爬虫解析——Xpath的安装及使用(五)
目录
Xpath可以解析两种文件
- etree.parse() 解析本地文件:html_tree = etree.parse( 'xx.html')
- etree.HTML()服务器响应文件:html_tree = etree.HTML(response.read( ).decode( utf-8")
Xpath基本语法
html_tree.xpath(xpath路经)
1.路径查询
????????//: 查找所有子孙节点,不考虑层级关系(子和孙所有节点)
????????/: 找直接子节点
2.谓词查询
????????//div[@id]
????????//div[@id="maincontent"]
3.属性查询
????????//div/@class
4.模湖查询
????????//div[contains(@id,"he")]
????????//div[starts-with(@id,"he")]
5.内容查询
????????//div/h1/text()
6.逻辑运算
????????//div[@id="head” and @class="s_down"]
????????//title | //price
一、Xpath插件的安装
进入chrome应用商店

搜索 Xpath helpler?
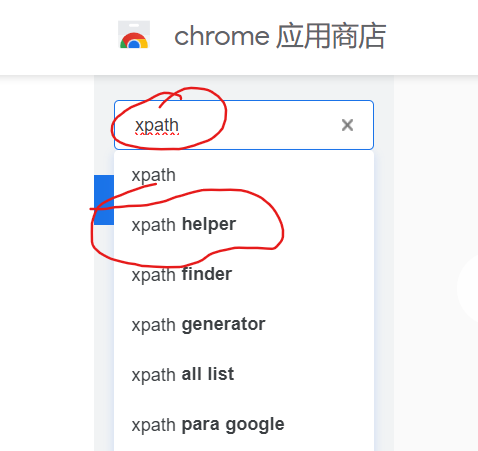
选择这个安装?
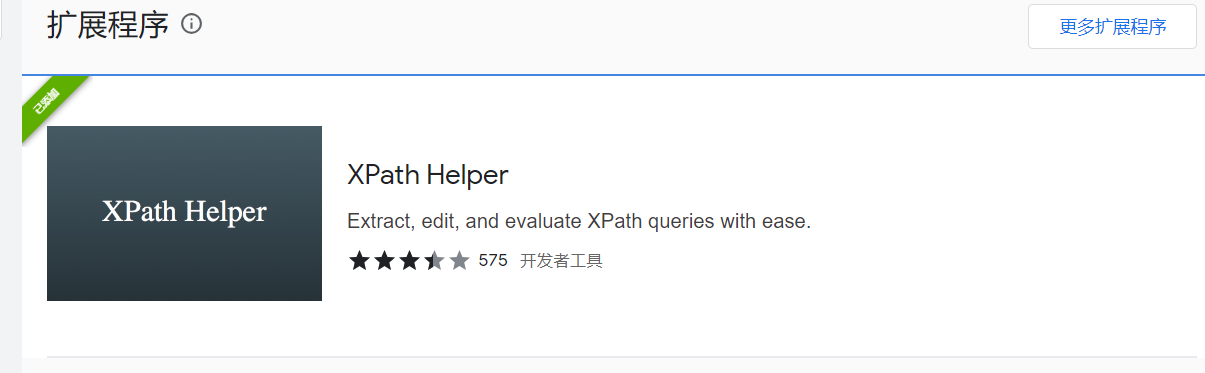
怎么看扩展是否安装成功呢?
随便打开一个页面,然后 按快捷键 Ctrl+Shift+X
出现这个黑色的框框就算安装成功了
二、安装 lxml
在环境中
pip install lxml
三、Xpath解析文件
1.解析本地文件
(1)导入本地文件
from lxml import etree
# Xpath解析有两种解析文件
# 1.本地文件 etree.parse( 'xx.html')
# 2.服务器相应数据 response.read().decode('utf-8') 【主要用这个】 etree.HTML(response.read( ).decode("utf-8")
tree = etree.parse('_070.html')
print(tree)报错:

?需要将本地文件中的meta加一个结束标签
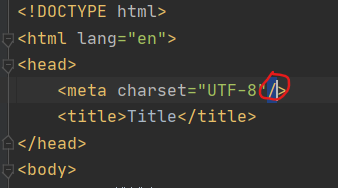
然后重新运行就可以了

(2)解析本地文件
本地的 HTML 文件?
