Hive ACID事务表
2024-01-10 12:18:43
环境:hive 3.1.0
执行引擎:hive on tez
- 什么是hive ACID?
hive官网对于ACID的介绍:
https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions
中文文档关于ACID的介绍:
https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/Hive_Transactions.html
其实和传统数据库中所说的ACID有异曲同工之妙: - 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。 - 一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
举例说明:张三向李四转100元,转账前和转账后的数据是正确的状态,这就叫一致性,如果出现张三转出100元,李四账号没有增加100元这就出现了数据错误,就没有达到一致性。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
其中事务(Transaction)是访问和更新数据库的程序执行单元;事务中可能包含一个或多个sql语句,而ACID是衡量事务的4个维度。hive0.13之后提供了行级别ACID,
常见的INSERT、UPDATE和DELETE已经在hive0.14开始支持,先创建一张默认结构的hive表
create table test.trans_table1(column1 string,column2 string);
SHOW CREATE TABLE查看其建表语句:
CREATE TABLE `test.trans_table1`(
`column1` string,
`column2` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://ambari-hadoop1:8020/warehouse/tablespace/managed/hive/test.db/trans_table1'
TBLPROPERTIES (
'bucketing_version'='2',
'transactional'='true',
'transactional_properties'='default',
'transient_lastDdlTime'='1703744670')
发现其配置项中有三个和事务相关的选项:
- transactional:是否启用表的事务支持
- transactional_properties:指定了事务的属性
1.default: 默认值,表示支持插入、更新、删除操作。
2.insert_only: 仅支持插入操作,不支持更新和删除。
3.insert_only_external: 仅支持插入操作,对于外部表。 - transient_lastDdlTime:最后一次DDL日期时间
hive默认创建存储格式为ORC的事务表,对表执行一次insert values操作发现增加了一个delta开头的目录
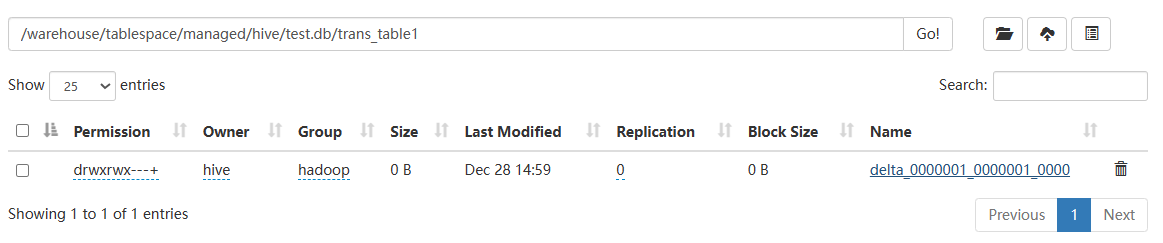
其下有两个文件_orc_acid_version和bucket_00000

而delete操作也同样会生成目录:

而UPDATE操作则会同时生成两个目录:

