多任务数据采集
进程:操作系统中资源分配的基本单位
线程:使用进程资源处理具体任务
一个进程中可以有多个线程:进程相当于一个公司,线程是公司里面的员工。
一 多线程
多线程都是关于功能的并发执行。而异步编程是关于函数之间的非阻塞执行,我们可以将异步应用于单线程或多线程当中。多线程是与具体的执行者相关的,而异步是与任务相关的。
并发和并行
一个程序在计算机中运行,其底层是处理器通过运行一条条的指令来实现的。
并发
并发,英文叫作 concurrency。它是指同一时刻只能有一条指令执行,但是多个线程的对应的指令被快速轮换地执行。比如一个处理器它先执行线程A的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A执行一段时间。
由于处理器执行指令的速度和切换的速度非常非常快,人完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行。但微观上只是这个处理器在连续不断地在多个线程之间切换和执行,每个线程的执行一定会占用这个处理器一个时间片段,同一时刻,其实只有一个线程在执行。
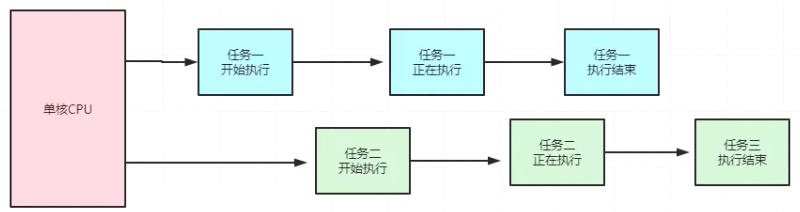
并行
并行,英文叫作 paralel。它是指同一时刻,有多条指今在多个处理器上同时执行,并行必须要依赖于多个处理器,不论是从宏观上还是微观上,多个线程都是在同一时刻一起执行的。
并行只能在多处理器系统中存在,如果我们的计算机处理器只有一个核,那就不可能实现并行。而并发在单处理器和多处理器系统中都是存在的,仅仅依靠一个核,就能实现并发。
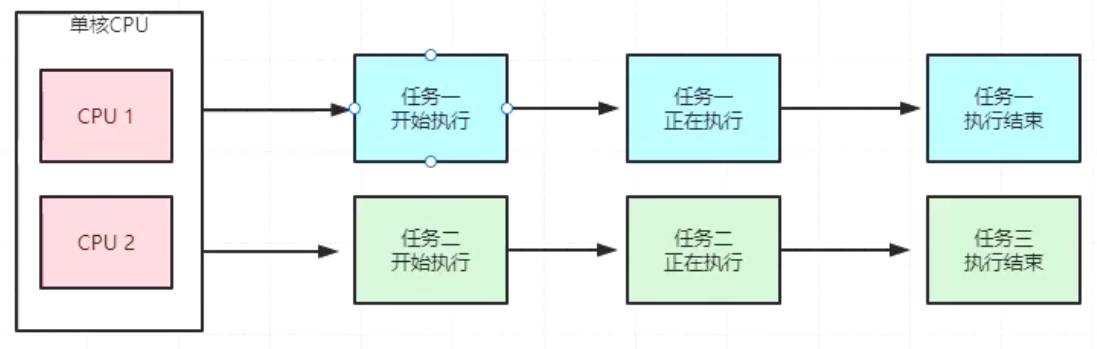
总结:
当系统有一个以上CPU时,则线程的操作可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程不抢占CPU资源,可以同时进行,这种方式称之为并行(Parallel)
(一)单线程
import requests,time
import threading
def test(url):
resp = requests.get(url) # 发送GET请求到指定的URL
# 可以在这里处理响应,例如打印状态码或内容
# print(resp.status_code)
if __name__ == '__main__':
start = time.time()
url = 'https://www.baidu.com'
for i in range(10):
test(url)
resp = time.time()-start
print(resp,'单线程')(二)多线程
import requests,time
import threading
def test(url):
resp = requests.get(url) # 发送GET请求到指定的URL
# 可以在这里处理响应,例如打印状态码或内容
# print(resp.status_code)
if __name__ == '__main__':
start = time.time()
url = 'https://www.baidu.com'
for i in range(10):
test(url)
resp = time.time()-start
print(resp,'单线程')
if __name__ == '__main__':
start1 = time.time() # 记录当前时间用于后面计算总的运行时间
url = 'https://www.baidu.com'
threads = [] # 用于存储线程对象的列表
# 创建并启动10个线程
for i in range(10): #创建10个线程
# 创建一个线程对象 target代表调用的函数 args代表给函数传递的参数
thread = threading.Thread(target=test, args=(url,)) # 注意args是一个元组,即使只有一个元素
threads.append(thread) # 将线程加入到列表中
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join() #意思是等所有的线程完成了再执行下面的操作
elapsed_time = time.time() - start1 # 计算总的运行时间
print(elapsed_time, '多线程') # 打印多线程执行时间
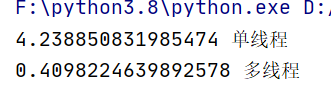
(三)线程样例
# 导入 threading 和 time 模块
import threading, time
# 定义一个名为 target 的函数,它接受一个参数 second
def target(second):
# 打印当前线程的名称和一条开始运行的消息
print(f'Threading {threading.current_thread().name} is running')
# 打印当前线程将要休眠的秒数
print(f'Threading {threading.current_thread().name} sleep {second}s')
# 使线程休眠指定的秒数
time.sleep(second)
# 打印当前线程结束的消息
print(f'Threading {threading.current_thread().name} is ended')
# 打印主线程正在运行的消息
print(f'Threading {threading.current_thread().name} is running')
# 创建一个循环,循环值为列表 [1, 5] 中的元素
for i in [1, 5]:
# 创建一个新的线程对象,目标函数是 target,参数是列表中的当前元素
thread = threading.Thread(target=target, args=[i])
