李宏毅gpt个人记录
2023-12-13 03:56:04
参考&转载:
李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder-CSDN博客
目录
| 模型 | 参数量 |
| ELMO | 94M |
| BERT | 340M |
| GPT-2 | 1542M |
????????用无标注资料的任务训练完模型以后,它本身没有什么用,GPT 1只能够把一句话补完,可以把 Self-Supervised Learning 的 Model做微微的调整,把它用在其他下游的任务裡面,对于下游任务的训练,仍然需要少量的标记数据。
GPT1基本实现
????????例如有条训练语句是“台湾大学”,那么输入BOS后训练输出是台,再将BOS和"台"作为输入训练输出是湾,给它BOS "台"和"湾",然后它应该要预测"大",以此类推。模型输出embedding h,h再经过linear classification和softmax后,计算输出分布与正确答案之间的损失cross entropy,希望它越小越好。
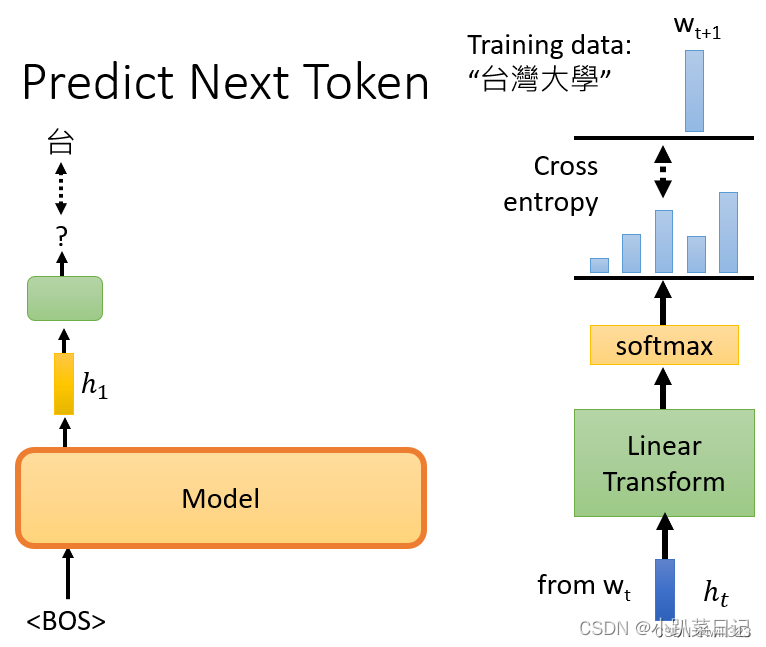
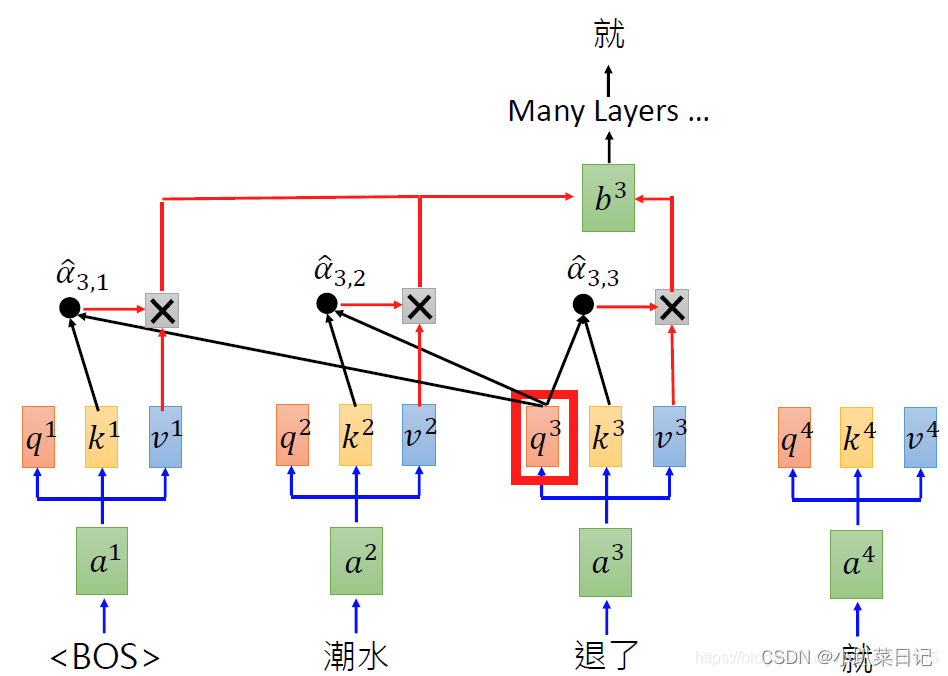
详细计算过程:?

文章来源:https://blog.csdn.net/qq_55736201/article/details/134831378
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!