先创建一个delete前缀的目录,再创建一个代表insert的delta前缀目录,即先删除后插入。
以上目录的命名规范格式为 delta_minWID_maxWID_stmtID,即 delta 前缀、写事务的 ID 范围、以及语句 ID。 - 针对写事务(INSERT、DELETE 等),Hive 还会创建一个写事务 ID(Write ID),该 ID 在表范围内唯一。
- 语句 ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
_orc_acid_version 的内容是 2,即当前 ACID 版本号是 2。而bucket开头的文件则是实际的数据内容,由于存储格式是ORC,可以使用以下方法查看:
hive --orcfiledump /warehouse/tablespace/managed/hive/test.db/trans_table1/delta_0000001_0000001_0000/bucket_00000
可以查看相关元数据,但并非数据本身,这里不做过多解析:
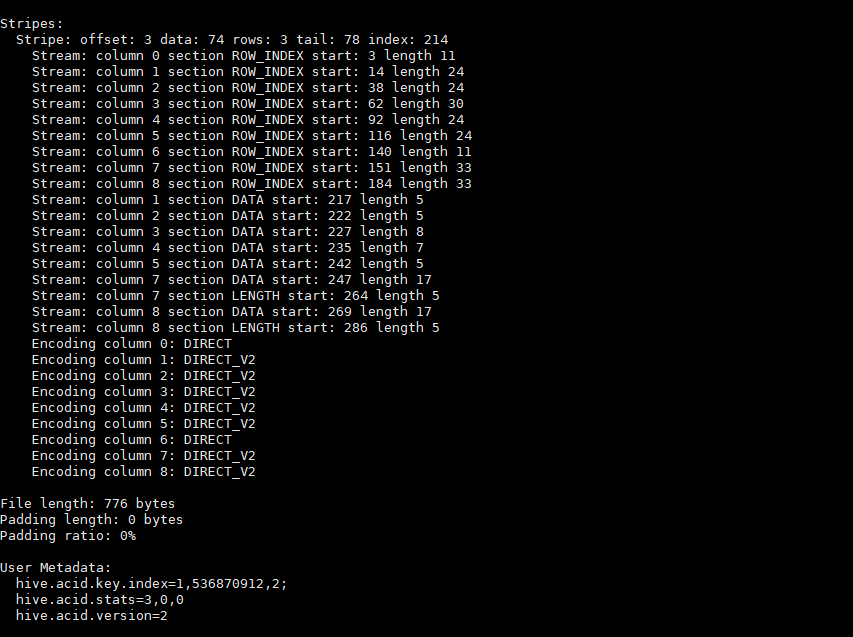
hive --orcfiledump -d /warehouse/tablespace/managed/hive/test.db/trans_table1/delta_0000001_0000001_0000/bucket_00000
则可以查看相关数据内容:

- operation 0 表示插入,1 表示更新,2 表示删除。由于使用了 split-update,UPDATE 是不会出现的;
- originalTransaction是该条记录的原始写事务 ID。对于 INSERT 操作,该值和 currentTransaction是一致的。对于 DELETE,则是该条记录第一次插入时的写事务 ID;
- bucket是一个 32 位整型,由 BucketCodec 编码,各个二进制位的含义为:
1-3 位:编码版本,当前是 001;
4 位:保留;
5-16 位:分桶 ID,由 0 开始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的数量决定的。该值和 bucket_N 中的 N 一致;
17-20 位:保留;
21-32 位:语句 ID;
举例来说,整型 536936448 的二进制格式为 00100000000000010000000000000000,即它是按版本 1 的格式编码的,分桶 ID 为 1; - rowId 是一个自增的唯一 ID,在写事务和分桶的组合中唯一;
- currentTransaction 当前的写事务 ID;
- row 具体数据。对于 DELETE 语句,则为 null
还可以通过 row__id 这个虚拟列进行查看(originalTransaction, bucket, rowId)
select row__id,column1,column2 from test.trans_table1;

