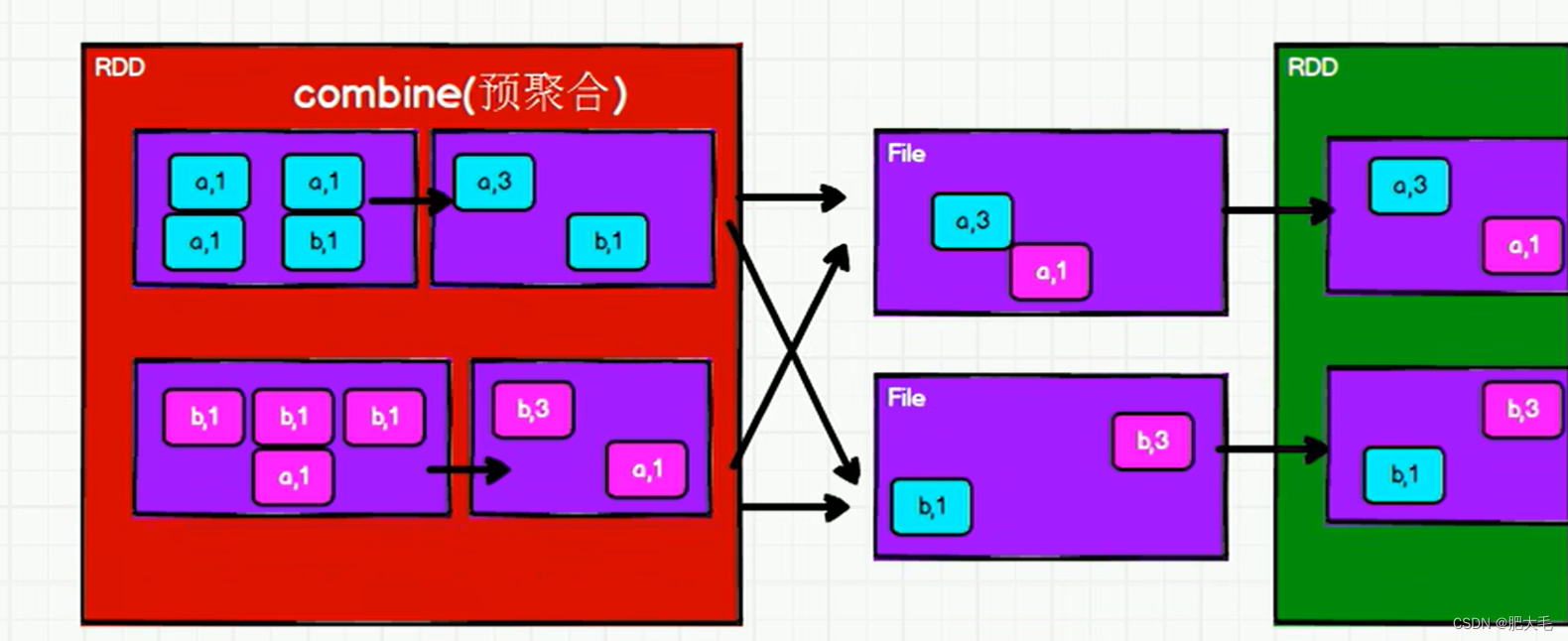
groupByKey:
分区间和分区内
分区间: 顾名思义,分区间就是指的多个分区之间的操作。如reduceByKey在shuffle操作后将不同分区的数据传输在同一个分区中进行聚合。
分区内: 分区内字面意思指的是单个分区内之间的操作。如reduceByKey的预聚合功能就是在分区内完成
1.4 aggregateByKey
将数据根据不同的规则进行分区内计算和分区间计算,如reduceByKey中分区间和分区内都是聚合操作,而使用aggregateByKey可以设置分区间和分区内执行不同的操作。
函数定义:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
//取出每个分区内相同 key 的最大值然后分区间相加
// aggregateByKey 算子是函数柯里化,存在两个参数列表
// 1. 第一个参数列表中的参数表示初始值
// 2. 第二个参数列表中含有两个参数
// 2.1 第一个参数表示分区内的计算规则
// 2.2 第二个参数表示分区间的计算规则
val data1 = sparkRdd.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)),2)
val data2 = data1.aggregateByKey(0)(
(x,y)=>{Math.max(x,y)},
(x,y)=>{x+y}
)
data2.collect().foreach(println)**

