Flink Flink数据写入Kafka
一、环境准备
flink官方集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.14.6</flink.version>
<spark.version>2.4.3</spark.version>
<hadoop.version>2.8.5</hadoop.version>
<hbase.version>1.4.9</hbase.version>
<hive.version>2.3.5</hive.version>
<java.version>1.8</java.version>
<scala.version>2.11.8</scala.version>
<mysql.version>8.0.22</mysql.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
二、KafkaSink介绍
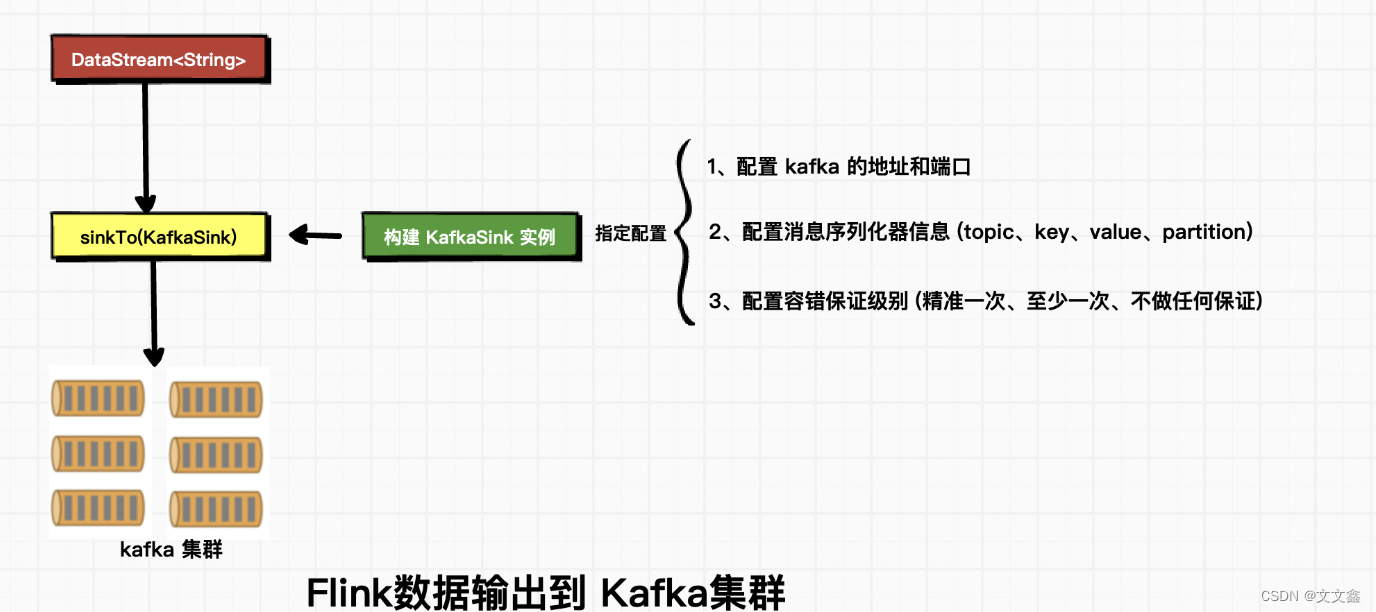
三、正确理解序列化器
什么叫序列化和反序列化?
1.序列化:把对象转换为字节序列的过程称为对象的序列化.
2.反序列化:把字节序列恢复为对象的过程称为对象的反序列化.