注意row__id是两个"_"符合。
还有个问题由于每次DML的执行都会产生对应小文件,随着时间推移DML执行次数的增多,会产生越来越多的小文件,而过多的小文件对HDFS会产生不利的影响,比如增加namenode的内存占用等等,为此hive引入了压缩Compaction的概念。
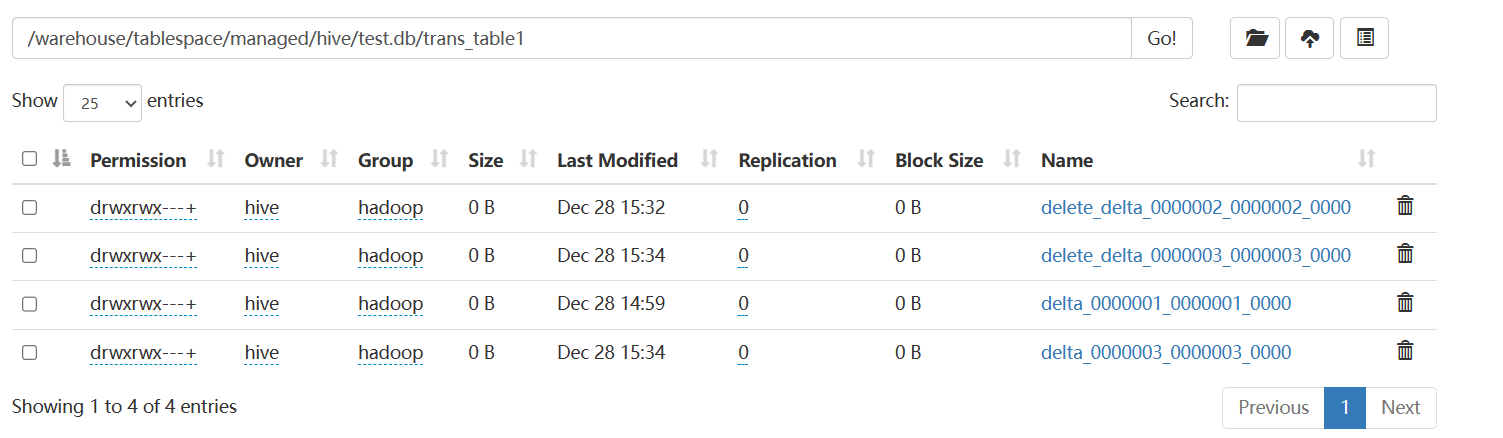
Minor Compaction 会将所有的 delta 文件压缩为一个文件,delete 也压缩为一个。压缩后的结果文件名中会包含写事务 ID 范围,同时省略掉语句 ID。压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE trans_table1 COMPACT 'minor';
压缩前:
压缩后:
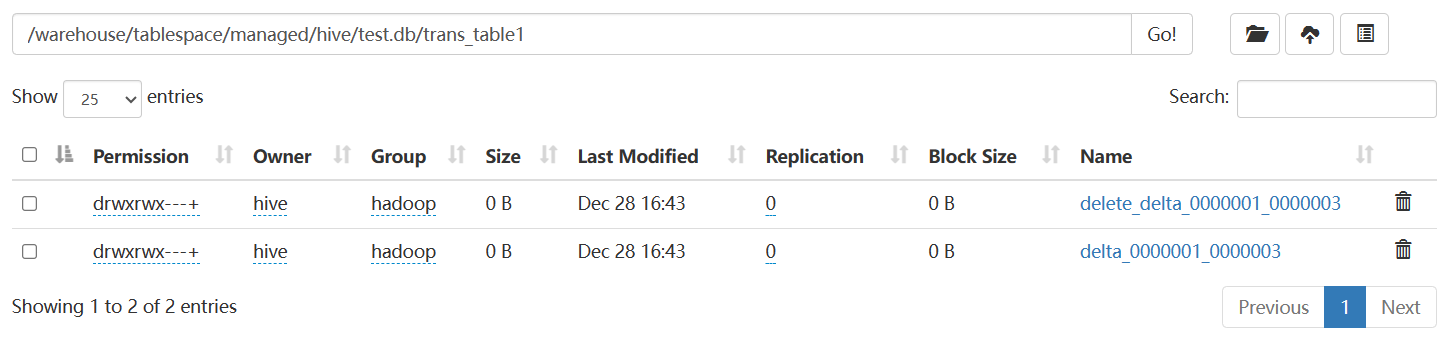
查看压缩后的文件发现,插入操作产生的数据都被合并起来:

同样删除操作的数据也被合并在了一起:

因此Minor Compaction 不会删除任何数据。
而Major Compaction则会将所有文件合并为一个文件,以 base_N 的形式命名,其中 N 表示最新的写事务 ID。已删除的数据将在这个过程中被剔除。
major前:
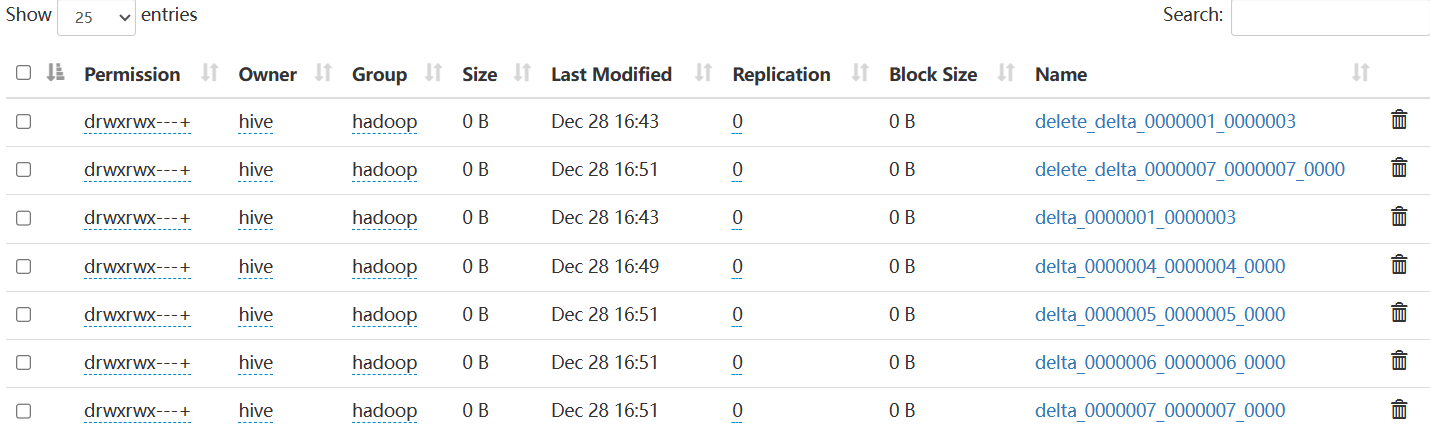
major后:

??需要注意的是,在 Minor 或 Major Compaction 执行之后,原来的文件不会被立刻删除。这是因为删除的动作是在另一个名为 Cleaner 的线程中执行的。因此,表中可能同时存在不同事务 ID 的文件组合,这在读取过程中需要做特殊处理。
有了大致的了解后,是否任意存储格式的表均具有ACID特性?
首先TextFile,默认建表语句中关于事务的配置项:
'transactional'='true', 'transactional_properties'='insert_only',
可以执行insert操作,但是无法执行delete和update,报错:
Error: Error while compiling statement: FAILED: SemanticException [Error 10414]: Attempt to do update or delete on table test.text_table1 that is insert-only transactional (state=42000,code=10414)
尝试修改transactional_properties值为default,但是无法修改:
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Cannot convert an ACID table to non-ACID (state=08S01,code=1)
官网的意思是目前仅支持ORC格式的hive表:
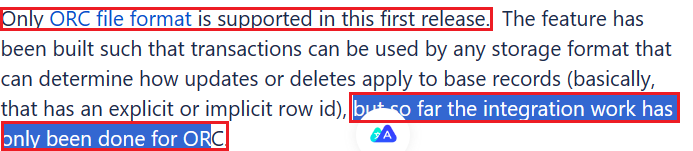
此外Hive ACID还存在一些限制,感兴趣可以进一步了解:
https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#:~:text=SQL%20MERGE%20statement.-,Limitations,-BEGIN%2C%20COMMIT
本博客为学习所记,意在备忘所学过程,故有引用之处,其中参考博客有:
-
深入学习MySQL事务:ACID特性的实现原理https://www.cnblogs.com/kismetv/p/10331633.html
-
实战 | 深入理解 Hive ACID 事务表
https://blog.csdn.net/zjerryj/article/details/91470261
文章来源:https://blog.csdn.net/qq_44540985/article/details/135497406
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!