内容查询
# text() 获取标签中的内容
# 路径查询
# 查找 ul 下面的 li
# li_list = tree.xpath('//body/ul/li')
li_list = tree.xpath('//body/ul/li/text()')
print(li_list)?不用内容查询
使用内容查询
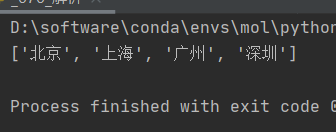
路径查询
# text() 获取标签中的内容
# 路径查询
# 查找 ul 下面的 li
li_list = tree.xpath('//body/ul/li/text()')
print(li_list)
谓词查询
# 谓词查询
# 查找所有有id属性的 <li> 标签
li_list = tree.xpath('//ul/li[@id]/text()')
print(li_list)
![]()
# 谓词查询
# 查找id为 ‘l1’ 的 <li> 标签
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)![]()
属性查询
# 属性查询
# 查询<li>标签的class属性的属性值
li_list = tree.xpath('//ul/li/@class')
print(li_list)![]()
# 查询id 为 ‘l1’ 的<li>标签的class属性的属性值
li_list = tree.xpath('//ul/li[@id="l1"]/@class')
print(li_list)![]()
模糊查询
# 模糊查询
# 查找 <li> 标签的id中包含 ‘l’ 的标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)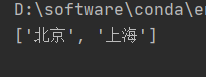
# 查找 <li> 标签的id中以‘s’开头的标签
li_list = tree.xpath('//ul/li[starts-with(@id,"s")]/text()')
print(li_list)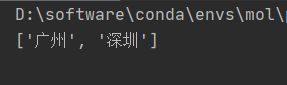
逻辑查询
# 逻辑运算
# 查询<li>标签中id为‘l1’且class的属性值为‘c1’的标签
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
print(li_list)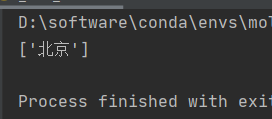
# 查询<li>标签中id为‘s1’或者class为‘c1’的标签
li_list = tree.xpath('//ul/li[@id="s1"]/text() | //ul/li[@class="c1"]/text()')
print(li_list)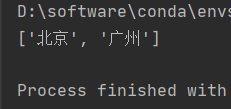
