OpenAI Q* (Q Star)简单介绍

一、Q Star 名称由来
Q* 的两个可能来源如下:
1)Q 可能是指 "Q-learning",这是一种用于强化学习的机器学习算法。
-
Q 名称的由来*:把 "Q*"想象成超级智能机器人的昵称。
-
Q 的意思是这个机器人非常善于做决定。
-
它从经验中学习,就像你从玩电子游戏中学习一样。
-
玩得越多,就越能找出获胜的方法。
2) 来自 A* 搜索
A* 搜索算法是一种寻路和图遍历算法,在计算机科学中被广泛用于解决各种问题,尤其是在游戏和人工智能中用于寻找两点之间的最短路径。
-
想象一下,你身处迷宫之中,需要找到最快的出路。
-
计算机科学中有一种经典方法,有点像一组指令,可以帮助找到迷宫中的最短路径。
-
这就是A*搜索。现在,如果我们将这种方法与深度学习(一种让计算机从经验中学习和改进的方法,就像你在尝试了几次之后,会学到更好的方法)相结合,我们就能得到一个非常智能的系统。
-
这个系统不仅仅能在迷宫中找到最短的路径,它还能通过找到最佳解决方案来解决现实世界中更棘手的问题,就像你如何找出解决难题或游戏的最佳方法一样。
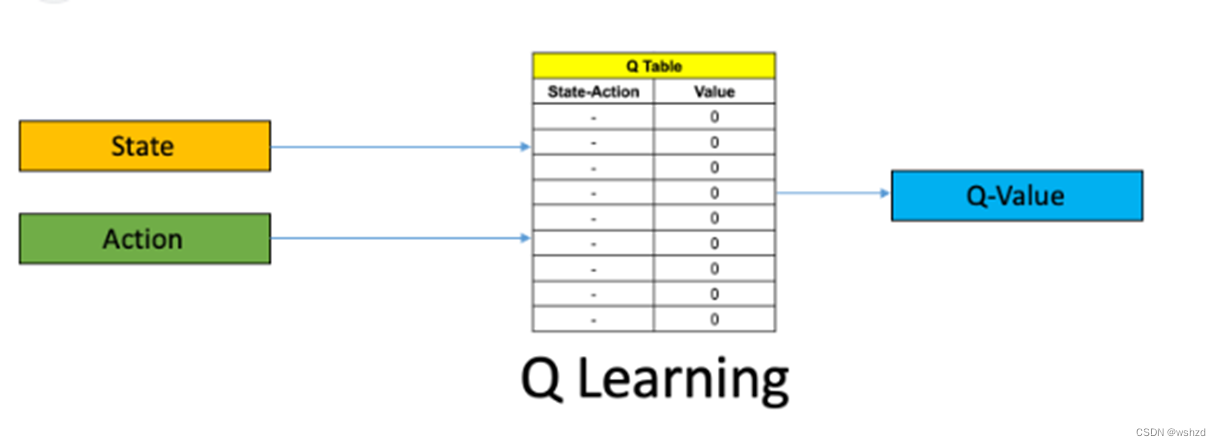
二、Q-learning介绍
? ? ? ?Q-learning 是强化学习(Reinforcement Learning)的一种,它是一种通过奖励做出正确决定的计算机,有时也惩罚做出错误决定的计算机的学习方法。这就好比训练宠物:如果宠物做了好事(比如听指令坐下),你就给它点吃的;如果它做了不太好的事(比如咬你的鞋子),你可能会说 "不 "或不理它。
1.环境(environment)和Agent在 Q-learning 中,你有一个 "环境"(如视频游戏或迷宫)和一个 "Agent"(人工智能或计算机程序),后者需要学习如何在这个环境中导航。
2.状态和行动:环境由不同的 "状态 "组成(就像游戏中的不同位置或场景),而Agent在每种状态下可以采取不同的 "行动"(如向左、向右移动、跳跃等)。
3.Q 表Q-learning 的核心是 Q 表。这就像一张大的小抄,告诉Agent在每个状态下最好采取什么行动。一开始,这个表里都是猜测,因为Agent对环境还不了解。
4.边做边学:Agent开始探索环境。每当它在某一状态下采取一项行动时,都会从环境中获得反馈--奖励(正积分)或惩罚(负积分)。这些反馈有助于Agent更新 Q 表,本质上是从经验中学习。
5.更新 Q 表:Q 表的更新公式既要考虑当前的回报,也要考虑未来的潜在回报。这样,Agent不仅能学会最大化当前奖励,还能考虑其行动的长期后果。
6.目标:随着时间的推移,经过足够的探索和学习,Q 表会变得越来越精确。Agent能更好地预测在不同状态下哪些行动会产生最高奖励。最终,它就能非常有效地驾驭环境。
把 Q 学习想象成玩一个复杂的视频游戏,随着时间的推移,你会学会最佳的动作和策略,从而获得最高分。起初,你可能不知道该采取哪些最佳行动,但随着你玩得越来越多,你就会从经验中吸取教训,并在游戏中取得更好的成绩。这就是人工智能通过 Q-learning 所做的事情--它从自己的经验中学习,在不同的场景中做出最佳决策。
三、是什么让 Q* 更好?