序列化器的作用是将flink数据转换成 kafka的ProducerRecord
Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者 Scala 对象;
那么,Flink Kafka Producer 需要知道如何将 Java/Scala 对象转化为二进制数据。
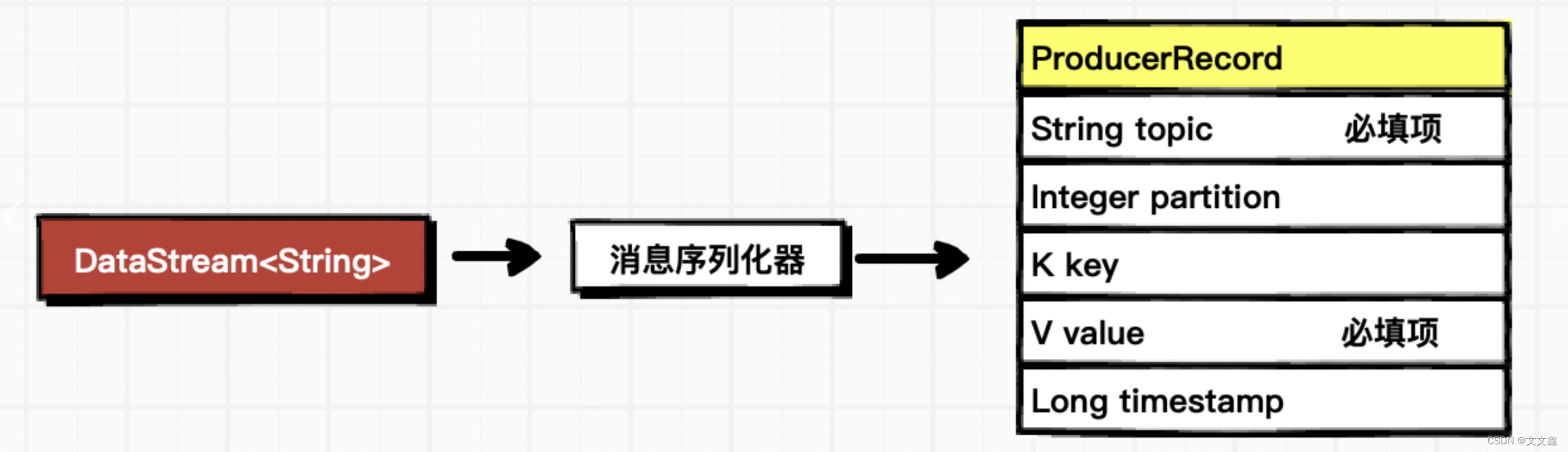
使用预定义的序列化器
将 DataStream 数据转换为 Kafka消息中的value,key为默认值null,timestamp为默认值
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// 指定 kafka 的地址和端口
.setBootstrapServers("localhost:9092")
// 指定序列化器:指定Topic名称、具体的序列化(产生方需要序列化,接收方需要反序列化)
.setRecordSerializer(KafkaRecordSerializationSchema
.<String>builder()
.setTopic("testtopic01")
// 指定value的序列化器
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
源码解析
public <T extends IN> KafkaRecordSerializationSchemaBuilder<T> setValueSerializationSchema(SerializationSchema<T> valueSerializationSchema) {
this.checkValueSerializerNotSet();
KafkaRecordSerializationSchemaBuilder<T> self = this.self();
self.valueSerializationSchema = (SerializationSchema)Preconditions.checkNotNull(valueSerializationSchema);
return self;
}
使用自定义的序列化器
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers("localhost:9092")
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(
new KafkaRecordSerializationSchema<String>() {
...............
}
)
.build();
四、容错保证级别
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)
启用 Flink 的 checkpointing 后,FlinkKafkaProducer 可以提供精确一次的语义保证。
除了启用 Flink 的 checkpointing,你也可以通过将适当的 semantic 参数传递给 FlinkKafkaProducer 来选择三种不同的操作模式:
Semantic.NONE:Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。
Semantic.AT_LEAST_ONCE(默认设置):可以保证不会丢失任何记录(但是记录可能会重复)
Semantic.EXACTLY_ONCE:使用 Kafka 事务提供精确一次语义。无论何时,在使用事务写入 Kafka 时,都要记得为所有消费 Kafka 消息的应用程序设置所需的 isolation.level(read_committed 或 read_uncommitted - 后者是默认值)。
注意事项
Semantic.EXACTLY_ONCE 模式依赖于事务提交的能力。事务提交发生于触发 checkpoint 之前,以及从 checkpoint 恢复之后。如果从 Flink 应用程序崩溃到完全重启的时间超过了 Kafka 的事务超时时间,那么将会有数据丢失(Kafka 会自动丢弃超出超时时间的事务)。考虑到这一点,请根据预期的宕机时间来合理地配置事务超时时间。
