Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation 论文总结
目录
论文摘要
??LLM逐渐成为了Text-to-SQL任务中的新范式。但过去由于缺乏较为系统的benchmark,人们难以设计有效、高效和经济的基于LLM的Text-to-SQL解决方案。为了应对这一挑战,本文首先对现有的prompt工程方法(包括问题表示、示例选择和示例组织)进行了系统而广泛的比较,并根据这些实验结果阐述了它们的优缺点。基于这些发现,作者的团队提出了一种新的集成解决方案, 称为DAIL-SQL,该解决方案以86.6%的执行准确率刷新了Spider排行榜,并设置了新的标准。作者的团队强调了prompt工程中的token efficiency,并在此指标下比较了先前的研究。此外,作者的团队还研究了开源LLM在上下文学习中的应用,并通过特定任务的监督微调进一步提高了它们的性能。他们探讨了开源LLM在Text-to-SQL方面的潜力,以及特定于任务的监督微调的优点和缺点。
Summary:问题表示(Question representation)
??论文中给出了主流的五种问题表示方法。
1. Basic Prompt( B S ? P BS\ _P BS?P?)
??Basic Prompt是最基础的问题表示,连Instruction都不包含,它主要由三部分组成:
??①table schemas;
??②natural language question prefixed by "Q: ";
??③response prefix "A: SELECT ";
??论文中给出了一个例子:

2. Text Representation Prompt ( T R ? P TR\ _P TR?P? )
??Text Representation Prompt是在Basic Prompt的基础上取消了问答前缀,在开头增加了Instruction,进行了简单的任务描述来引导LLM完成任务,示例如下:

3. OpenAI Demostration Prompt ( O D ? P OD\ _P OD?P?)
??这个问题表示方法出现在OpenAI官方关于Text-to-SQL任务的demo。相比 Text Representation Prompt ,它多了一条规则指示,“Complete sqlite SQL query only and with no explanation”,并且除了response的前缀,其他信息都用"#"注释。示例为:

4. Code Representation Prompt( C R ? P CR \ _P CR?P?)
?? Code Representation Prompt的思路较为不同,它用SQL的语法来全面地描述Database,也就是使用"CREAT TABLE" SQLs,涵盖了列的类型、主键、外键等信息,其余信息(如自然语言问题)都包在注释格式里,例子如下:

5. Alpaca SFT Prompt( A S ? P AS\ _P AS?P?)
??Alpaca SFT Prompt是针对有监督微调的LLM设计的。它的Prompt主要哦有三部分:Instruction(任务描述加自然语言问题)Input(数据库模式)和Response(生成回答的提示前缀),文本基于Markdown的语法,示例如下:

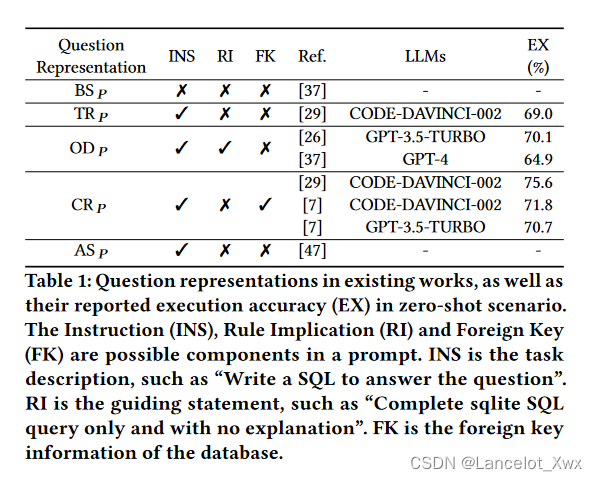
??对于上述的几种表示方法,论文中用一张表列出了它们的执行准确率,并讨论了它们在INS(Instruction)、RI(Rule Implication)、FK(Foreign Key)这些 Promp 组成成分上的区别。
Summary:示例选择(Example Selection)
??论文中,作者和他的团队主要研究的是跨域的Text-to-SQL任务,总结了四种示例选择的方法。
1. Random:随机挑选,示例选择的baselin
2. Question Similarity Selection ( Q T S ? S QTS\ _S QTS?S? )
??这个方法是要选择k个和目标问题最为相似的问题。首先,使用预训练的语言模型对示例库Q中的问题和目标问题做embedding,然后预定义一个距离度量(例如欧几里得距离或负余弦相似度),应用于每个示例-目标对。最后,利用 KNN 算法从 Q 中选择与目标问题最相似的k个问题对应的示例。
3. Masked Question Similarity Selection ( M Q S ? _ S MQS \ \_S MQS?_S)
??对于跨域的Text-to-SQL任务,文本中会含有大量的某领域特有的信息,为了消除这些信息带来的负面影响,可以把所有问题中的表名称、列名称和值都替换为mask token ,然后再计算embedding后的问题相似度。
4. Query Similarity Selection ( Q R S ? _ S QRS\ \_S QRS?_S)
??在这个方法中,关注的相似度是SQL查询语句的相似度。第一步是使用一个初始模型,基于目标问题和数据库生成SQL查询语句,用这个语句来近似目标希望得到的SQL查询语句。第二步是根据关键词,将生成的Query编码成二进制的离散语法向量。最后,同时基于SQL查询语句的相似性和示例的多样性来选择k个示例。
Summary:示例组织(Example Organization)
Full-Information Organization ( F I ? O FI\ _O FI?O?).
??
F
I
?
O
FI\ _O
FI?O?指的是在组织示例时,使用和目标问题的问题表示一样的表示方法,将原本的response前缀(“SELECT” token)换成了完整的SQL语句。在罗列完所有示例后,就描述目标问题。例子如图所示:

SQL-Only Organization ( S O ? O SO\ _O SO?O?)
??这个组织方法仅仅使用一段前缀的说明和各个示例的SQL查询语句,目的是在有限token数量内给出尽量多的示例,但是会造成信息缺失的不良影响,示例如下:

Key Point:DAIL-SQL
??基于对这些已有的方法的比较和分析,作者和他的团队提出了一种新的Text-to-SQL方法,称为DAIL-SQL。首先摆出论文中对于上下文学习在Text-to-SQL任务中的目标:
??
max
?
Q
′
,
σ
P
M
(
s
?
∣
σ
(
q
,
D
,
Q
′
)
)
\max _{Q^{\prime}, \sigma} \quad \mathbb{P}_{\mathcal{M}}\left(s^{*} \mid \sigma\left(q, \mathcal{D}, Q^{\prime}\right)\right)
maxQ′,σ?PM?(s?∣σ(q,D,Q′))
??
?s.t.????
∣
Q
′
∣
=
k
?and?
Q
′
?
Q
,?
\text { s.t.\ \ \ \ }\left|Q^{\prime}\right|=k \text { and } Q^{\prime} \subset Q \text {, }
?s.t.????∣Q′∣=k?and?Q′?Q,?
??其中,
Q
=
{
(
q
i
,
s
i
,
D
i
)
}
Q=\left\{\left(q_{i}, s_{i}, \mathcal{D}_{i}\right)\right\}
Q={(qi?,si?,Di?)},是一个由示例(自然语言问题
q
i
q_i
qi?和对应的SQL查询语句
s
i
s_i
si?)和数据库组成的三元组的集合,
M
\mathcal{M}
M是我们使用的LLM,
σ
\sigma
σ函数代表着我们选择的问题表示
q
q
q、数据库
D
\mathcal{D}
D和从
Q
Q
Q中挑选出来的k个示例选出的k个示例
Q
′
Q^{\prime}
Q′。也就是说,我们需要通过上下文学习的方法让LLM生成正确的SQL查询语句
s
?
s^{*}
s?的可能性最大。
示例选择方法:提出DAIL Selection( D A I L ? S DAIL\ _S DAIL?S?)
??在示例选择方面,论文提出了结合
M
Q
S
?
_
S
MQS \ \_S
MQS?_S方法和
Q
R
S
?
_
S
QRS\ \_S
QRS?_S方法的DAIL Selection((
D
A
I
L
?
S
DAIL\ _S
DAIL?S?),同时关注问题和查询语句的相似度。
??首先,把目标问题
q
q
q和候选集
Q
Q
Q中的示例问题
q
i
q_i
qi?中的领域专有词汇都进行mask,然后embedding再计算欧几里得距离,进行相似度排序;同时,计算pre-predicted 的SQL查询语句
s
′
s^{\prime}
s′和候选集
Q
Q
Q中的示例
s
i
s_i
si?的相似度。然后,筛选出查询语句相似度大于预设阈值的示例,按照之前问题相似度排好的顺序取k个示例。
示例组织方法:提出DAIL Organization ( D A I L ? O DAIL\ _O DAIL?O? )
??在示例组织方面,论文结合了
F
I
?
O
FI\ _O
FI?O?和
S
O
?
O
SO\ _O
SO?O?两种方法的优点,提出了
D
A
I
L
?
O
DAIL\ _O
DAIL?O?组织方法,关键点如下:
(1)既包含自然语言问题,又包含对应的SQL查询语句;
(2)为了节省token以表示更多的示例,去除了对数据库模式的表示。
问题表示方法:选择 C R ? P CR \ _P CR?P?
实验的一些发现
(1)关于问题表示,实验发现,外键和"无解释"的规则暗示都可能对Text-to-SQL任务有极大的益处,更多的规则暗示(Rule Implication)还有待探索;
(2)关于示例选择,实验发现,同时关注问题的相似度和查询语句的相似度是非常重要的。不过还存在查询语句相似度过低的情况,因为SQL查询语句的ground truth和用初始模型生成的查询语句存在较大差距。
(3)对于开源LLM,未经过微调的开源LLM的表现都逊色于OpenAI,且模型规模和模型表现呈正相关。不过,我们可以通过有监督微调来大大提升开源LLM在Text-to-SQL任务上的表现性能。但有一点需要注意,实验发现,经过微调后的LLM如果再使用上下文学习,反而会使精确匹配率和执行准确率下降。所以,微调后如何保留LLM的上下文学习能力有待探索。
Text-to-SQL任务的评价方法
??Text-to-SQL任务的评价方法主要包含两种,一个是精确匹配率(exact match ),另一个是执行准确率(execution accuracy)。精确匹配率指预测得到的SQL查询语句与正确的SQL查询语句在SELECT、WHERE等模块上的字符串完全匹配程度;执行准确率的正确执行是指在执行预测得到的SQL语句后,数据库能够返回正确答案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!