开集目标检测-标签提示目标检测大模型(吊打YOLO系列-自动化检测标注)
背景
大多数现有的对象检测模型都经过训练来识别一组有限的预先确定的类别。将新类添加到可识别对象列表中需要收集和标记新数据,并从头开始重新训练模型,这是一个耗时且昂贵的过程。该大模型的目标是开发一个强大的系统来检测由人类语言输入指定的任意对象,而无需重新训练模型,也称为零样本检测。该模型只需提供文本提示即可识别和检测任何物体。

- 关键可以生成标签,这样也不用标注了
- 同时能实现任何类别的识别
- 目标检测功能
- 学习可用

模型架构
Grounding DINO架构的核心在于它能够有效地弥合语言和视觉之间的差距。这是通过采用双流架构来实现的——使用 Swin Transformer 等文本主干提取多尺度图像特征,并通过 NLP 模型 BERT 等文本主干提取文本特征。
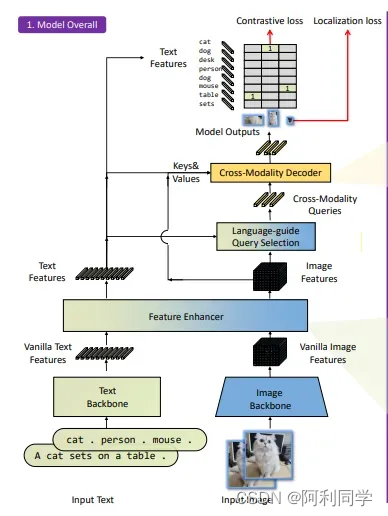
模型架构
这两个流的输出被馈送到特征增强器中,用于将两组特征转换成单个统一的表示空间。特征增强器包括多个特征增强器层。可变形自注意力用于增强图像特征,常规自注意力用于文本特征增强器。
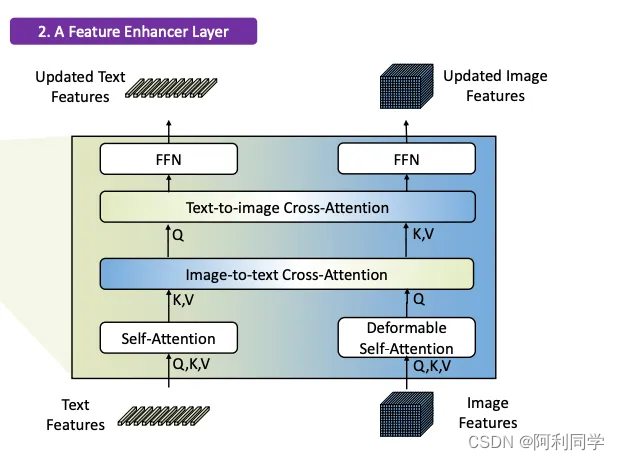
#特征增强层
Groundi旨在从输入文本指定的图像中检测对象。为了有效地利用输入文本进行对象检测,使用语言引导的查询选择来从图像和文本输入中选择最相关的特征。这些查询指导解码器识别图像中对象的位置,并根据文本描述为它们分配适当的标签。
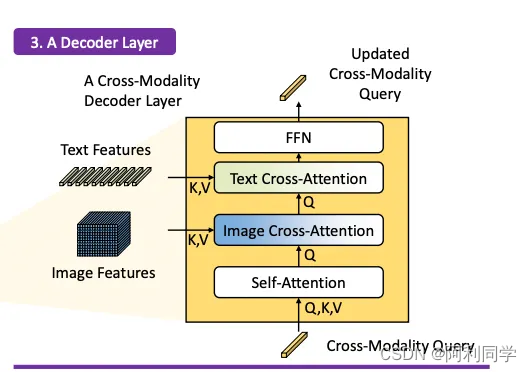
跨模态解码器
然后使用跨模态解码器来集成文本和图像模态特征。跨模态解码器通过一系列关注层和前馈网络处理融合特征和解码器查询来进行操作。这些层允许解码器有效地捕获视觉和文本信息之间的关系,使其能够细化对象检测并分配适当的标签。在此步骤之后,模型继续进行对象检测的最后步骤,包括边界框预测、特定于类的置信度过滤和标签分配。、
代码运行
执行
在下一节中,我们将演示开放集对象检测。在这里,我们将使用预先训练的 Grounding 模型通过摄像头检测“带盖玻璃”(如文本提示)。
安装接地 DINO 🦕
首先,包含 PyTorch 实现和 Grounding 预训练模型的github 存储库被克隆到您的本地目录。在克隆 github 存储库的同一目录中创建一个名为 main.py 的文件。该文件将包含通过摄像头输入执行 Grounding 模型的主脚本。首先通过添加以下命令导入相关库和 Grounding 模块。代码的最后两行导入所需的推理模块。
import modules
import os
import cv2
import numpy as np
from PIL import Image
import groundingdino.datasets.transforms as T
from groundingdino.util.inference import load_model, load_image, predict, annotate
安装环境
pip install -r requirements.txt
下载bert-base-uncased
https://huggingface.co/models
找到后,下载后放到本地,否则代码会出现异常
运行
python demo/inference_on_a_image.py -c 配置文件 Ground/config/Grounding_OGC.py -p 权重:.pth
-i 输入 input -o输出路径 -t "标签:car" --cpu-only
结果



怎么样,结果还不错把
关键可以生成标签,这样也不用标注了
已经把批量生成.json .xml文件脚本完成!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!