# 启动新创建的线程
thread.start()
# 打印主线程已经结束的消息
print(f'Threading {threading.current_thread().name} is ended')
'''
输出
Threading MainThread is running
Threading Thread-1 is runningThreading MainThread is ended
Threading Thread-1 sleep 1s
Threading Thread-2 is runningThreading MainThread is ended
Threading Thread-2 sleep 5s
Threading Thread-1 is ended
Threading Thread-2 is ended
'''(四)线程等待
# 导入 threading 和 time 模块
import threading, time
# 定义一个名为 target 的函数,它接受一个参数 second
def target(second):
# 打印当前线程的名称和一条开始运行的消息
print(f'Threading {threading.current_thread().name} is running')
# 打印当前线程将要休眠的秒数
print(f'Threading {threading.current_thread().name} sleep {second}s')
# 使线程休眠指定的秒数
time.sleep(second)
# 打印当前线程结束的消息
print(f'Threading {threading.current_thread().name} is ended')
# 主线程退出,子线程才退出 会出问题
print(f'Threading {threading.current_thread().name} is running')
t = []
# 创建一个循环,循环值为列表 [1, 5] 中的元素
for i in [1, 5]:
# 创建一个新的线程对象,目标函数是 target,参数是列表中的当前元素
thread = threading.Thread(target=target, args=[i])
t.append(thread)
# 启动新创建的线程
thread.start()
# 打印主线程已经结束的消息
for i in t:#这里面是线程1和线程2,主线程在外边
i.join() # 作用 阻塞下
print(f'Threading {threading.current_thread().name} is ended')
(五)线程池
线程池,是一种线程的使用模式,它为了降低线程使用中频繁的创建和销毁所带来的资源消耗与代价。通过创建一定数量的线程,让他们时刻准备就绪等待新任务的到达,而任务执行结束之后再重新回来继续待命。
# 导入 ThreadPoolExecutor 类,这个类是 concurrent.futures 模块提供的一个高层接口
# 用于异步执行使用线程的调用
from concurrent.futures import ThreadPoolExecutor
# 打印出传入的 UR
def crawl(url):
print(url)
if __name__ =='__main__':
base_url ='https://jobs.51job.com/pachongkaifa/p{}'
# 使用with 语句和 ThreadPoolExecutor(10) 创建一个可以容纳 10 个线程的线程池。
# with 语句的上下文管理特性确保线程池在执行完毕后会被正确关闭。
with ThreadPoolExecutor(10) as f:
# 创建1到14 14个数字表示页码
for i in range(1,15):
# 使用f.submit(crawl, url=base_url.format(i))提交一个任务给线程池
# submit方法安排执行函数crawl,并传入格式化后的URL作为参数
f.submit(crawl,url=base_url.format(i))多线程采集实例--采集王者荣耀皮肤图片
'''
头像地址
'https://game.gtimg.cn/images/yxzj/img201606/heroimg/537/537-smallskin-3.jpg'
皮肤地址
'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/537/537-bigskin-3.jpg'
露娜
https://game.gtimg.cn/images/yxzj/img201606/heroimg/146/146.jpg
{"ename": 146,
"cname": "露娜",
"id_name": "luna",
"title": "月光之女",
"new_type": 0,
"hero_type": 1,
"hero_type2": 2,
"skin_name": "月光之女|哥特玫瑰|绯红之刃|紫霞仙子|一生所爱",
"moss_id": 3934}
'''
import requests
import os
import json
import threading
import time
from lxml import etree
h = []
s = time.time()
def pa(j):
num = j['ename']
name = j['cname']
res2 = requests.get('https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(num))
res2_decode = res2.content.decode('gbk')
_element = etree.HTML(res2_decode)