注意:最终的结果会受到设置的初始值的影响,返回结果的值的类型和初始值保持一致。
获取相同key的value的平均值
val data1:RDD[(String,Int)] = sparkRdd.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4),("b",5),("a",6)),2)
//设置初始值,初始值为一个元组,元组第一个元素表示value,第二个表示出现次数,初始默认都为0
val data2:RDD[(String,(Int,Int))] = data1.aggregateByKey((0,0))(
(t, v)=> {
(t._1 + v, t._2 + 1)
} ,//分区内计算
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}//分区间计算
)
//和除以次数求出平均值
val data3 = data2.mapValues({
case (sum, count) => sum / count
})
data3.collect().foreach(println)

1.5 foldByKey
当分区内和分区间的计算规则相同的时候,aggregateByKey 就可以简化为 foldByKey
函数定义:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
val dataRDD1 = sparkRdd.makeRDD(List(("a",1),("b",2),("a",3)))
val dataRDD2 = dataRDD1.foldByKey(0)(_+_)
dataRDD2.collect().foreach(println)

1.6 combineByKey
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
函数定义:
def combineByKey[C](
createCombiner: V => C,//对数据进行转换
mergeValue: (C, V) => C, //分区内合并
mergeCombiners: (C, C) => C): RDD[(K, C)] //分区间合并
//将数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))求每个 key 的平均值
val rddSource: RDD[(String, Int)] = sparkRdd.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),2)
val combinRdd: RDD[(String, (Int, Int))] = rddSource.combineByKey(
((x:Int)=>{
(x,1)
}),//对每个value进行转换,转换后为(value,1),第一个元素为值,第二个元素为出现的次数
((t1:(Int,Int),v)=>{
(t1._1+v,t1._2+1)
}),//分区内合并
((t1,t2)=>{
(t1._1+t2._1,t1._2+t2._2)
})//分区间合并
)
//mapValues算子是在key保持不变的时候对value进行操作
val mapRdd: RDD[(String, Int)] = combinRdd.mapValues({
case ((sum: Int, count: Int)) => sum / count
})
mapRdd.collect().foreach(println)

由此看出,combineByKey和aggreateByKey的不同之处在于,combineByKey可以不设置初始值,只需要对第一个元素进行转换,转换到合适的计算格式即可。
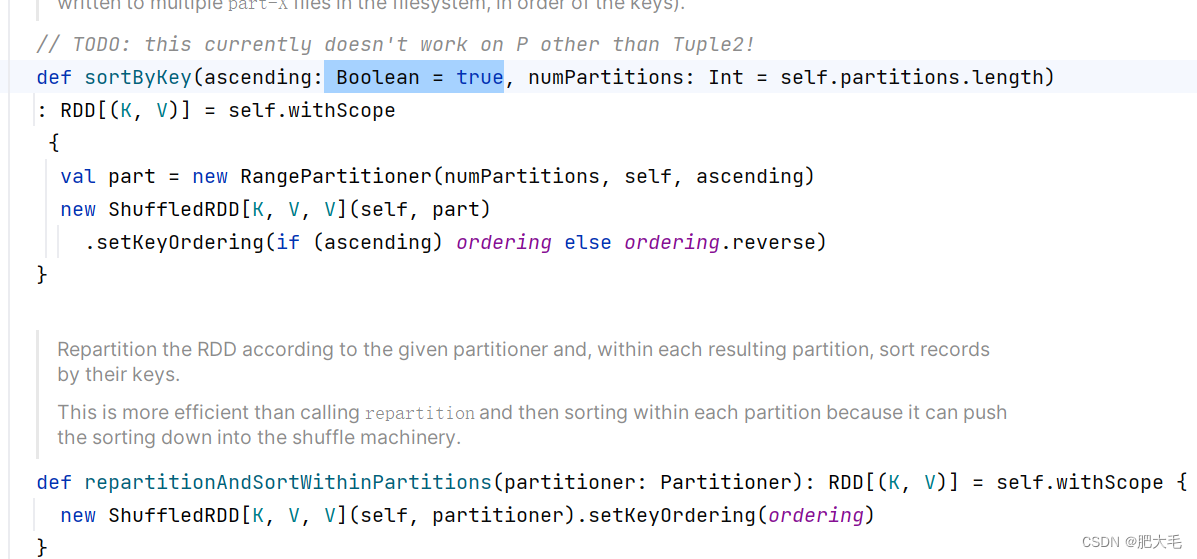
1.7 sortByKey
在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序的
函数定义:
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
//升序排序
val dataRDD1 = sparkRdd.makeRDD(List(("a",1),("b",2),("c",3)))
val sortRdd: RDD[(String, Int)] = dataRDD1.sortByKey()
sortRdd.collect().foreach(print)