默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。此属性不允许为大于其值的 producer 设置事务超时时间。 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时,因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
在 KafkaConsumer 的 read_committed 模式中,任何未结束(既未中止也未完成)的事务将阻塞来自给定 Kafka topic 的未结束事务之后的所有读取数据。 换句话说,在遵循如下一系列事件之后:
用户启动了 transaction1 并使用它写了一些记录
用户启动了 transaction2 并使用它编写了一些其他记录
用户提交了 transaction2
即使 transaction2 中的记录已提交,在提交或中止 transaction1 之前,消费者也不会看到这些记录。这有 2 层含义:
首先,在 Flink 应用程序的正常工作期间,用户可以预料 Kafka 主题中生成的记录的可见性会延迟,相当于已完成 checkpoint 之间的平均时间。
其次,在 Flink 应用程序失败的情况下,此应用程序正在写入的供消费者读取的主题将被阻塞,直到应用程序重新启动或配置的事务超时时间过去后,才恢复正常。此标注仅适用于有多个 agent 或者应用程序写入同一 Kafka 主题的情况。
注意:Semantic.EXACTLY_ONCE 模式为每个 FlinkKafkaProducer 实例使用固定大小的 KafkaProducer 池。每个 checkpoint 使用其中一个 producer。如果并发 checkpoint 的数量超过池的大小,FlinkKafkaProducer 将抛出异常,并导致整个应用程序失败。请合理地配置最大池大小和最大并发 checkpoint 数量。
注意:Semantic.EXACTLY_ONCE 会尽一切可能不留下任何逗留的事务,否则会阻塞其他消费者从这个 Kafka topic 中读取数据。但是,如果 Flink 应用程序在第一次 checkpoint 之前就失败了,那么在重新启动此类应用程序后,系统中不会有先前池大小(pool size)相关的信息。因此,在第一次 checkpoint 完成前对 Flink 应用程序进行缩容,且并发数缩容倍数大于安全系数 FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR 的值的话,是不安全的。同样,在这种情况使用 setTransactionalIdPrefix() 改变 transactional.id 也是不安全的,因为系统也不知道先前使用的 transactional.id 前缀。
五、案例—Flink将Socket数据写入Kafka(精准一次)
注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可
1、开启 checkpoint
2、设置事务前缀
3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟
package com.flink.DataStream.Sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
public class flinkSinkKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
streamExecutionEnvironment.setParallelism(1);
// 如果是精准一次,必须开启 checkpoint
streamExecutionEnvironment.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