# 获取皮肤名称
element_img = _element.xpath('.//div[@class="pic-pf"]/ul/@data-imgname')
name_img= element_img[0].split('|')
# 输出格式如下
# ['正义爆轰&0', '地狱岩魂&12', '无尽征程&1', '寅虎·御盾&93']
len1 = len(name_img)
for i in range(0,10):
res1 = requests.get('https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg'.format(num,i+1))
if res1.status_code==200:
try:
aa = name_img[i].find('&')
bb = name_img[i][:aa]
except Exception as e:
print(e)
# 返回 如正义爆轰
res_img = res1.content #将图片转换成二进制方便存储
a = 'D:/桌面/王者荣耀/'+str(name)
b = 'D:/桌面/王者荣耀/'+str(name)+'/'+bb+'.jpg'
if not os.path.exists('D:/桌面/王者荣耀/'):
os.makedirs('D:/桌面/王者荣耀/')
if not os.path.exists(a):
print(f'正在创建{name}文件夹')
os.mkdir(a)
with open(b,'wb') as f:
f.write(res_img)
print(name,bb)
else:
break
def duo():
resp = requests.get('https://pvp.qq.com/web201605/js/herolist.json')
data = json.loads(resp.text)
for j in data:
t = threading.Thread(target=pa,args=(j,))
t.start()
h.append(t)
for k in h:
k.join()
if __name__ == '__main__':
duo()
g = time.time()
print("用时:",g-s)
二 多进程
参考文档:https://docs.python.org/zh-cn/3/library/multiprocessing.html
进程内置方法
run()
表示进程活动的方法。你可以在子类中重载此方法。标准run()方法调用传递给对象构造函数的可调用对象作为目标参数(如果有),分别从args和kwargs 参数中获取顺序和关键字参数。
start()
启动进程活动。这个方法每个进程对象最多只能调用一次。它会将对象的 run()方法安排在一个单独的进程中调用.
join(timeout)
如果可选参数 timeout是 one (默认值),则该方法将阻赛,直到调用 oin 方法的进程终止,如果 timeout是一个正数,它最多会阻塞 timeout秒,请注意,如果进程终止或方法超时,则该方法返回 None 。检查进程的 xitcode 以确定它是否终止。一个进程可以被join 多次。进程无法iin自身,因为这会导致死锁。尝试在启动进程之前ioin进程是错误的。
name()
进程的名称。该名称是一个字符串,仅用于识别目的。它没有语义。可以为多个进程指定相同的名称。初始名称由构造器设定。如果没有为构造器提供显式名称,则会造一个形式为Process-N1:N2:..Nk的名称,其中每个Nk 是其父亲的第 N 个孩子。
is_alive()
返回进程是否还活着。粗略地说,从 start()方法返到子进程终止之前,进程对象仍处于活动状态。
daemon
daemon 进程在 Python 的 multiprocessing 模块中有特殊的含义。它是一个指示该进程是否是守护进程的布尔标志。在计算机科学中,守护进程(或守护线程)一般指在后台运行的进程(或线程),它独立于控制终端,并且周期性地执行某种任务或等待处理某些发生的事件。然而,在 Python 的 multiprocessing 模块中,守护进程有点不同。
当你在一个 multiprocessing.Process 对象上设置 daemon = True 时,这意味着:
-
该进程是守护进程:该进程的生命周期不应比其父进程长。这意味着,当父进程结束时,守护进程也会被终止(不管守护进程是否完成了它的工作)。守护进程通常用于不需要明确停止的任务,因为它们会随着父进程的结束而自动停止。
-
在守护进程退出时,它的子进程也会被终止:守护进程不能创建子进程,如果尝试创建那将会抛出异常。这是为了防止产生孤儿进程,即当守护进程被终止时,它的子进程仍在运行,但没有任何进程管理它们。
-
它们不是 Unix 守护进程:在 Unix 中,守护进程是一个在后台运行的服务进程,通常在系统启动时启动,并直到系统关闭时才终止。Python 的守护进程不是这样的服务进程,而只是普通的进程,只不过它的生命周期受到父进程的控制。
-
它们在父进程退出后不会被操作系统的任何初始化系统“收养”:这意味着守护进程不会继续在后台运行,一旦父进程结束,守护进程也就结束了。
-
被终止的守护进程不会有机会进行资源清理:例如,打开的文件不会被正确关闭,所以使用守护进程时要小心。
如果你想要一个进程在父进程结束后继续运行,那么你不应该将它设置为守护进程。守护进程的典型用例是作为某种形式的服务提供者,其中服务在父进程运行时保持活动,但不需要在父进程结束后保持运行。
除了 threading.Thread API,Process 对象还支持以下属性和方法
pid
返回进程ID。在生成该进程之前,这将是 None。
(一)进程样例
import multiprocessing
def progress(index):
print(f'Process:{index}')
if __name__ == '__main__':
