Python中的【yield】关键字:让【函数】变身成为【生成器】
2023-12-15 00:05:30
引言
在Python中,yield是一个非常重要的关键字,它允许我们将一个函数变成一个生成器。生成器是一个非常有用的工具,可以按需生成数据,节省内存空间,并且在处理大数据集时特别有效。在本文中,小编将深入探讨yield关键字的工作原理以及如何使用它来创建生成器。小编将提供示例代码,并附上详细的注释来帮助读者更好地理解。
生成器
生成器是一种特殊的迭代器,它最重要的特性是可以根据需要生成数据,而不是一次性生成所有数据。生成器是通过定义一个包含yield关键字的函数来实现的。当生成器函数被调用时,它返回一个生成器对象。通过在需要时调用生成器对象的next()方法,我们可以逐个获取生成器中的数据项。
实现一个生成器
示例代码:
import time
def generator_func():
strs = ["I", "am", "GaoSiXiaoGe", "."]
for c in strs:
print("当前生成器【函数】generator_func\t将返回\t{}".format(c))
yield c # 可将yield理解为一种特殊的return ---> return了又没有完全return(看完代码后有同感的,可以动动发财的小手点个赞支持一下~)
time.sleep(5)
print("5秒已过!")
# 调用生成器函数, 返回生成器对象generator
generator_obj = generator_func()
# 根据需要生成数据 —— 每隔5s生成一个数据
for s in generator_obj: # 每次遍历生成器对象 --> 相当于调用生成器对象的next()方法
print("当前生成器【对象】generator_obj\t弹出了\t{}".format(s))
运行结果:
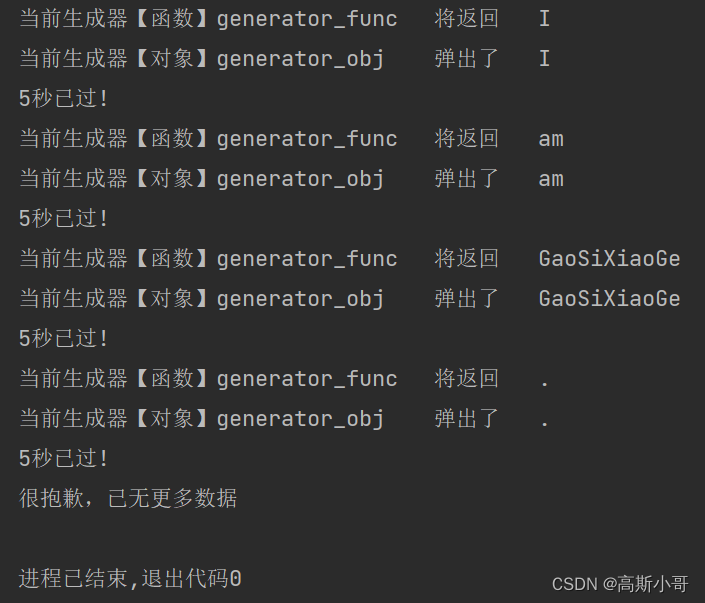
小结
- 【生成器】可以借助带有
yield关键字的函数来实现。 - 调用生成器【函数】,会返回一个生成器【对象】。
- 执行生成器函数时,每次遇到yield语句时,生成器函数会【暂停执行】并将数据返回给调用者(生成器对象)。
- 当需要生成下一个数据时,生成器【函数】会从停止的位置继续执行,直到找到下一个数据项。
生成器在PyTorch中的应用举例
使用生成器实现数据集的按需读取
示例代码:
import torch
from torch.utils.data import Dataset, DataLoader
# 自定义数据集类,继承自Dataset类
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
# 返回数据项和标签
return self.data[index][0], self.data[index][1]
def __len__(self):
# 返回数据集大小
return len(self.data)
# 定义数据集加载器类,继承自DataLoader类
class MyDataLoader(DataLoader):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def __iter__(self): # 生成器函数
# 使用生成器实现数据集的按需读取
for data, target in self.dataset:
yield data, target
# 创建数据集和加载器实例
data = [(torch.randn(5), torch.randn(1)) for _ in range(100)]
dataset = MyDataset(data)
dataloader = MyDataLoader(dataset, batch_size=10, shuffle=True) # 生成器对象
# 使用生成器对象dataloader迭代数据集
for data, target in dataloader:
print(data.shape, target.shape)
使用生成器实现自定义的数据增强功能
示例代码:
import torch
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
# 自定义数据集类,继承自Dataset类
class MyDataset(Dataset):
def __init__(self, data, transform=None):
self.data = data
self.transform = transform # 数据增强函数
def __getitem__(self, index):
# 返回数据项和标签
img, label = self.data[index]
if self.transform:
img = self.transform(img) # 对图像进行数据增强处理
return img, label
def __len__(self):
# 返回数据集大小
return len(self.data)
# 定义数据增强函数,使用生成器实现随机裁剪功能
def random_crop(image, crop_size):
h, w = image.shape[-2:] # 获取图像的高和宽
x = torch.randint(0, w - crop_size + 1, size=(1,)) # 随机生成裁剪起始点的x坐标
y = torch.randint(0, h - crop_size + 1, size=(1,)) # 随机生成裁剪起始点的y坐标
image = image[:, y:y+crop_size, x:x+crop_size] # 对图像进行裁剪处理
return image
# 创建数据集和加载器实例,并应用数据增强功能
data = [(torch.randn(3, 64, 64), torch.randn(1)) for _ in range(100)] # 创建包含100个随机生成的图像和标签的数据集
transform = transforms.Compose([transforms.Lambda(lambda x: random_crop(x, 32))]) # 定义数据增强函数,实现随机裁剪功能,将图像裁剪为32x32大小
dataset = MyDataset(data, transform=transform) # 创建数据集实例,并应用数据增强功能
dataloader = DataLoader(dataset, batch_size=10, shuffle=True) # 创建加载器实例,设置批次大小为10,并启用随机打乱功能
# 使用生成器迭代数据集,查看增强后的数据效果
for data, target in dataloader:
print(data.shape, target.shape) # 打印增强后的数据的形状,分别为(10, 3, 32, 32)和(10, 1)
结束语
- 亲爱的读者,感谢您花时间阅读我们的博客。我们非常重视您的反馈和意见,因此在这里鼓励您对我们的博客进行评论。
- 您的建议和看法对我们来说非常重要,这有助于我们更好地了解您的需求,并提供更高质量的内容和服务。
- 无论您是喜欢我们的博客还是对其有任何疑问或建议,我们都非常期待您的留言。让我们一起互动,共同进步!谢谢您的支持和参与!
- 我会坚持不懈地创作,并持续优化博文质量,为您提供更好的阅读体验。
文章来源:https://blog.csdn.net/qq_41813454/article/details/134916006
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!