sortByKey默认为升序排序,如果想要降序排序,只需要将sortByKey第一个参数修改为false即可。
1.8 join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD
函数定义:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
//join操作相当于数据库中的内连接,在连接的时候自动去除两边的悬浮元组
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(Array((1, 4), (2, 5), (3, 6)))
rdd0.join(rdd1).collect().foreach(print)
//修改rdd1,使其少了key=3的这个元素
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(Array((1, 4), (2, 5)))
rdd0.join(rdd1).collect().foreach(print)
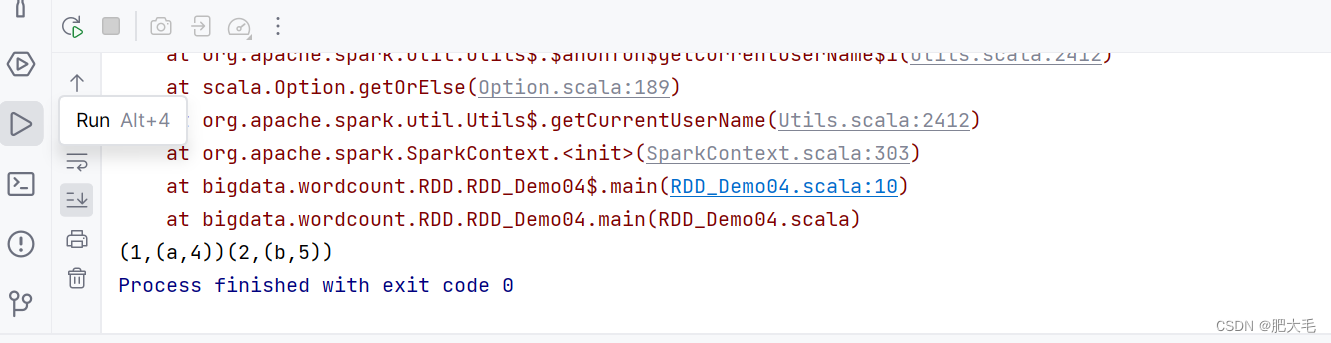
1.9 leftOuterJoin
类似于 SQL 语句的左外连接
函数定义:
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(List((1, "a"), (2, "b")))
val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(List((1, 4), (2, 5),(3, 6)))
val rddRes = rdd0.leftOuterJoin(rdd1)
rddRes.collect().foreach(print)
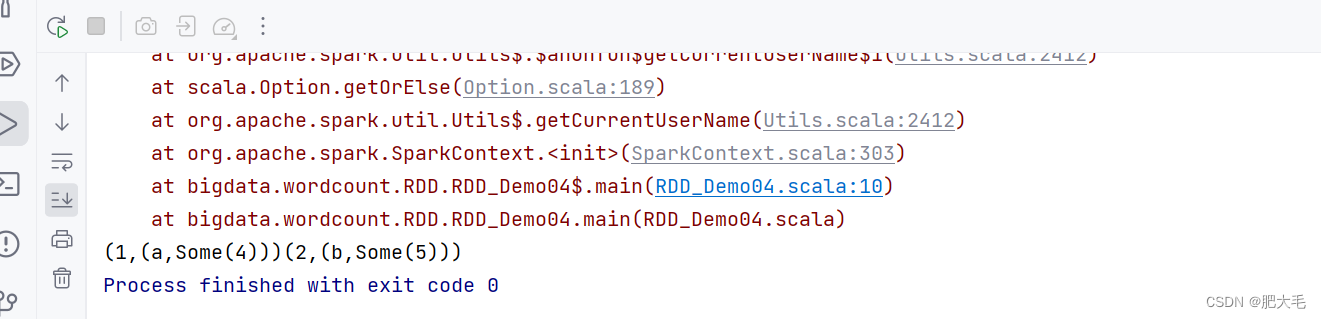
1.10 cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD,即先对
函数定义:
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(List((1, "a"), (2, "b"),(3,"c")))
val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(List((1, 4), (2, 5)))
val rddRes = rdd0.cogroup(rdd1)
rddRes.collect().foreach(print)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!