for i in range(5):
# 每循环一次,开启一个进程
p = multiprocessing.Process(target=progress,args=(i,))
p.start()(二)进程等待
import multiprocessing
def progress(index):
print(f'Process:{index}')
if __name__ == '__main__':
processes = []
for i in range(5):
# 每循环一次,开启一个进程
p = multiprocessing.Process(target=progress, args=(i,))
p.start()
processes.append(p) # 将进程添加到列表中
for p in processes:
p.join() # 等待所有进程完成
(三)进程池
from multiprocessing import Pool
import requests
def scrape(url):
try:
requests.get(url)
print(f'URL- {url} -Scraped')
requests.ConnectionError
# 是在使用requests库进行HTTP请求时,如果在连接过程中遇到网络问题
# (例如,DNS查询失败、拒绝连接等)时抛出的异常。
except requests.ConnectionError :
print(f'URL- {url} -not Scraped')
if __name__ == '__main__':
pool = Pool(processes=3)
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'http://xxxyxxx.net'
]
pool.map(scrape,urls)
# for url in urls:
# scrape(url)
pool.close()多进程爬取摩托信息
import requests
import multiprocessing
from multiprocessing import Pool
from lxml import etree
import pymysql
# maps1接收一个参数,然后根据X的值返回不同结果
# 1、如果X是一个非空序列(列表,元组,字符串等)返回序列第一个元素
# 2、如果X是一个空的序列或者None,返回X本身,此时是一个空的序列或None
maps1 = lambda x:x[0] if x else x #通俗点 如果X不为空返回X[0],否则返回X
'''
xpath取值返回的是列表
如果使用[0]数据为空就会给程序报错
使用lambda表达式进行数据判断不为空才取值,为空就返回原值
'''
datas = []
def request(url):
'''
请求模块,负责网络请求
'''
headers = {
'Cookie':'countsql=%5BS%5Fchexi%5Dwhere+1%3D1; fenyecounts=1218; '
'Hm_lvt_f0b29a0b9bbbbaf0f3027855bba2f05a=1703216256; '
'ASPSESSIONIDSESQSQAD=GDBEFCGCAPFOGEEOMJIAAIIB; '
'Hm_lpvt_f0b29a0b9bbbbaf0f3027855bba2f05a=170323319',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
try:
res = requests.get(url,headers=headers)
if res.status_code == 200:
res.encoding = 'gb2312'
parse(res.text)
return res.text
else:
res.raise_for_status()
except requests.RequestException as e:
print(f'请求出错信息是{e}')
def parse_xpath(obj,tag):
'''
负责页面的数据解析工作
'''
# 将获得网页代码根据tag路径解析出想要的内容并返回
html = etree.HTML(obj)
text = html.xpath(tag)
return text
def parse(res):
'''
总体业务:获取需要的数据
'''
url = '//ul[@class = "goods_list"]/li'
items = parse_xpath(res,url)
# html = etree.HTML(res)
# items = html.xpath(url)
for item in items:
title = maps1(item.xpath('./p[@class="name"]/a/text()'))
price = maps1(item.xpath('./p[@class="price_wrap"]//text()'))
price = int(price[1:])
# print({'品牌':title,'价格':price})
# print('='*50)
datas.append([title,price])
for data in datas:
save_date(data)
def mysql_conn():
'''
数据库连接模块
'''
db = pymysql.connect(host='localhost',user='root',password='123456',db='test1',port=3306)
cuesor = db.cursor()
return db,cuesor
def save_date(data):
'''
保存数据模块
'''
db,cursor = mysql_conn()
try:
sql = 'insert into moto(name,price) values(%s,%s)'
cursor.execute(sql,(data[0],data[1]))
db.commit()
except Exception as e:
print(f'出错信息{e}')
db.rollback()
finally:
cursor.close()
db.close()
def run():
'''
入口函数
开启任务
多任务从这里面出发
'''
import time
s = time.time()
url = 'https://www.2smoto.com/pinpai.asp'
res = request(url)
#获得总页数
# # htmls = etree.HTML(res)
# # html = maps1(htmls.xpath('.//div[@id="prolist"]/table//a[contains(text(),"尾页")]/@href'))[0]
# # html = maps1(parse_xpath(res,'.//div[@id="prolist"]/table//a[contains(text(),"尾页")]/@href'))
html = parse_xpath(res,'.//div[@id="prolist"]/table//a[contains(text(),"尾页")]/@href')
if html:
html = html[0]
count = html.split('=')[-1]
print(f'总共{count}页')
else:
print("没有获取到总页数")
cpu_count = multiprocessing.cpu_count() #获取系统CPU数量
print("CPU数量是:",cpu_count)
pool = Pool(processes=cpu_count) # 创建进程数量等于cpu个数的进程池
for i in range(1,int(count)+1):
url = 'https://www.2smoto.com/pinpai.asp?ppt=&slx=0&skey=&page={}'.format(i)
#开启多任务 每一条进程处理1个页面的数据
pool.apply_async(request,(url,))
pool.close() #关闭进程池,关闭之后,不能再向进程池里面添加进程
pool.join() # 当进程池中所有的进程执行完毕后,主进程才能执行
print(f'程序耗时{time.time()-s}s')
if __name__ == '__main__':
run()三 异步携程
我们知道爬虫是 I/O 密集型任务,比如如果我们使用 requests 库来爬某个站点,发出个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何的事情,对于这种情况我们有没有优化方案呢?
基本概念
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。
阻塞
阻赛状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的
同步/异步关注的是消息通信机制(synchronous communication/asynchronous communication)。阻塞/非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态

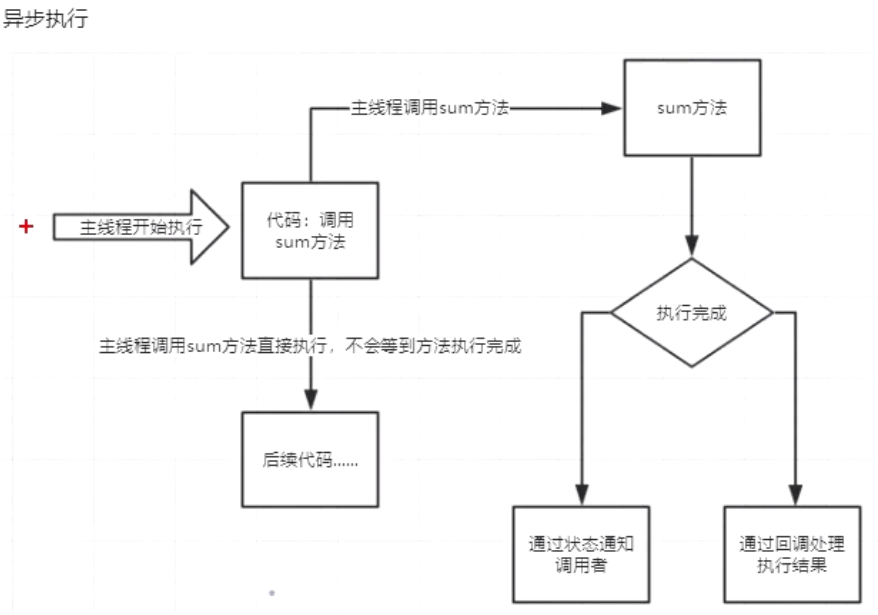
(一)概念
pip install aiohttp
aliohtp 是一个基于 asyncio 的异步 HTTP 网络模块,它既提供了服务端,又提供了客户端。其中我们用服务端可以搭建一个支持异步处理的服务器
asvnc用来声明一个函数为异步函数
awat 用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序
(二)同步
import time
import httpx
def main():
with httpx.Client() as client:
for i in range(50):
res = client.get('https://www.example.com')
print(f'第{i+1}次请求,响应状态码:{res.status_code}')
if __name__ == '__main__':
start = time.time()
main()
end =time.time()
print(f'同步发送50次请求,耗时{start-end}秒')(三)异步概念
import asyncio
import time
import httpx
async def req(client,i):
res = await client.get('https://www.example.com')
print(f'第{i+1}次请求,响应状态码:{res.status_code}')
return res
async def main():
async with httpx.AsyncClient() as client:
task_lisk = []
for i in range(50):
res = req(client,i)
task = asyncio.create_task(res)
task_lisk.append(task)
await asyncio.gather(*task_lisk)
if __name__ =='__main__':
start = time.time()
asyncio.run(main())
end = time.time()
print(f'异步发送50次请求,耗时{end-start}')本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!