? ? ? ?Q-learning 是强化学习的一种形式,包括通过奖励理想结果来训练Agent做出决策。Q 搜索是一个相关的概念,它将类似的原则应用于搜索或探索信息。它们具有一些潜在的优势:
1.动态学习:与传统的 LLM 不同,使用 Q-learning 的系统可以根据新的数据或互动不断学习和调整。这意味着它可以随着时间的推移更新知识和策略,从而保持更高的相关性。
2.互动学习:Q-learning 系统可以从用户的互动中学习,从而使其具有更强的响应性和个性化。它们可以根据反馈调整自己的行为,从而带来互动性更强、以用户为中心的体验。
3.优化决策:Q-learning 可以找到实现目标的最佳行动,从而在各种应用中实现更有效、更高效的决策过程。
4.解决偏差:通过精心设计奖励结构和学习过程,Q-learning 模型可以避免或尽量减少训练数据中的偏差。
5.实现具体目标:Q-learning 模型以目标为导向,因此与传统 LLM 的通用性不同,Q-learning 模型适用于需要实现明确目标的任务。
谷歌也在做类似的事情

1.从 AlphaGo 到Gemini:谷歌在 AlphaGo 上的经验可能会影响 "Gemini"的发展,因为 AlphaGo 使用了蒙特卡洛树搜索(MCTS)。蒙特卡洛树搜索(MCTS)有助于探索和评估围棋等游戏中的潜在棋步,这一过程涉及预测和计算最有可能取得胜利的路径。
2.语言模型中的树搜索:在 "Gemini"这样的语言模型中应用树搜索算法,需要探索对话或文本生成过程中的各种路径。对于每个用户输入或对话的一部分,"Gemini"可以模拟不同的回应,并根据设定的标准(相关性、连贯性、信息量等)评估其潜在的有效性。
3.适应语言理解:这种方法需要根据人类语言的细微差别调整 MCTS 的原则,这与战略棋盘游戏相比是一个明显不同的挑战。这将涉及对语境、文化细微差别和人类对话流畅性的理解。
四、OpenAI 的 Q* (Q-Star)方法
1.Q-Learning 和 Q*?:Q-Learning 是一种强化学习(reinforcement learning),即Agent学会根据奖惩制度做出决策。Q* 将是一种高级迭代,有可能融入深度学习等元素,以增强其决策能力。
2.语言处理中的应用:在语言模型方面,Q* 可以让模型从互动中学习,从而改进其反应。它将根据对话中的有效信息不断更新策略,适应新的信息和用户反馈。
五、Gemini 与 Q* 对比
1.决策策略:假设的 "Gemini"和 Q* 都致力于做出最佳决策--"Gemini"通过探索不同的对话路径(树状搜索),而 Q* 则通过强化学习和适应。
2.学习和适应:每个系统都将从互动中学习。"Gemini"系统会评估不同对话路径的有效性,而 Q* 系统则会根据奖励和反馈进行调整。
3.复杂性处理:这两种方法都需要处理人类语言的复杂性和不可预测性,因此需要先进的理解和生成能力。
参考文献:
[1]?Open Ai's Q* (Q Star) Explained For Beginners - TheaiGrid
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!