2.服务器文件解析
(1)获取网页源码
# 1.获取网页的源码
url = 'https://www.baidu.com/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟客户端向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
print(content)(2)解析服务器响应文件
# 解析服务器响应的文件
tree = etree.HTML(content)我们应该如何获取Xpath呢?
之前安装的Xpath扩展就起作用了
我们 Ctrl + Shift + X打开扩展
右键页面打开检查,定位到“百度一下” 【我们要想要获取“百度一下”这个字段】
然后我们就可以根据检查中html标签的描述,在黑色框的左侧写 查询代码,右侧则显示查询结果,查询正确时,右侧框中则会出现你想要的东西,我们复制这个Xpath路径。
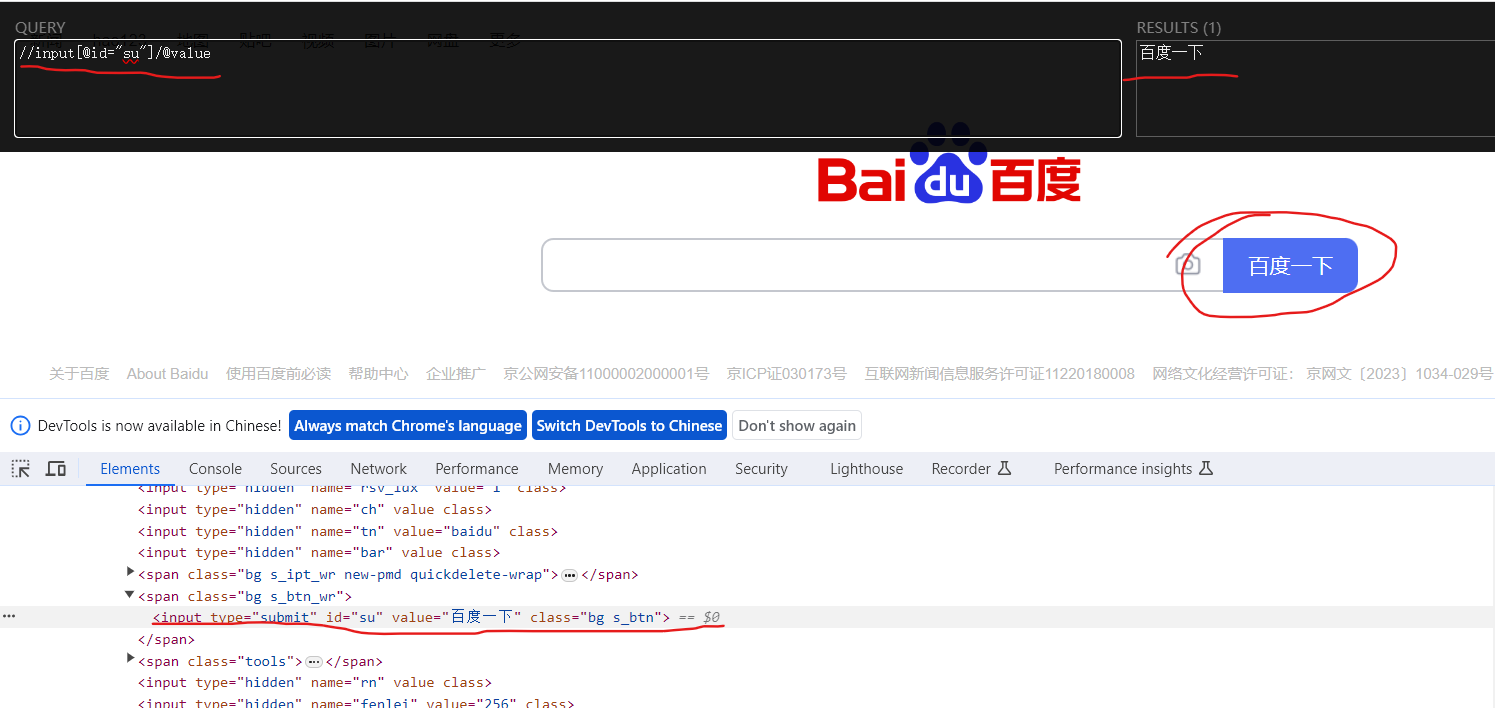
将复制的Xpath路径填入代码,运行就可以看到,我们已经成功获取了“百度一下这个字段”
# 打印
result= tree.xpath('//input[@id="su"]/@value')
print(result)

还有一种获取Xpath的方法
右键网页,点击检查,点击箭头,然后选中页面中“百度一下”这个框,检查中就会点位到这个框的位置,然后右键这个位置,选择copy,选择copy Xpath,就会得到一个定位到百度一下这个框的代码? //*[@id="su"]
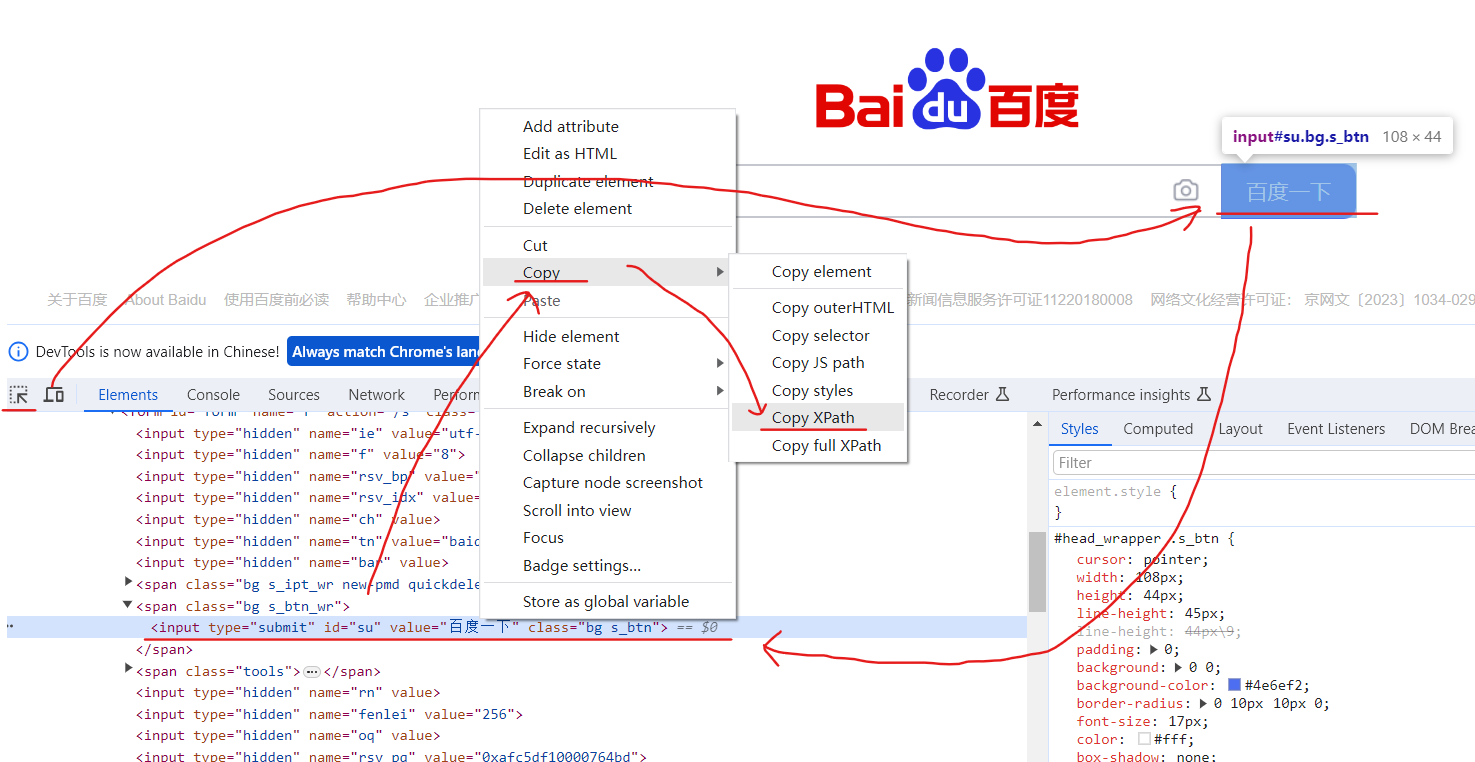
然后补充自己想要获取的值(@value)就可以
result = tree.xpath('//*[@id="su"]/@value')
print(result)本地文件解析完整代码:
from lxml import etree
# Xpath解析有两种解析文件
# 1.本地文件 etree.parse( 'xx.html')
# 2.服务器相应数据 response.read().decode('utf-8') 【主要用这个】 etree.HTML(response.read( ).decode("utf-8")
##############################
######## 本地文件解析 ########
#############################
# 导入 本地html文件
tree = etree.parse('_070.html')
# text() 获取标签中的内容
# 路径查询
# 查找 ul 下面的 li
# li_list = tree.xpath('//body/ul/li/text()')
# 谓词查询
# 查找所有有id属性的 <li> 标签
# li_list = tree.xpath('//ul/li[@id]/text()')
# 查找id为 ‘l1’ 的 <li> 标签
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 属性查询
