mysql索引优化-MyISAM&InnoDB
2023-12-26 14:50:35
MyISAM:
- 索引文件和数据文件是分离的(非聚集)
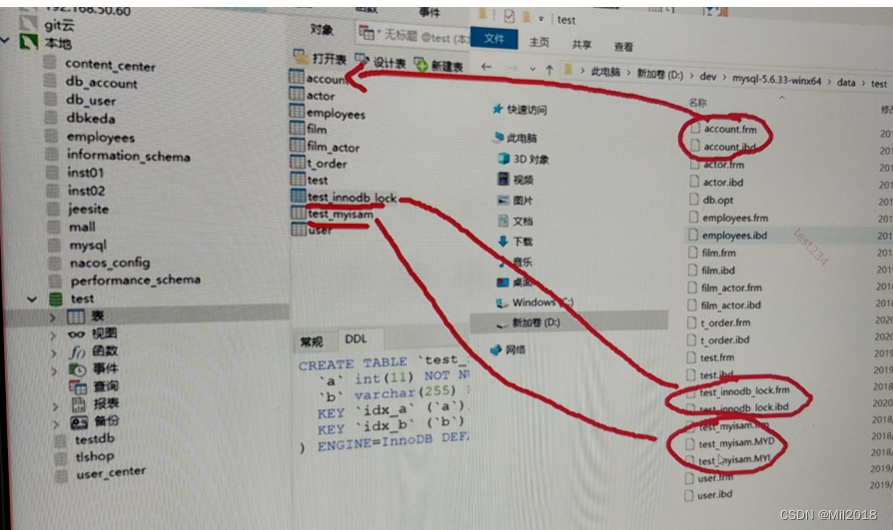
frm:表结构
MYD:数据
MYI:索引
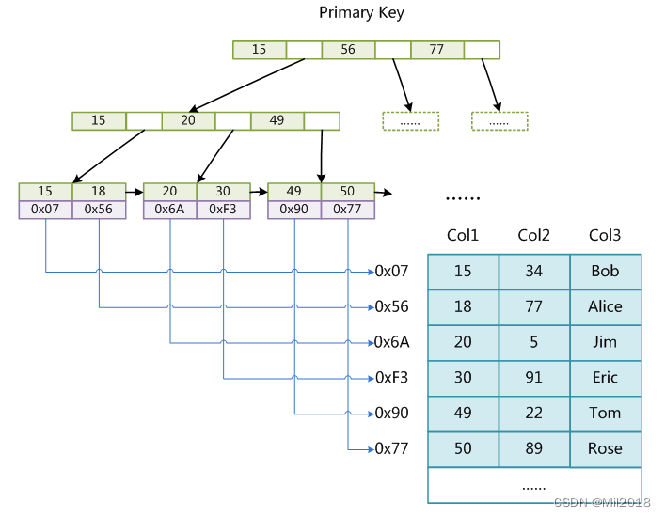
前置条件:Col1为索引,mysql会以B+树的数据结构将Col1组织成叶子节点,放置在MYI文件中,数据行存放在MYD文件中
查找Col1=30过程(结合:mysql优化-索引-CSDN博客- 当需要查找col=30的值过程):在ram中从根节点查找(去到MYI文件中),找到30后,拿到叶子节点的Data元素(存放索引所在行的磁盘文件地址:0xF3),去到MYD文件定位到具体的数据行
InnoDB:
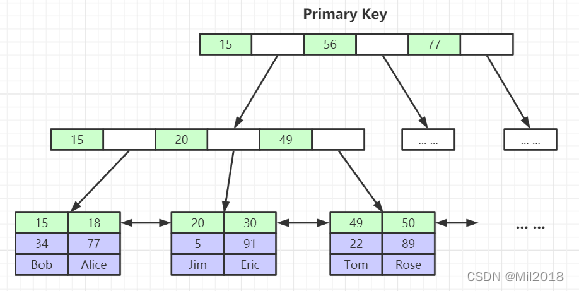
- 索引实现(聚集)
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
frm:表结构
ibd:数据和索引放在一起
- 聚集索引-叶节点包含了完整的数据记录
- 为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
1)因为表数据文件本身按B+树组织,而B+树要求从左往右递增,通过自增主键便于组织B+树
2)如果没有建,mysql会选择【所有元素都不相同的一列数据】自动创建主键
3)如果没有【所有元素不相同的一列数据】,mysql会自动创建隐藏列,类似lowid
4)以上,mysql的资源是很宝贵的,这种简单的事情应该自己做,不该交给mysql,减少mysql的工作
5)为什么是整型:
5.1)【整型比大小】的效率要高于【字符串比大小(转ASCII来比大小)】
5.2)前者占用的空间也更小(数据和索引都是存在磁盘(SSD),性能比电脑的SSD要高,也更贵)
- 聚集索引和非聚集索引那种更快?
从结构来说,聚集索引更快,可以直接查找到数据行
- 为什么非主键索引结构叶子节点存储的是主键值?
(一致性和节省存储空间)
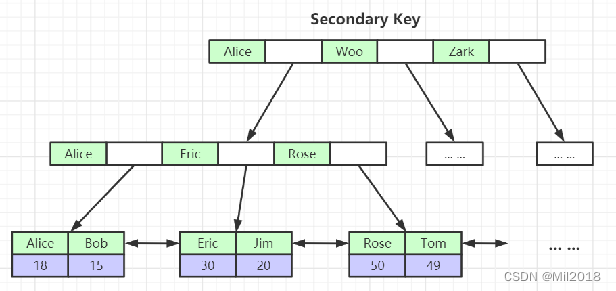
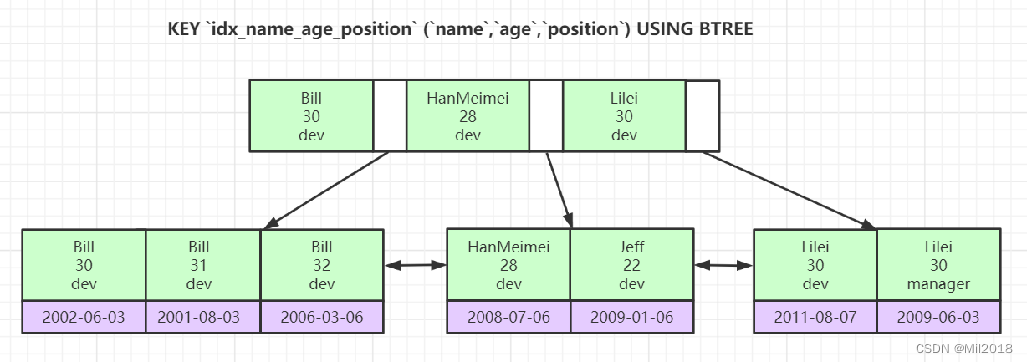
联合索引的底层存储结构长什么样?
文章来源:https://blog.csdn.net/u014563917/article/details/135210926
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!