DataStreamSource<String> streamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);
/**
* TODO Kafka Sink
* TODO 注意:如果要使用 精准一次 写入 Kafka,需要满足以下条件,缺一不可
* 1、开启 checkpoint
* 2、设置事务前缀
* 3、设置事务超时时间: checkpoint 间隔 < 事务超时时间 < max 的 15 分钟
*/
Properties properties=new Properties();
properties.put("transaction.timeout.ms",10 * 60 * 1000 + "");
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// 指定 kafka 的地址和端口
.setBootstrapServers("localhost:9092")
// 指定序列化器:指定Topic名称、具体的序列化(产生方需要序列化,接收方需要反序列化)
.setRecordSerializer(KafkaRecordSerializationSchema
.<String>builder()
.setTopic("testtopic01")
// 指定value的序列化器
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// 写到 kafka 的一致性级别: 精准一次、至少一次
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 如果是精准一次,必须设置 事务的前缀
.setTransactionalIdPrefix("flinkkafkasink-")
// 如果是精准一次,必须设置 事务超时时间: 大于 checkpoint间隔,小于 max 15 分钟
.setKafkaProducerConfig(properties)
//.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
streamSource.sinkTo(kafkaSink);
streamExecutionEnvironment.execute();
}
}
理解ProduceerConfig配置源码
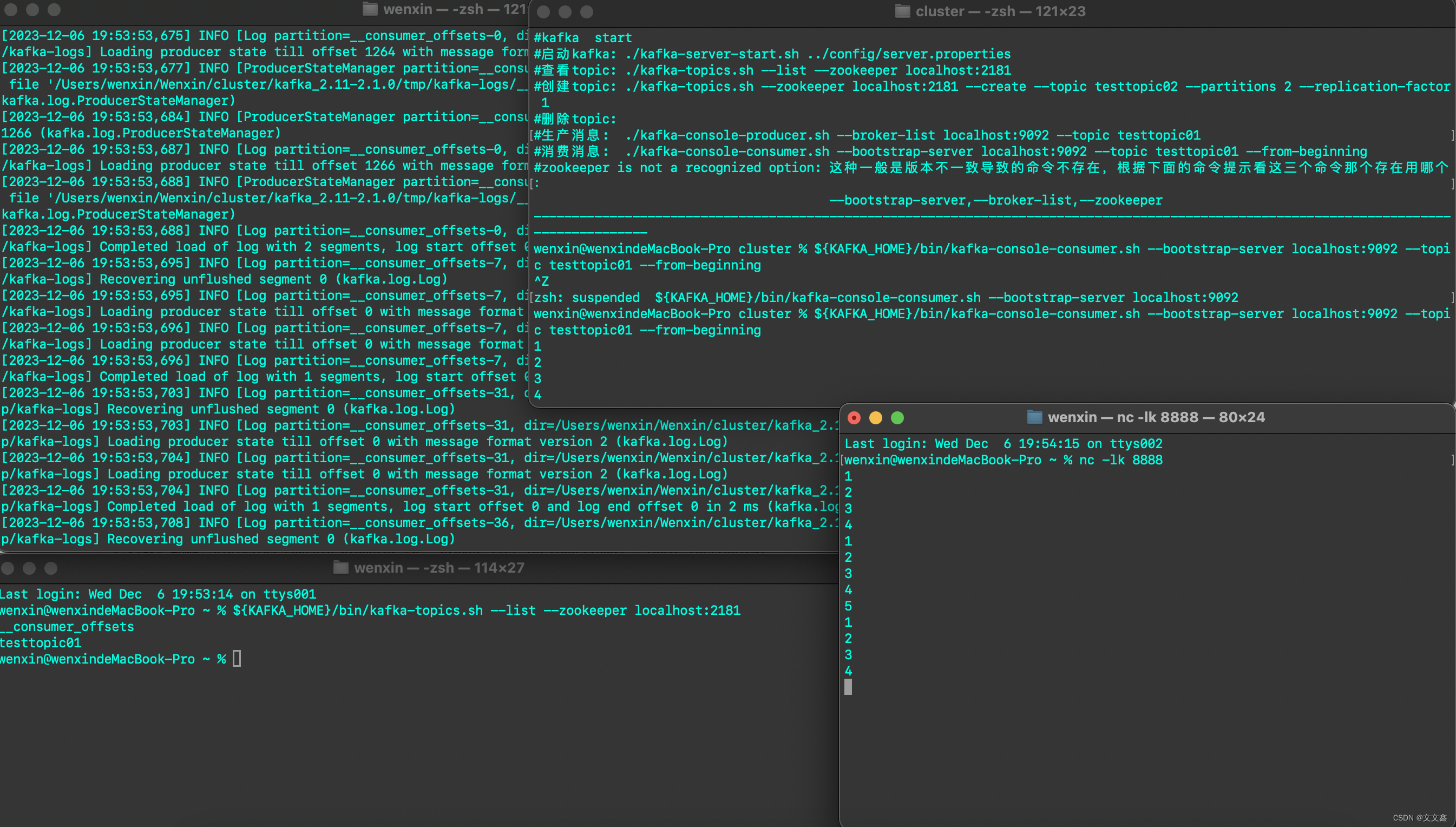
六、启动Zookeeper、Kafka
#启动zookeeper
${ZK_HOME}/bin/zkServer.sh start
#查看zookeeper状态
${ZK_HOME}/bin/zkServer.sh status
#启动kafka
${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties
#查看topic
${KAFKA_HOME}/bin/kafka-topics.sh --list --zookeeper localhost:2181
#创建topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic testtopic02 --partitions 2 --replication-factor 1
#删除topic
${KAFKA_HOME}/bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic testtopic02
#生产消息
${KAFKA_HOME}/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testtopic01
#消费消息
${KAFKA_HOME}/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testtopic01 --from-beginning
通过socket模拟数据写入Flink之后,Flink将数据写入Kafka
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!