# 查询<li>标签的class属性的属性值
# li_list = tree.xpath('//ul/li/@class')
# 查询id 为 ‘l1’ 的<li>标签的class属性的属性值
# li_list = tree.xpath('//ul/li[@id="l1"]/@class')
# 模糊查询
# 查找 <li> 标签的id中包含 ‘l’ 的标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查找 <li> 标签的id中以‘s’开头的标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"s")]/text()')
# 逻辑运算
# 查询<li>标签中id为‘l1’且class的属性值为‘c1’的标签
# li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
# 查询<li>标签中id为‘s1’或者class为‘c1’的标签
li_list = tree.xpath('//ul/li[@id="s1"]/text() | //ul/li[@class="c1"]/text()')
print(li_list)服务器文件解析完整代码:
from lxml import etree
import urllib.request
###############################
####### 解析服务器文件 ##########
###############################
# 1.获取网页的源码
url = 'https://www.baidu.com/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟客户端向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 2.解析服务器响应文件
# 解析服务器响应的文件
tree = etree.HTML(content)
# 打印 Xpath 的返回值是一个列表类型的数据
# result= tree.xpath('//input[@id="su"]/@value')
result = tree.xpath('//*[@id="su"]/@value')
print(result)
四、Xpath-抓取图片
抓取站长素材网站的图片
1.设置url
查找每一页 url 的规律
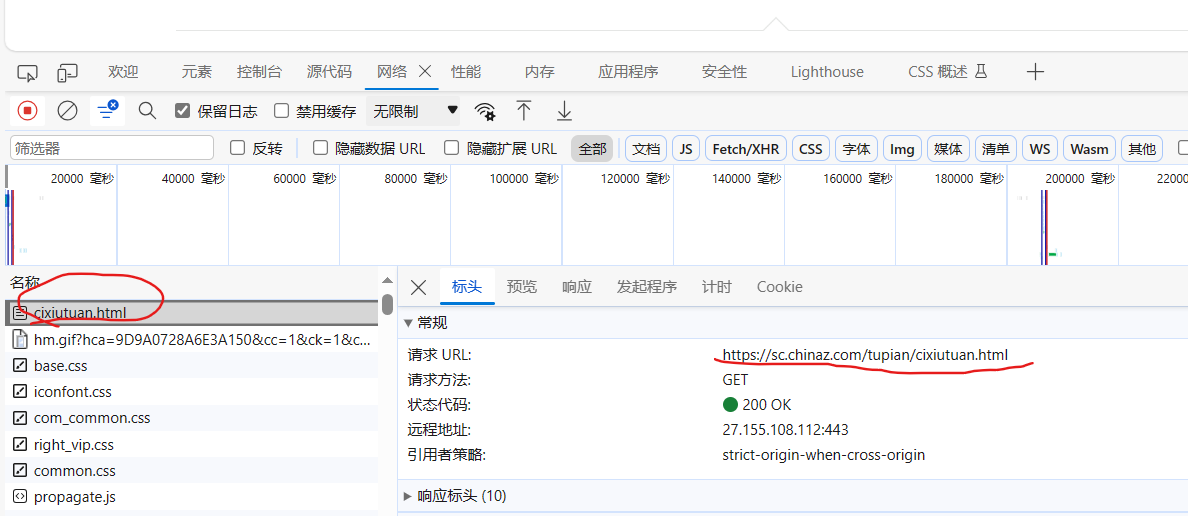
# 找 url 的规律
# url : https://sc.chinaz.com/tupian/cixiutuan.html page = 1
# url : https://sc.chinaz.com/tupian/cixiutuan_2.html page = 2
# url : https://sc.chinaz.com/tupian/cixiutuan_3.html page = 32.请求对象定制
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/cixiutuan.html'
else:
url = 'https://sc.chinaz.com/tupian/cixiutuan_'+str(page)+'.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
request = urllib.request.Request(url, headers=headers)
return request3.获取网页源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content?4.下载图片
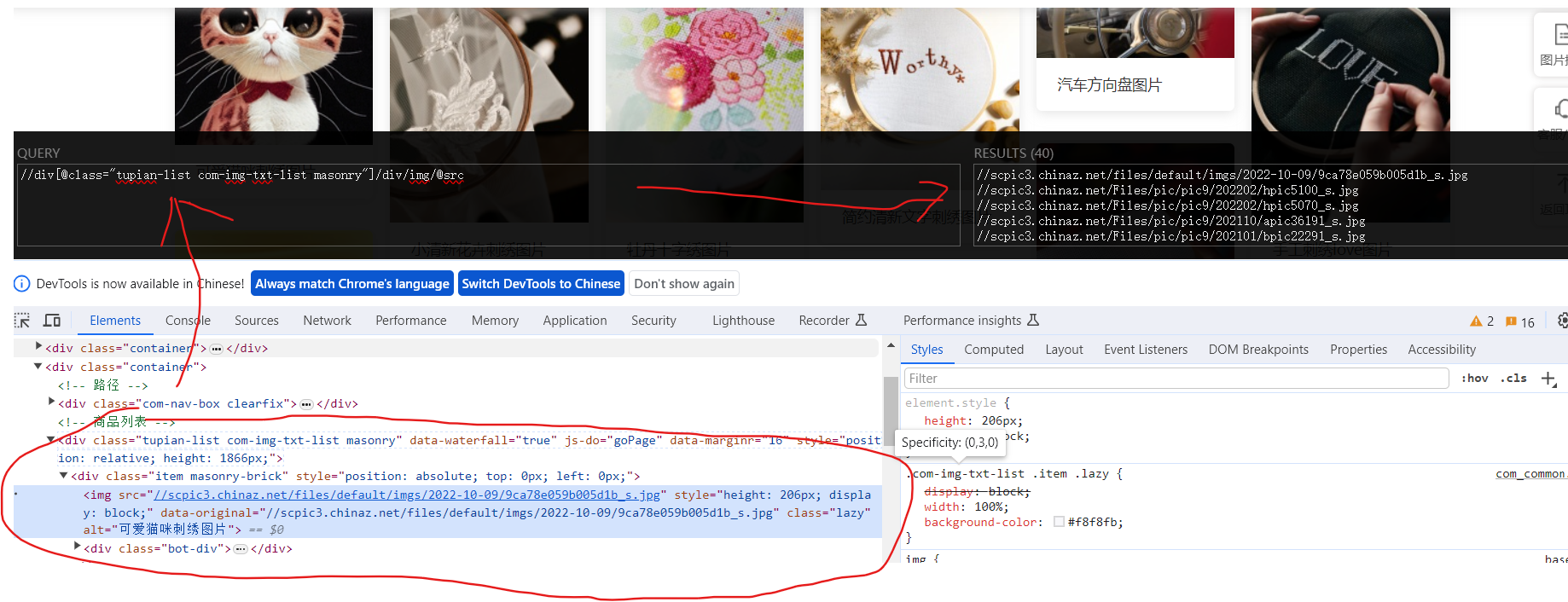
通过Xpath获取图片的链接和图片名称
右键检查 --> 定位到图片的标签行 -->?在Xpath扩展的左侧框中写入Xpath?--> 右侧与想要的数据吻合?--> 复制这个Xpath
但是!!!有时候在网页上获取的Xpath和通过response获取Xpath是不一样的,如果没有返回内容,就把网页下载下来看一下Xpath。
有时候src并不是真实的路径,可能会在‘data-original’中,重点是要检查content中的内容。
有的网站也会存在懒加载,src的属性就会变成src2,这个问题就需要根据从content和页面多加辨别。
def download(content):
# 下载图片
# urllib.request.urlretrieve('图片地址', '图片名称') # 这两项我们都没有,那我们就要先获取
tree = etree.HTML(content)
src_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]/div/img/@data-original')
name_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]/div/img/@alt')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='_072_download_img/'+name+'.png')5.调用
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):
# 请求对象定制
response = create_request(page)
# 获取网页源码
content = get_content(response)
# 下载
download(content)
完整代码:
# 站长素材 https://sc.chinaz.com/
# 站长素材 --> 高清图片 --> 选择一个 --> 下载前十页
import urllib.request
from lxml import etree
# 找 url 的规律
# url : https://sc.chinaz.com/tupian/cixiutuan.html page = 1
# url : https://sc.chinaz.com/tupian/cixiutuan_2.html page = 2
# url : https://sc.chinaz.com/tupian/cixiutuan_3.html page = 3
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/cixiutuan.html'
else:
url = 'https://sc.chinaz.com/tupian/cixiutuan_'+str(page)+'.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
request = urllib.request.Request(url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(content):
# 下载图片
# urllib.request.urlretrieve('图片地址', '图片名称') # 这两项我们都没有,那我们就要先获取
tree = etree.HTML(content)
src_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]/div/img/@data-original')
name_list = tree.xpath('//div[@class="tupian-list com-img-txt-list"]/div/img/@alt')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='_072_download_img/'+name+'.png')
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):
# 请求对象定制
response = create_request(page)
# 获取网页源码
content = get_content(response)
# 下载
download(content)
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!